
Confluent is a major name in the Data & Analytics industry that I watch over, but I also happen to know the company and its platform extremely well, after utilizing its software for the past few years. It provides essential data capabilities that cross-apply to many, many trends seen across today's modern, globally-spanning, data-driven enterprises.
Any discussion of Confluent has to start at the heart of the company, with Apache Kafka (henceforth just called "Kafka"), the open-source software it authors, supports, and monetizes. If you love MongoDB and/or Elastic as investments, you're also going to love Confluent. It's a company with an open-source data platform, which sells & supports an enhanced enterprise version (adding in additional security, reliability, and maintainability features), as well as, more excitingly, has a SaaS component that provides managed hosting of that platform across the 3 major cloud vendors.
But know that, unlike the products coming from those other companies, Kafka is not a database. Or is it? Understanding the stance that Confluent is taking with Kafka, and how it underpins many trends seen across data-driven enterprises (which is ... every company), is vital to understanding it as an investor.
I had many, many words to say about Confluent and Kafka, so this series is broken into 2 parts. (And this is without even getting into much technical detail of its underlying architecture!) Today, we cover Kafka in part 1, with a subsequent dive into Confluent in part 2. [This post was originally written in my Premium service back in Jun-21 when Confluent was about to IPO. Premium members can read part 2 here.]
What is Kafka?
What Kafka – and subsequently Confluent – are all about is a new paradigm of how to handle data. Kafka is not a database, however – at its core, it is a data streaming application utilized to connect to all of a company's disparate systems (databases, applications, systems, analytic tools, devices), in order to control the flow of data between them.
Kafka allows companies to maintain a giant, reliable (highly-available, fault tolerant) pipeline that can handle a massive amount of data (high performance, at scale). It is a clustered platform that provides data streaming capabilities, allowing for data to flow between all of a company's systems and applications. I like to describe Kafka as a giant river of data, with all the tributaries onboarding more data (multiple incoming streams), storing it briefly inside (a reservoir that can be tapped), until it then all flows outward into other locations to make use of (a water supply to the houses in town). However, unlike water, data can be utilized many times over the course of that journey.
This kind of centralized data pipeline, as Confluent puts it so eloquently it in their S-1, becomes a real-time central nervous system for modern digital enterprises. In fact, you'l hear a lot of fancy phrases in descriptions of Kafka (either from Confluent or the thousands of companies that use it), such as:
- "real-time central nervous system"
- "allows for data in motion"
- "nexus of real-time data"
- "much-needed glue between disparate systems"
- "intelligent connective tissue"
- "centralized data plumbing"
- "backbone of a data platform"
It's clear, as LinkedIn put it in 2015 – if data is the lifeblood of high tech, Apache Kafka is the circulatory system.
So it's ultimately a streaming pipeline, a piece of data infrastructure to be used by companies to corral the flows of their data. But what is that pipeline good for? This is a more difficult concept to truly understand, as Kafka greatly inverts the traditional way of thinking about databases – and understanding this is key to understanding Confluent. The Kafka ecosystem allows for many new ways of thinking about data, and how it flows between systems and applications around the globe.
Centralized data pipeline, across interconnected systems
Kafka is aiming to be the core pipeline of data within an organization. It is for connecting all applications, systems, and data layers into one centralized flow of data. This posture greatly simplifies the web of dependencies that typically happen in software development stacks (i.e. an API might talk to a in-memory cache, plus a back-end relational database, plus interoperate and exchange data with other APIs). Just think about how a company might collect all its operational data (from internal systems, Salesforce, Marketo campaigns, POS systems, supply chains) to put into a data warehouse – Kafka can help centralize all those incoming flows into a massive pipeline, outputting all sources of the data into one (or more!) final destination.
Kafka can help turn a mess of nested dependencies and data flows:
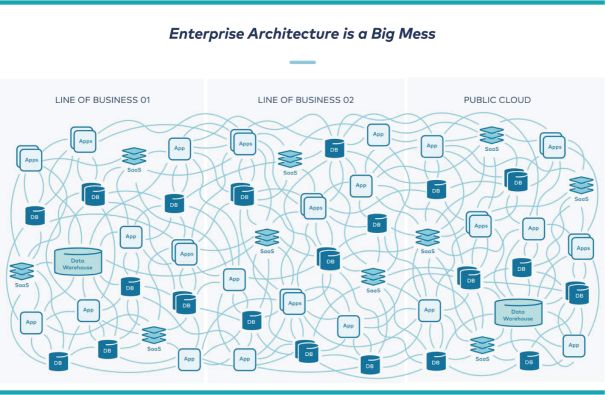
Into this:
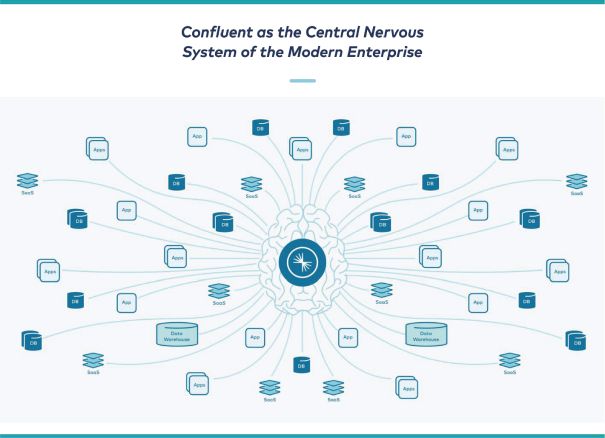
So, at its core, Kafka is a critical piece of data infrastructure that enterprises can use to control and flow data between the various systems and applications. It is highly programmable, with native clients in all major programming languages, plus a REST API as an easier-to-use (but less robust) method of access. Software companies can directly code data producers or consumers easily, directly within their applications and data flows.
But besides its programmability, one critical aspect of Kafka is the huge number of integrations it has with other softwares and systems. It has a high number of interconnection plugins ("connectors"), which allows for connecting Kafka up to a wide variety of input sources of data ("sources") and output destinations for data ("sinks"). To run these connector plugins, a module called Kafka Connect was built, to have a configuration-based method for using and managing these connections & data flows. Kafka standardized a framework for how these integrations occur, so that enterprise software and services would have easy methods for making on- or off-ramps to and from the centralized data pipeline. The open-source community itself also created needed connectors.
Connectors give it the ability to exchange data with a wide variety of infrastructure and SaaS services:
- file-based sources (files, FTP, APIs, HDFS)
- object stores (AWS S3, Azure Blob, Azure Data Lake Storage, GCP Storage)
- data messaging formats (SNMP, JMS, MQTT, Prometheus)
- popular databases (MySQL, PostgreSQL, SQLServer, MongoDB, Oracle, Elasticsearch, and JDBC for any others)
- serverless platforms (AWS Lambda, Azure Functions, GCP Functions)
- observability platforms (Datadog, Splunk, New Relic)
- centralized data stores (Snowflake, AWS DynamoDB, AWS RedShift, Azure Synapse, Azure Cognitive Search, GCP BigQuery, GCP Spanner)
- popular SaaS services (ServiceNow, Salesforce, Zendesk, Github, Jira/Confluent, PagerDuty, Marketo).
- competing message pipeline platforms (RabbitMQ, ActiveMQ, AWS Kinesis, GCP Pub/Sub, Azure PubSub, Azure Event Hubs, Azure Service Bus).
Whew! In short, Kafka interconnects to most everything – and if it doesn't have an out-of-the-box plugin for a particular use case, it can be done programmatically. Some supporting softwares are designed to directly interface with Kafka as well, such as the tools for designing individual data pipelines (Streamsets and Apache Nifi), or the analytical databases (Apache Druid and ClickHouse) that are utilized for analysis over real-time Kafka streams.
Continuous flow of data
In one of its simplest use cases, Kafka is great for turning batch processes into real-time ones. Companies cannot no longer wait for an hourly or nightly process to run, in order to see the results of their actions, how customers are responding, or to manage inventory or supply chains. Businesses have to be able see and to respond instantly to their critical operations and any issues spotted. Operating in real-time is a required feature for today's software-driven companies. Kafka allows for companies to co-mingle batch and real-time processes as needed, on either side of Kafka (the production or the consumption of data) – which greatly allows for companies to transition legacy data flows into real-time ones.
As the S-1 put it:
Several waves of technology innovation have driven this changing role of software. Cloud has re-imagined infrastructure as code, making it easier than ever for developers to build applications. Mobile has extended enormous amounts of computing power to fit in the palms of our hands, making usage of technology ubiquitous in our lives. Meanwhile, machine learning is extending the scope and role of software to new domains and processes.
However, in order to complete this transition, another fundamental wave is required. The operation of the business needs to happen in real-time and cut across infrastructure silos. Organizations can no longer have disconnected applications around the edges of their business with piles of data stored and siloed in separate databases. These sources of data need to integrate in real-time in order to be relevant, and applications need to be able to react continuously to everything happening in the business as it occurs. To accomplish this, businesses need data infrastructure that provides connectivity across the entire organization with real-time flow and processing of data, and the ability to build applications that react and respond to that data flow. As companies increasingly become software, they need a central nervous system that connects all of their disparate software systems, unifying their business and enabling them to react intelligently in real-time.
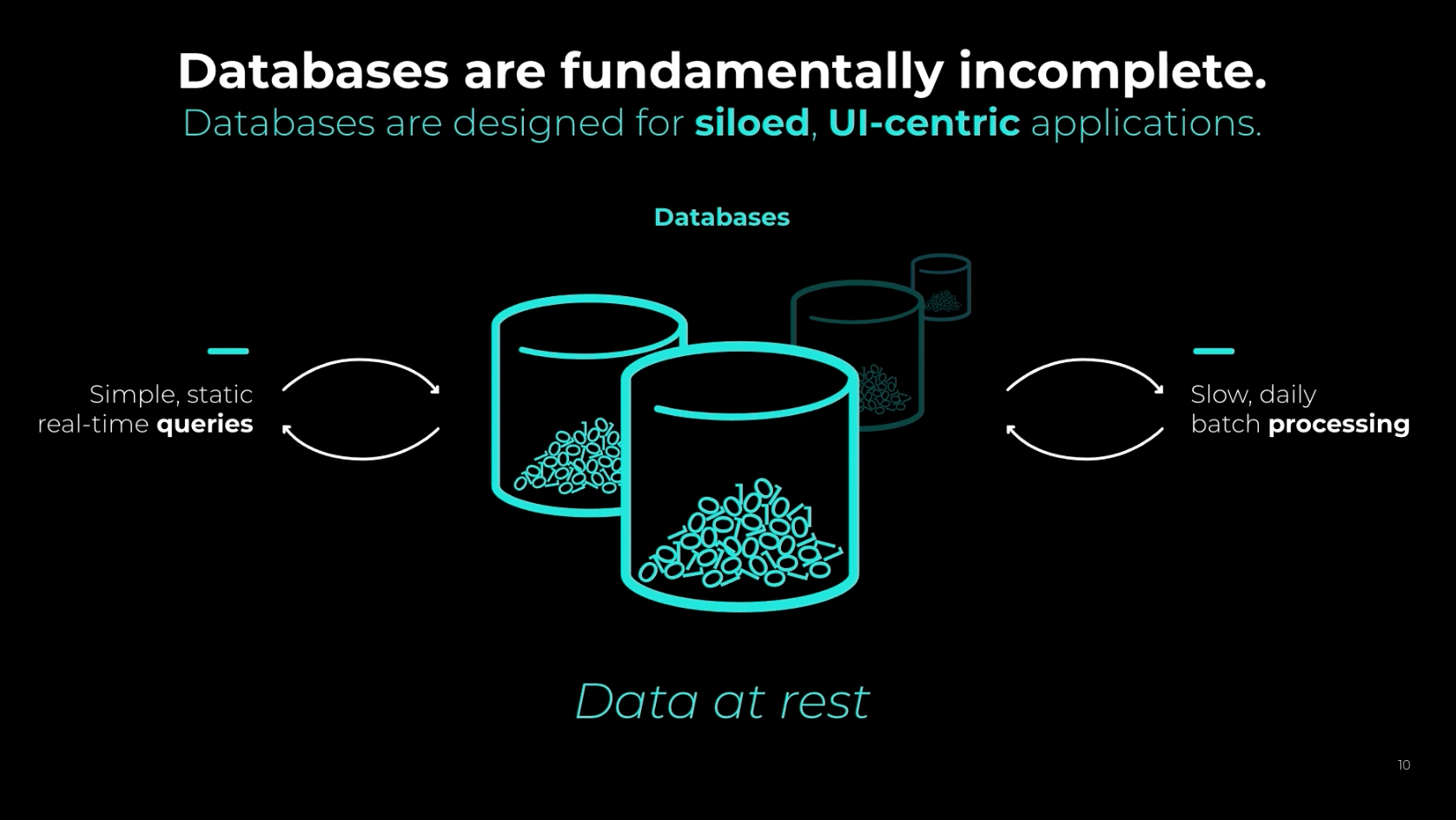
Ultimately, Confluent feels that traditional databases are a reactive source of data (that they call "data at rest"), while Kafka allows for your view over the data to be proactive and in real-time ("data in motion").
Because of this, we believe that it is no longer enough for an organization to innovate based on the current paradigm of capturing data, storing it, and then querying or analyzing it. Organizations need a strategy, and a foundational data platform, to operate their business in real-time based on data as it is being generated in the moment. This idea of “data in motion” is at least as critical to the operations of a company as “data at rest,” and we believe the new generation of winning organizations will be defined by their ability to take action on it.
This is a fundamental paradigm shift and cuts to the heart of how we think about data and architect applications. Data in motion is not just a missing feature in databases, it is a bottoms-up rethinking of the computer science underlying data systems. ... Databases are simply too slow to serve the real-time nature of modern customer experiences and operational needs. Data in motion flips this design 180 degrees. Rather than bringing queries to data at rest, our platform is architected to stream data in motion through the query. This continuous stream makes the data always available and is what fundamentally enables companies to tap into flows of data being generated anywhere in the company and continually process it.
Read that critical bit in there again - rather than bringing queries to data at rest (centralized databases), a platform like Kafka can be streaming the data THROUGH THE QUERY. I must admit, this philosophy might seem a bit antithetical to the rise of Snowflake and data lakes - but it's a powerful message that modern enterprises are taking very seriously. Today's world is too fast paced to always have to collect all the data into centralized data stores before you can then act upon it. The problem is two-fold - globally distributed companies first have to collect a MASSIVE amount of data from disparate locations, and then must attempt to monitor & act upon it in real-time.
Kafka provides vital infrastructure for companies that are collecting, parsing, and acting upon data from around the globe. But let's be clear, it is not going to replace centralized data stores like data warehouses and data lakes - which are much, much easier to interface with and to query, from a data analyst's point of view with their existing analytical tools (Tableau, Power BI, etc). I believe Kafka works best IN TANDEM with data lakehouse services like Snowflake and Databricks. Management will still need the overall 360 degree view that they get from data warehouses and BI tools, and data lakes and data science tools – but many areas of a company's operations can benefit from a real-time view over its streams of data. It depends on the company utilizing these tools to find the best approach to analytics and data flows that best fit their needs, and Kafka seems certain to come up in most data & cloud architecture conversations. Many companies will continue to use data warehouse and data lakes (especially those that want turnkey solutions) - but some will be migrating individual needs more and more to data streaming platforms, especially those with the technical process to best utilize the platform.
Event Streaming
Message queues are used for passing packets of data between systems, such as passing in each row of a CSV file or data table. However, a new paradigm in software emerged where, instead of passing packets of raw data around, applications are starting to think in terms of "events". In a great blog post from 2019, entitled "Every Company is Software", Kafka's creator and main architect (and now Confluent's CEO) Jay Kreps stated:
What is an event? Anything that happens — a user login attempt, a purchase, a change in price, etc. What is an event stream? A continually updating series of events, representing what happened in the past and what is happening now.
Event streams present a very different paradigm for thinking about data from traditional databases. A system built on events no longer passively stores a dataset and waits to receive commands from a UI-driven application. Instead, it is designed to support the flow of data throughout a business and the real-time reaction and processing that happens in response to each event that occurs in the business. This may seem far from the domain of a database, but I’ll argue that the common conception of databases is too narrow for what lies ahead.
Thinking about data as a series of events enables a method of software development known as event-driven programming, where an application is built to react to events. This concept allows for breaking your software up into a set of discrete components, each triggered by events occurring. Each component can do some specific action in response. The components of your application ("event handlers") are triggered by incoming events, such as actions from a user in a UI, or machine-to-machine actions like calling an API endpoint. What event-driven programming allows for is a complete decoupling of your components, where each one is asynchronously handling the event it cares about, and possibly triggering other events in turn, as the workflow needs to separately handle success or failure cases from there.
So instead of a tightly-integrated application handling every action in one massive, inter-twined code base, you can now break the application up into specific decoupled components. Think of the front-end events that might occur in an e-commerce shopping app – a user might browse the store listing, search for a particular item, add an item to the cart, adjust quantities of an item, remove an item, finalize & approve the order, input their name and address information, then submit payment. These actions may internally trigger back-end events, such as looking up searches, validating inventory, processing the payment, sending a receipt via email, adjusting the inventory counts, and finally, shipping the items.
This paradigm shift in development led to the rise of microservices (a design method of breaking up your monolithic app into discrete components that can be triggered by events), and serverless functions (a way to run microservices as an on-demand, self-contained function running on hosted infrastructure). Event-based application workflows can be thought of as a flowchart, with each process or decision point in the flow a separate service or function. Programming in this way can become highly complex (as you have to manage & deploy many individual components, instead of one monolithic app), so it needs other systems to help manage how the application workflows interact across those components. Event streaming platforms like Kafka can help provide the connective fabric behind microservices and serverless functions, controlling how the services communicate & interoperate with each other.
Data Changes as Events
The issue with using traditional databases for real-time streaming is that they are built around keeping a representative set of the data as of that point in time. For instance, databases allow update and delete operations that change the underlying data, so that today's query cannot see the data's state as it existed before that change.
Kafka wants users to re-envision how companies think about traditional databases. Instead of only representing a set moment of time, it too can be thought as a stream of events. The database connectors listed above are provided through the Debezium open-source library, which is built around a process known as Change Data Capture (CDC). This treats a database as a continually updating source of data changes (events!), instead of having the database reflect a set moment in time. These database connectors allow for streaming any ongoing data changes out in real-time, be it data inserts (new records), updates (changes to an existing record), or deletes (removing a record). With CDC connectors, you can now treat any database, either relational and NoSQL, as an event stream that can be tracked in Kafka.
CDC is a concept that traditional DBAs might not fully understand the importance of. The actions that are changing the database are now thought of as separate events – a customer record was added, an address was changed, a phone number was added, and possibly the entire record was later deleted. Instead of using the database as a query engine, the CDC connector is now sitting on its underlying transaction log, allowing it to stream events, which can serve as a "playback" of the events that changed the data. This allows you to see all of the data updates and deletes which are normally not exposed through a SQL query, where you can only query for the record's current state - you cannot query it for prior data before an update, or for deleted data.
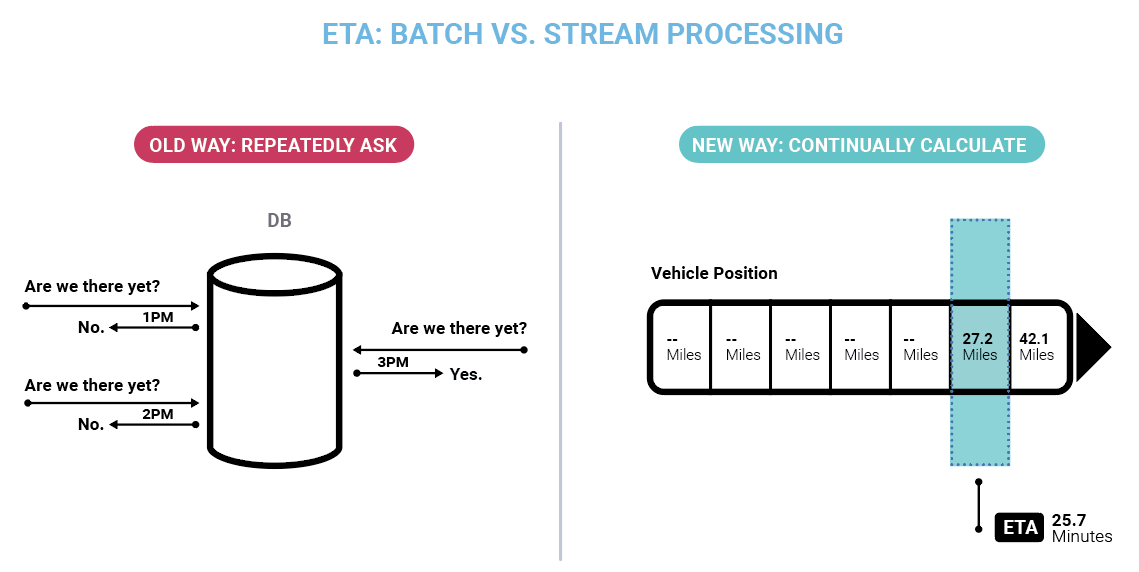
But most importantly, CDC serves as a real-time stream of the data changes appearing in that database. Data engineers making these data flows no longer have to continuously query the database to extract new data out (what I call "long polling" - keeping a high water mark to extract any new records out on each subsequent poll), and can now cleanly extract out the updates and delete actions. It is all now just events.
Stream Processing
So Kafka is great as passing massive amounts of events or data changes in real-time, where other systems can then act upon it, and even generate streams of their own. Several open-source stream processing engines have sprouted up from the Hadoop ecosystem that work over Kafka, like Apache Spark, Apache Storm, and Apache Flink.
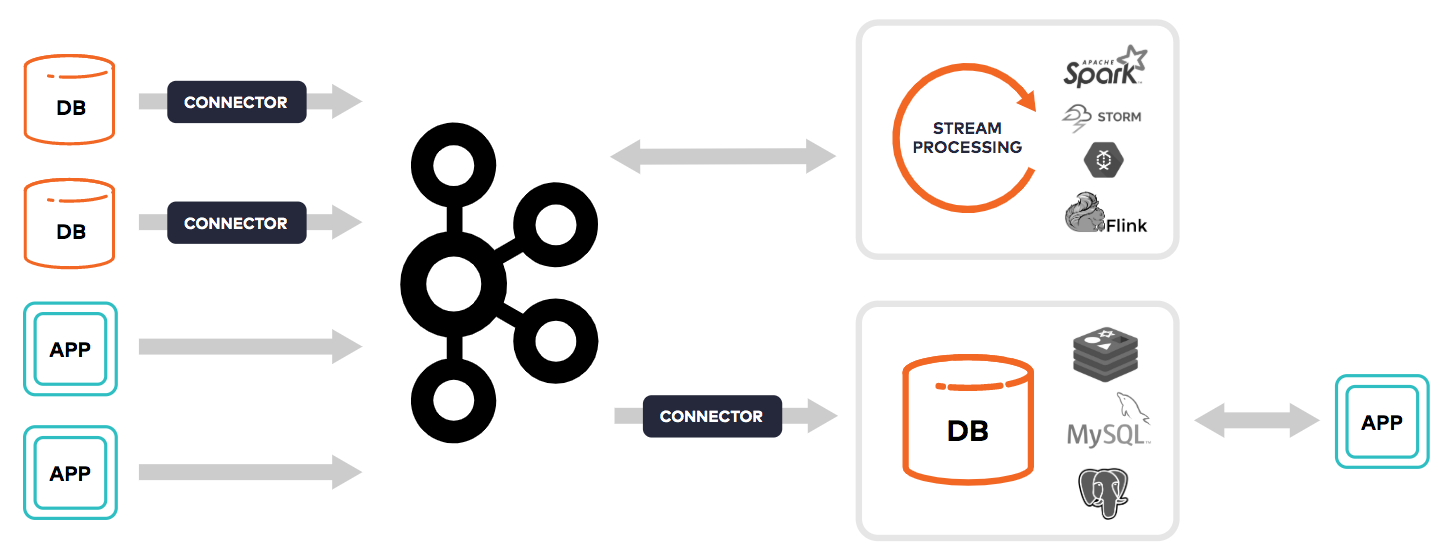
But Kafka wanted a better method. A module called Kafka Streams was eventually created to then act upon that data inline – inside the platform – instead of having complex and harder to use outside tools needed. Using Kafka Streams, users could now create microservices directly inside Kafka, with the input and output data all stored in Kafka's data streams, and use Kafka's exactly-once semantics for transaction processing.
Confluent realized that to truly be an "event streaming platform" meant that the stream processing and databases must join together. From that same 2019 blog post, from the mind of Jay Kreps:
What is needed is a real-time data platform that incorporates the full storage and query processing capabilities of a database into a modern, horizontally scalable, data platform. And the needs for this platform are more than just simply reading and writing to these streams of events. An event stream is not just a transient, lossy spray of data about the things happening now — it is the full, reliable, persistent record of what has happened in the business going from past to present. To fully harness event streams, a real-time data platform for storing, querying, processing, and transforming these streams is required, not just a “dumb pipe” of transient event data.
Combining the storage and processing capabilities of a database with real-time data might seem a bit odd. If we think of a database as a kind of container that holds a pile of passive data, then event streams might seem quite far from the domain of databases. But the idea of stream processing turns this on its head. What if we treat the stream of everything that is happening in a company as “data” and allow continuous “queries” that process, respond, and react to it? This leads to a fundamentally different framing of what a database can be.
Confluent ultimately created another open-source module over Kafka Streams to allow database-like features within Kafka. Originally called KSQL, it was later renamed to ksqlDB. This module gives the ability to query data streams in real-time, simply by using the database-friendly SQL language. Suddenly, Kafka could serve as a real-time database, using the data streams as the storage, and ksqlDB as the compute.
For the announcement post for KSQL:
So what KSQL runs are continuous queries — transformations that run continuously as new data passes through them — on streams of data in Kafka topics. In contrast, queries over a relational database are one-time queries — run once to completion over a data set — as in a SELECT statement on finite rows in a database.
ksqlDB allows performing 2 types of queries over real-time data streams. Pull queries allow for SQL queries over a snapshot-in-time of the data (a materialized view over a window of time). Push queries allow for SQL queries to receive the raw stream of data back, as it arrives. From the ksqlDB website:
The idea is that [ksqlDB] can offer one SQL query language to work with both streams of events (asynchronicity) and point-in-time state (synchronicity).
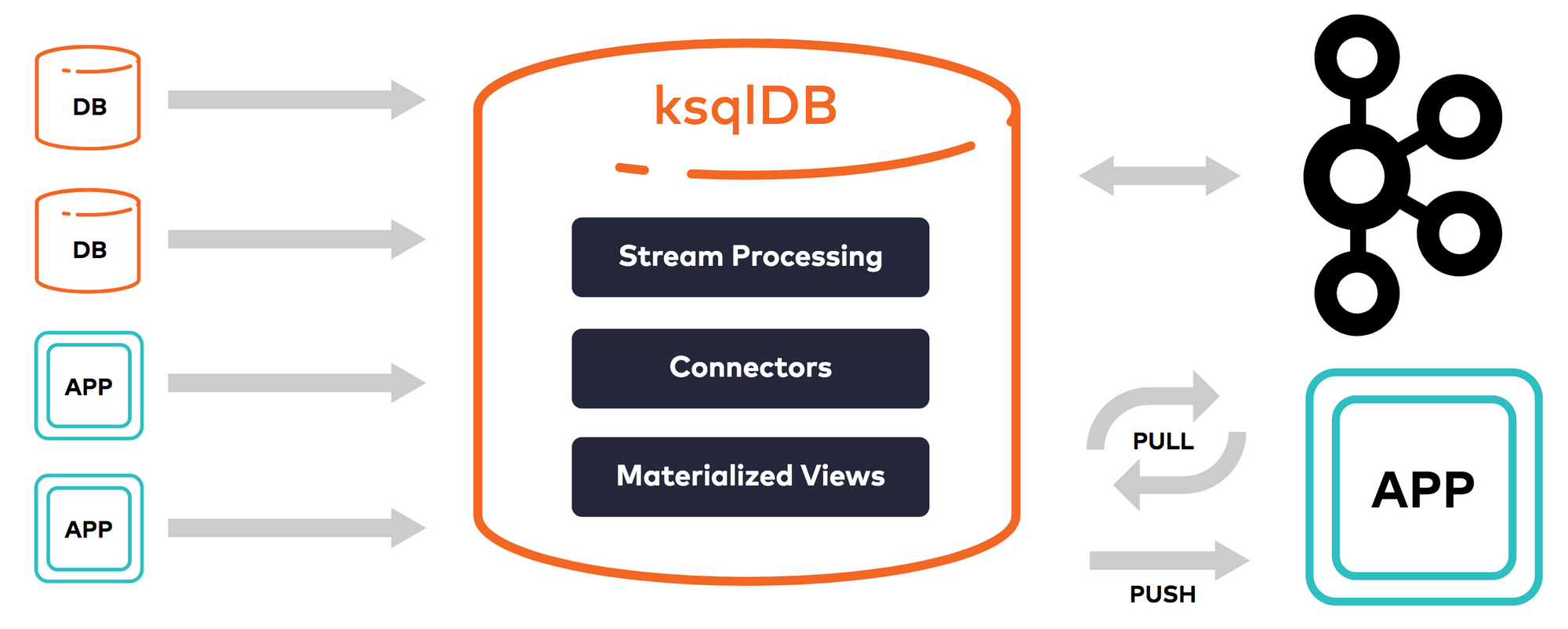
These features open up 3 use cases for ksqlDB:
- Materialized Cache (or Materialized View) = Creates a snapshot-in-time of data from a stream, which can be further enriched from other streams or from other systems (via connectors), e.g. do lookups of customer data from the customer ID. The cache is incrementally updated behind-the-scenes, in real-time, from updates arriving in the event stream. Great for getting real-time views over operational metrics.
- Streaming ETL pipelines = Manipulate in-transit data with data from other streams or from other systems (via connectors), to enrich, clean, or transform the data in real-time. Examples include stripping out PII, doing data joins across streams, or pre-aggregating data (greatly reducing the amount of end data), such as rolling up statistics over windows of time. Great for log aggregation or real-time data enrichment.
- Inline Event-driven Microservices = Trigger changes based on observed patterns of events in a stream. Monitor application or business behaviors, and generate custom metrics off of raw events. Can generate new events from analyzing a real-time stream, such as low inventory warnings or triggering a security notice. Great for real-time monitoring & analytics, like for security and anomaly detection.
Stream processing is where Kafka truly shines over traditional pub-sub data streaming platforms.
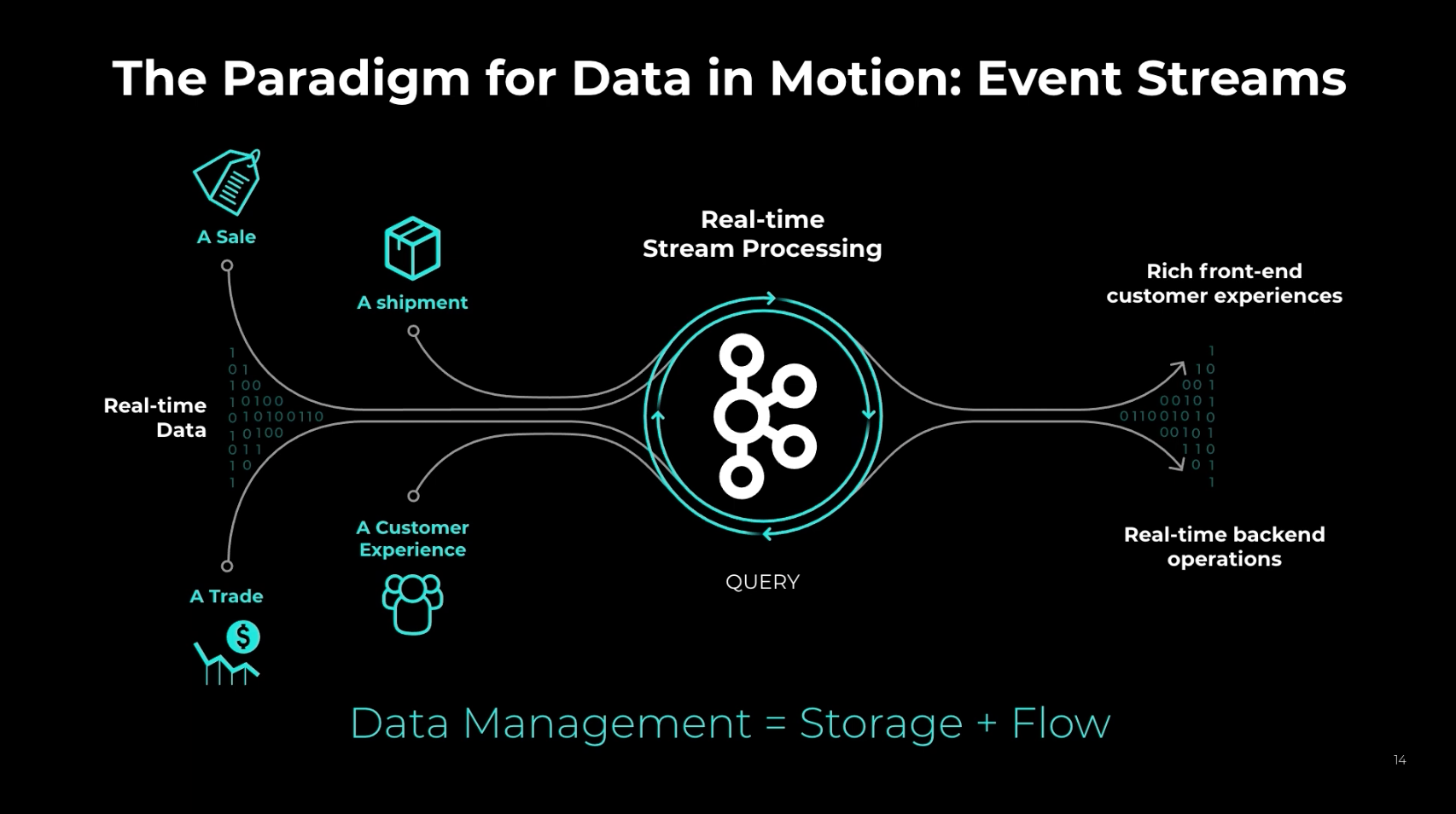
ksqlDB's website explains their stream processing concepts in more in depth:
To be productive, you need some way of deriving new streams of events from existing ones. Stream processing scratches that itch. It’s a paradigm of programming that exposes a model for working with groups of events as if they were in-memory collections.
If you’re new to the world of stream processing, everything might seem upside-down. In a traditional database, you execute queries that run from scratch on every invocation and return their complete result set. You can think of it like this: queries have an active role, while data has a passive role. In the traditional world, data waits to be acted upon.
With stream processing, the flow control is inverted. Instead, the data becomes active and flows through a perpetually running query. Each time new data arrives, the query incrementally evaluates its result, efficiently recomputing the current state of the world.
This is a fully asynchronous flow in which Kafka truly shines. Consider what it would be like if you attempted this with a normal database: you’d be able to query the data, but you'd have a weakened ability to natively process streams of data as they arrive, or subscribe to changes as they occur.
As a quick aside, there is another type of database that pairs very well with Kafka. Analytical (columnar) databases like Apache Druid and ClickHouse are built to allow near real-time analytical queries over Kafka streams & large quantities of historical data. They provide a SQL query interface over an incoming stream of data, circumventing the need for using ksqlDB. However, these systems keep an indexed copy of data separate from Kafka, so a difference over those platforms is the fact that ksqlDB does not require a separate copy of the data.
Apache Kafka
Let's step back and review. Apache Kafka was originally developed at LinkedIn for its data pipelining needs, and was subsequently open sourced in early 2011. It was authored by Jay Kreps, Neha Narkhede, & Jun Rao, who all left LinkedIn to start Confluent in 2014.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
There are plenty of technical terms in Kafka's architecture, but to boil it all down, Kafka is essentially a clustered, highly-available, fault-tolerant publish-subscribe (pub-sub) message queue. What this means is that is that one or more producers of data can publish "messages" (records or events) to a variety of "topics" (tables) in a cluster. Kafka retains the data in each topic for a set period of time, which could even be "forever". Eventually, one or more consumers of data can subscribe to those topics and receive any new messages since it last connected (batch mode) or can continuously receive new data flowing in (real-time mode). Those consumers can act upon or store the message, or even generate more messages in response, to pass things on to other systems.
Kafka's strengths are:
- High throughput (distributed cluster, whose underlying distributed, write-only architecture allows for a huge volume of data to be streamed in)
- Persistence (saves data for set period of time, allowing for asynchronous flows)
- Scalability (elastic, meaning cluster can easily scale up as needed)
- Fault-tolerant (distributed cluster that is highly-available, with data replication to make it resilient to failure)
What all this means is that Kafka is fantastic at handling the challenging V's of big data, easily handling data at velocity (high volume), volume (massive scale), and variety (can handle any serializable format, over a wide variety of interconnected sources and destinations).
Usage
So what is a Kafka used for? Unsurprisingly, this data streaming platform has a huge number of possibilities – and once a company starts using it for one data need, they typically want to start using it for all the other data needs in their company.
- Data Movement - data replication & ETL, across platforms or clouds
- Message queue - passing raw data between applications
- Event streams - tracking triggered events or data changes
- Service bus - messaging backbone between microservices
- Logging & Telemetry - pushing measurements out, asynchronously
- Transaction processing - allows for exactly-once semantics
- Data archival - push data to external storage
- Event processing - feed data into real-time query and analytical systems
These features translate into some specific trends that Kafka is very appropriate for.
Bridge to Cloud, Hybrid or Multi-cloud Scenarios
Users can have more than one cluster, to interconnect across on-prem, hybrid, or cloud environments, in order to replicate or share data between them. Integrates with a wide variety of serverless, storage, and data services across the 3 major cloud vendors and SaaS providers. Allows for instant connectivity regardless of environment, at infinite scale.
Messaging modernization
Can be used for large scale messaging, stream processing, or operational alerting & reporting. Can replace traditional message queues, enterprise service buses, or pub-sub systems. Integrates with other major messaging platforms, to enable cross-platform communications.
Streaming ETL
Turn batch ETL processes into real-time streams. Can be used for data movement, including enrichment, cleaning, or processing while in transit. Integrates with a wide variety of inputs and outputs.
Log Aggregation
Capture system and application log and metric data into a single centralized pipeline. Transmit them asynchronously, so that the performance of the underlying system or application is not affected. Aggregate and transform the data in transit, reducing the overall size of the end data. Integrates with a wide variety of observability platforms (Datadog, Splunk, New Relic), and for deep storage, with object storage across the 3 major cloud vendors.
SIEM Optimization
Break down silos, via integration with a wide variety of systems and services. Aggregate, filter, or transform data in transit, reducing the overall size of the end data. Export the centralized stream of security data into a wide variety of SIEM platforms (Elasticsearch, Datadog, Splunk), and even SOAR systems that automate response. Turn batch processes into real-time anomaly and threat detection, using stream processing capabilities.
Fraud Detection
Create analytical capabilities over real-time event streams for fraud detection and risk analysis. Can integrate with Apache Spark Streaming or any number of open-source stream processing tools, or perform the analytics inline with ksqlDB stream processing. Gain a real-time vision into patterns of fraud, abuse, spam, or other bad behavior.
Event-driven microservices
Serves as the backbone for event streaming over microservices. Integrates with serverless engines and storage across the 3 major cloud vendors. But besides input handling from an event stream, also helps with output handling, tying microservices into other data flows around log aggregation, ETL, SIEM, or real-time analytics.
Internet of Things
Handles the enormous flow of incoming data from dispersed IoT devices (POS systems, cameras, sensors, smart buildings/cities, connected vehicles). Bi-directional data flows can push events back into operational technology (OT) control systems. Transform, filter or enrich the data in transit, reducing the overall size of the end data. Derive real-time insights via stream processing. Operate globally, across multiple cloud environments.
Customer or Operations 360
Provides a centralized location for all customer data to flow through, eliminating data silos. Integrates with a wide variety of customer-oriented services, such as Salesforce, ServiceNow, Marketo, and Zendesk, as well as operational databases and services. Derive real-time insights over customers or operations via stream processing. Ensure software processes are working, with real-time view over system & application metrics. Have better supply chain & inventory management with a unified view. Ensure inventory is updated in real-time, across omni-channel environments.
Components
- A wide variety of open source connectors are available. The ones under "Community" are open-source, but provided under a separate Confluent Community License. Confluent has a searchable hub to list all connectors.
- Kafka Connect is the configuration-based tool for setting up connectors and running data flows.
- Kafka Streams allows for building microservices inline in Kafka, directly over the Kafka streams it uses for input and output.
- ksqlDB is a separate open-source project built over Kafka Streams, which creates a SQL interface to allow real-time queries over data or be an analytical processor.
Other modules provided by Confluent, again provided under its separate Confluent Community License [more on the licensing in the next post]:
- Supported native clients for a wide variety of languages, in order to produce or consume messages directly from your applications.
- REST API, for connecting other applications w/o a native client, in order to produce or consume messages.
- Schema Registry, which allows for enforcing a consistent format & serialization of data, when producing or consuming it to a topic.
I drew up this flow chart (in a prior life as a data architect), to explain the Kafka ecosystem:
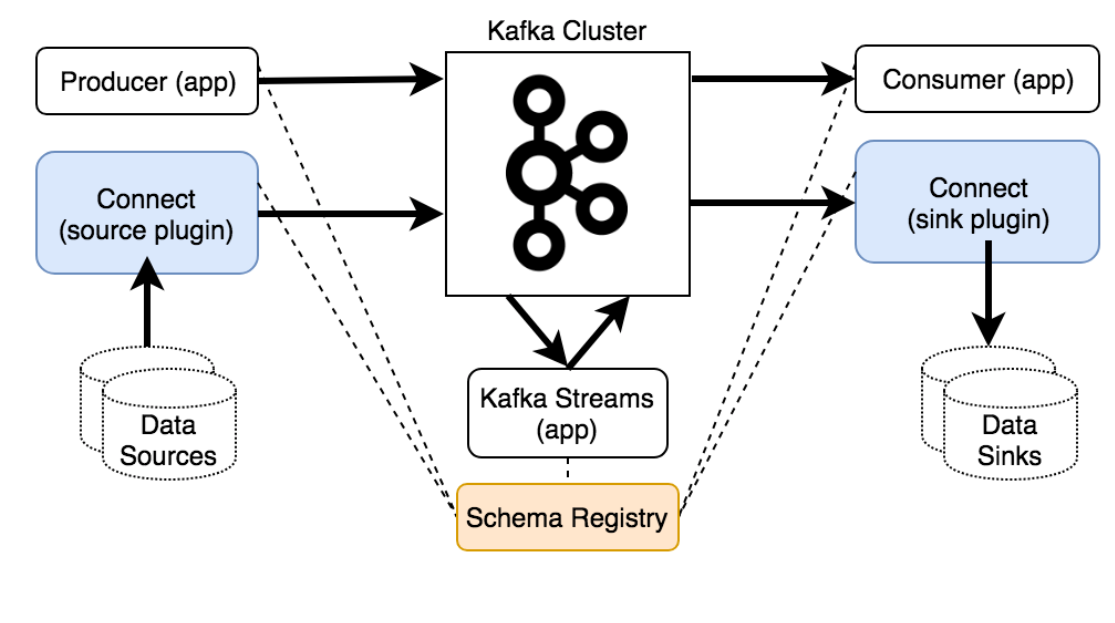
If you want a better interface into the data flows in and out of Kafka data streams (the minor streams into the major river), other tools exist beyond Kafka Connect, with better user interfaces over creating and managing the on- and off-ramps of data from the centralized pipeline. Streamsets and Apache Nifi are two major ones that make continuous data pipelines easy.
Who uses it?
All this has lead Apache Kafka to be an EXTREMELY successful open source software. 80% of Fortune 100 companies utilize it, and over 70% of the Fortune 500. It is used by:
- 10/10 Largest insurance companies
- 10/10 Largest manufacturing companies
- 10/10 Largest information technology and services companies
- 8/10 Largest telecommunications companies
- 8/10 Largest transportation companies
- 7/10 Largest retail companies
- 7/10 Largest banks and finance companies
- 6/10 Largest energy and utilities organizations
There are thousands of modern data-driven companies utilizing Kafka, including: Grab, NYTimes, Airbnb, Bandwidth, Walmart, Nuuly, Barclays, Box, Cloudflare, Slack, Alibaba, KAYAK, Coursera, Robinhood, Cisco, Spotify, Datadog, Etsy, Uber, Foursquare, Hotels.com, LinkedIn, Mozilla, Netflix, Oracle, New Relic, Paypal, Square, Booking.com, Ancestry, Criteo, Udemy, Shopify, Adidas, Tencent, Trivago, Twitter, Microsoft, Intuit, Goldman Sachs, Target, BlaBlaCar, Intuit, Digital Ocean, Hubspot, Agoda, Upwork, Lumosity, MailChimp, Indeed, Expedia... on and on.
Nearly every high-tech company out there utilizes or support Kafka, including many of the companies I follow on this blog. Some examples:
- LinkedIn wrote in 2019 on how it uses Kafka, processing 7T messages daily across 100 clusters.
Kafka is used extensively throughout our software stack, powering use cases like activity tracking, message exchanges, metric gathering, and more. We maintain over 100 Kafka clusters with more than 4,000 brokers, which serve more than 100,000 topics and 7 million partitions. The total number of messages handled by LinkedIn’s Kafka deployments recently surpassed 7 trillion per day.
- Zscaler has mentioned Kafka and Kafka Streams as part of their stack, per a developer job listing.
- Datadog showed us in 2019 that they make heavy use of Kafka, using 40 clusters to handle trillions of data points daily across their globally distributed infrastructure. Also, they have plugins on their observability platform to help companies monitor their Kafka infrastructure.
- CrowdStrike wrote in 2020 on how they use Kafka as a vital part of their cybersecurity infrastructure, ingesting over 500B events a day - trillions per week - in real-time.
At CrowdStrike, we use Kafka to manage more than 500 billion events a day that come from sensors all over the world. That equates to a processing time of just a few milliseconds per event. Our approach of using concurrency and error handling — which helps us avoid mass multiple failures — is incredibly important to the overall performance of our system and our customers’ security.
- Netflix wrote in 2020 on the technical details of how they utilize Kafka to drive their microservice-oriented stack.
- Cloudflare has blogged repeatedly about its extensive use of Kafka across its globally distributed stack. In 2016, they mentioned using Kafka to monitor & log HTTP and DNS requests across their stack. In 2018, in a post detailing why they switched to ClickHouse for streaming analytics, that their large Kafka cluster was handling 8.5M events per second. Around that time, they also detailed the technical specifics of how they were improving the performance of their Kafka clusters by experimenting with compression methods. By 2020, they showed that their raw logs were ingesting 360TB per day via Kafka.
- Snowflake developed a Kafka connector to be able to directly import data streams into their data platform, through their Snowpipe importer tool.
Competition
Competing platforms exist against the open-source Kafka platform. Traditional messaging platforms, like RabbitMQ and ActiveMQ, still compete for messaging.
Apache Pulsar is the main open-source competing platform with similar functionality. It is a pub/sub data pipelining platform that was originally created at Yahoo, though was built with a slightly different purpose and architecture. It also added in stream processing similar to Kafka Streams, called Pulsar Functions. It is utilized by companies like Tencent, Overstock, Verizon, Mercado Libre, Nutanix, and Splunk. In 2019, the original developers formed StreamNative, as the enterprise company around maintaining & supporting Pulsar, along with a SaaS service around managed hosting.
Part 2, covering how Confluent is monetizing its open source platform, is available here [premium post].
Add'l Reading
My friend Peter at Software Stack Investing wrote a lengthly article outlining the various types of transactional data systems, which included a section on event streaming systems and, in particular, Kafka.
If you want more insight into the technical prowess of Kafka creator Jay Kreps (now Confluent founder and CEO), see his 2013 post on reimagining databases for real-time. It was written while he was still at LinkedIn, giving a vision into the underlying thought process he had in creating Kafka. This post later turned into a book, "I Heart Logs", that can be downloaded from Confluent.
Jay Kreps also had a great blog post from 2019 entitled "Every Company is Software" that I quoted from heavily. Highly recommended to really get where he and Confluent are coming from, and Confluent clearly borrowed from it heavily for the descriptive language about the company's stance in the S-1.
He also had a blog post in 2016 on why Confluent created Kafka Streams, and how its stance differs from other stream processing systems. Then founder Neha Narkhede had a blog post in 2017 announcing KSQL (now ksqlDB), and what it was meant to solve. Jay followed that up with a blog post in 2019 when they expanded its features and renamed it into ksqlDB, further refining what it is capable of.
If you want a more technical view into what is under the hood in Kafka and the underlying concepts involved, this intro video from Confluent is helpful. And it's always nice to listen to the dulcimer tones of Tim Berglund's voice – who, as Senior Director of Developer Experience at Confluent, is a very helpful fellow to know, if you are a developer with questions.
This post is from June 2021, when I covered Confluent right before it went public via IPO. Sign up for Premium if you want more coverage like this (like the pending HashiCorp IPO).
- muji