
AI! AI! AI! (Sing it aloud, like you are in a mariachi band singing "Cielito Lindo".)
A few rising forms of AI have dominated the news lately, so it finally comes time to dive into AI/ML way more heavily in this service. I recently had an AI Week here at HHHYPERGROWTH Premium, which had 3 pieces around AI/ML.
- First was a primer on the layers of AI, to understand what is behind this new round of Generative AI. This is today's piece, to help set the stage and define the terminology used.
- I then had a look at the ramifications of Generative AI through an investment lens, including the impacts on companies/industries I follow and what areas seem appealing.
- Finally, I dove into the rise of OpenAI (maker of DALL-E & ChatGPT) and where GPT is going (integration and automation). Also, how Microsoft is adopting GPT across Azure and its enterprise software lines (including in BI, developer, and security workflows), with impacts rippling across all industries I follow.
Let's dive a bit deeper into the various types of AI, and what is powering this new generation of Generative AI that is advancing AI to the next level of public acceptance.
- ML & Neural Networks are scaling up in potential due to the cloud unlocking the ability to scale, advancements in hardware (GPUs and specialized chips), advancements in ML models (Transformers, GANs, Diffusion), and open-source collaboration.
- These have led to a new wave of Generative AI advancements like text-to-image engines and LLMs. These forms are highly visible and are directly exposing AI to the masses, exponentially driving up the hype.
- Transformers and self-attention (weighing data with context) are driving huge advancements in text understanding, summation, and generation.
- Recent advancements in Large Language Models (LLMs) have and have garnered a huge amount of interest, to use them as an interactive virtual assistant for research and writing.
Also, this space is not only difficult to understand but is also constantly evolving. Please let me know if I missed something vital by replying to this email – or to pass along your take or interesting info.
The assumption in this post is that you know nothing to very little about the internals of AI. This post is light on links & investing, to instead explore a few layers of the technology (and just a touch of the technical jargon) to give you a base of knowledge on Generative AI and LLMs. This also hopefully allows you to explore this topic yourself further, so you can halfway understand a blog post or keynote from OpenAI, NVIDIA, or Google.
AI/ML
AI is such a loose term, a magical word that simply means some type of mathematically-driven black box. It is generally thought of as a compute engine that can do a task at or better than a human can, driven by a "brain" (AI engine) making decisions. Essentially, AI is a bunch of inner mathematical algorithms that interconnect & combine into one big algorithm (the overall AI model). These take an input, do logic (the black box), and send back an output.
At the highest level, AI has thus far been Artificial Narrow Intelligence (ANI), a weaker form of AI that is honed to complete a specific task. As seen over the past few months, we are quickly approaching Artificial General Intelligence (AGI), a stronger form of AI that can perform a wider range of tasks, and can think abstractly and adapt. AGI is the holy grail of many an AI researcher.
Today, AI takes a lot of forms, such as Machine Learning (learning from the past to predict the future), Computer Vision (identifying structure in video or imagery), Speech-to-Text/Text-to-Speech (converting audio to text and vice versa), Expert Systems (highly honed decision engines), and Robotics (controlling the real world). I generally sum up all this as "AI/ML" in order to include both sides of the equation (and mirror the duality of other related terms, such as structured vs unstructured data, or supervised vs unsupervised learning). We're going to focus mostly on the ML side here.
There have been a number of accelerating advancements over the past few years from:
- A massive scaling up of compute and parallelization (thanks to cloud hyperscalers, GPUs, and other specialized AI/ML chips), which in turn increases the amount of training data that can be processed while massively speeding up the training time. This leads to larger models, which increases the overall complexity of its decisions and the dimensionality of the data it can handle.
- AI is a research-driven disciple as new models are conceived of and tested, and new methods are frequently replacing the old as a "step up" of capabilities. New advancements in ML modeling (Transformers, GANs, Diffusion) have not only greatly improved the capabilities and performance, but have also scaled up the parallelism – allowing models to train over data all at once instead of linearly.
- Data science is becoming democratized, between sharable open-source models, automated workflows (AutoML), and wider collaboration platforms (like HuggingFace, a repository of open-source models).
These all combine into the rapid advancement we are now seeing out in the open. Cutting-edge models are iterating and improving quickly, and are being combined and used in novel ways. AI engines are also becoming multi-modal, able to work with more than one format (text, image, video, audio, etc). This is all driving a lot of "sudden" excitement about AI (a decade of building up capabilities that seemingly sprung all at once).
Unfortunately for us investors, these latest advancements in Generative AI and chat-driven LLMs are more public (consumer-facing) than most other AI advancements happening, so the hype cycle around all things "AI" has taken off lately. [NVIDIA was up +90% YTD when I wrote this originally, and is now +172% on their surprise Q2 guide of +52% seq growth. Yow!] Beyond Generative AIs, I'd also throw EV-based autonomous driving into this consumer-facing bucket, which had a lot of hype over the last few years as well, which turned into continually unfulfilled promises. It is worth having some caution with AI, but know that the hype is real, and the potential of these cutting-edge AI models is palpable. At a minimum, we are at the precipice of a new era in productivity boosts from virtual assistance and automation. But as these engines mature, combine, and integrate with others more, it suddenly feels that AGI is on our doorstep.
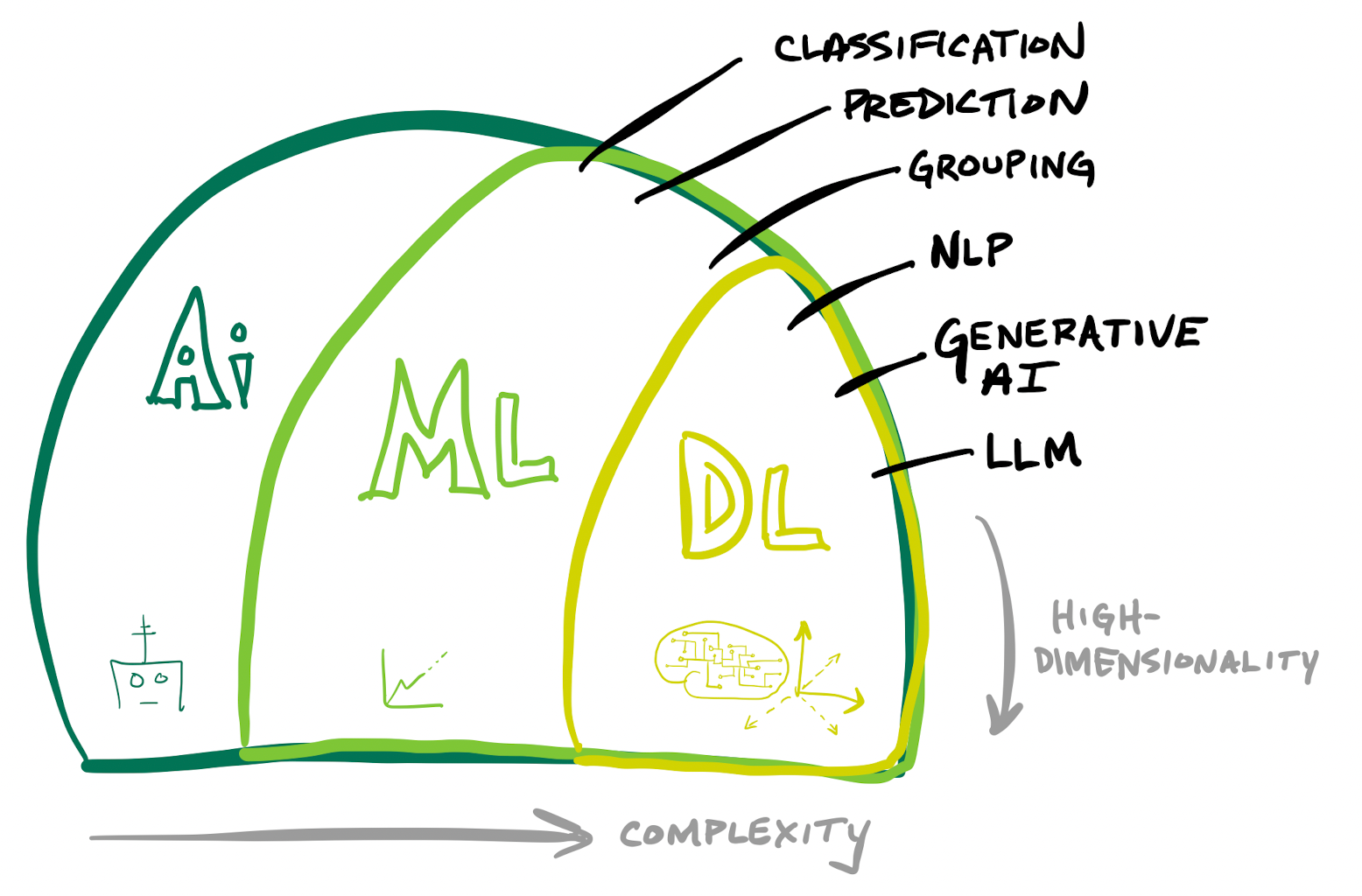
ML
ML is the subset of AI that is trained on past historical data in order to make decisions or predict outcomes. In general, ML processes a lot of data upfront in a training process, analyzing it to determine patterns within it in order to derive future predictions. With the rise of better models, honed hardware (GPUs and specialized chips from hyperscalers), and continually improving scale & performance from the cloud hyperscalers, the potential of ML is now heavily scaling up. ML models can make decisions, interact with the world (through text, voice, chat, audio, computer vision, image, or video), and take action.
ML is extremely helpful for:
- processing unstructured content (text, images, video) to extract meaning, understand intent & context
- image or video recognition to isolate & identify objects
- make decisions by weighing complex factors
- categorize & group input (classification)
- pattern recognition
- language recognition & translation
- process historical data to isolate trends occurring, then forecast or predict those trends from there
- generate new output (text, image, video, audio generation)
ML models are built from a wide variety of statistical model types geared for specific problems, each with a wide number of statistical algorithms that can be used in each. Some common types include:
- Classification models are used to classify data into categories (labels), in order to predict a discrete value (what category applies to new data).
- Regression models are used to find correlations between variables, in order to predict continuous values (numerics).
- Clustering models are good for clustering data together around the natural groups that exist, such as for segmenting customers, making recommendations, and image processing.
There are a number of ways that ML can be taught, including:
- Supervised Learning is training via a dataset with known answers. These answers become labels that the ML uses to identify patterns and correlations in the data.
- Unsupervised Learning is training via raw data and letting the AI determine the features and trends within the data. This is used by ML systems for making recommendations, data associations, trend isolation, or customer segmenting.
- Semi-supervised Learning is in between, which uses a subset of training on a labeled dataset, and another unlabelled one to enrich it further.
- Reinforcement Learning is a model that gets rewarded for correct and timely answers (via internal scores or human feedback). This is used when there is a known start and end state, where the ML has to determine the best way to navigate the multiple paths in between. This is being leveraged in new language models like ChatGPT to improve the way the engine "talks".
Some of the components of building ML that are helpful to understand:
- Features are characteristics or attributes within the raw data that help define the input (akin to columns within a database). These are then fed in as inputs to the ML model, and weighed against each other to identify patterns and how they correlate to each other. Feature Engineering is the process where a data scientist will pre-identify these variables within the data, such as categories or numerical ranges to track. Feature Selection may be needed to select a subset of features in model construction, which may be repeatedly tested to find the best fit, as well as helps simplify models and shorten training times. Features can be collaboratively tracked in Feature Stores, which are similar to Metric Stores in BI stacks [both discussed in the Modern Data Stack]. Unsupervised Learning forces the ML engine to determine the important features on its own.
- Dimensionality is based on the number of features provided as input into the model – or rather, represents the internal dimensions of the model of how each feature relates to and impacts every other feature (how one variable in a row of input impacts another). High-dimensional data refers to datasets having a wide set of features (a high number of input variables per row).
- Observations are the number of feature sets provided as input while building the model (akin to rows within a database).
- Vectors are features turned into numerical form and stored as an array of inputs (one per observation or row, or a sentence of text in NLP). An array of vectors is a two-dimensional matrix. [This is why GPUs are so helpful in ML training, as they specialize in vectorized math.]
- Tensors represent the multi-dimensional relationships between all vectors. [Hence why Google and NVIDIA use the name often in GPU products, as they specialize in highly-dimensional vectorized math.]
- Labels are pre-defined answers given to a dataset. This can be the identification of categories that apply to that data (such as color, make, model of a car), successful or failed outcomes (such as whether this is fraud or risky behavior or not), or the tagging and definition of objects within an image or video (this image contains a white cat on a black table). These are then fed into Supervised Learning methods of training ML models.
- Parameters are what the ML model creates as internal variables at a decision point. This is a trained variable that helps set the importance of an individual feature within the ML engine. (This can be weights & biases within a neural network or a coefficient in a regression.) The parameter count is a general way that ML models use to show how much complexity they hide. (OpenAI's GPT-3 had 350M-175B parameters in various flavors, and GPT-4 is believed to have up to 1T.)
- Hyperparameters are external variables the data scientist can adjust in individual statistical algorithms used within the ML model. Think of them as the knobs that can be tuned and adjusted to tweak the statistical model within (along with the fact there are countless statistical models that can be used for any specific algorithm, which can be swapped out).
As with anything data related, it is "garbage in - garbage out". You must start with good data to have a good ML model. Data science is ultimately the art of creating an ML model, which requires data wrangling (the cleaning, filtering, combining, and enriching of the datasets used in training), selection of the appropriate models & statistical algorithms to use for the problem at hand, feature engineering, and tuning of the hyperparameters. Essentially, data science is about asking the right questions in the right way.
ML models are trained with data, then validated to assure "fit" (statistical relevance) to the task at hand, as well as can be tuned and tweaked along the creation process by the data scientist (via the training data being input, the features selected, or hyperparameters in the statistical model). Once in production, it is typical to occasionally test it to ensure it remains relevant to real-world data (fit), as both models and data can drift (such as shifting behaviors of customers). Models can be trained on more and more data to become more and more accurate in classifications, predictions, and generation. More data generally means more insights and accuracy – however, at some point the model may go off the rails, and start trying to find patterns in random outliers that aren't helpful. This is known as being "overfit", where its trained findings aren't as applicable to real-world data by factoring in noise or randomness more than it should. It must then be retrained on a more up-to-date set of historical data.
Neural Networks
One form of ML is known as a neural network, which takes that "AI brain" (compute engine) and breaks its architecture up into 1000s of individual pieces called "neural nodes". This is well named, as it works very akin to how your own brain is made up of nerve cells (making decisions) and synapses (interlinking those decisions and weighing them against each other). Input can be split up, broken into hundreds or thousands or millions of weighed decisions, which might then trigger another layer of decisions.
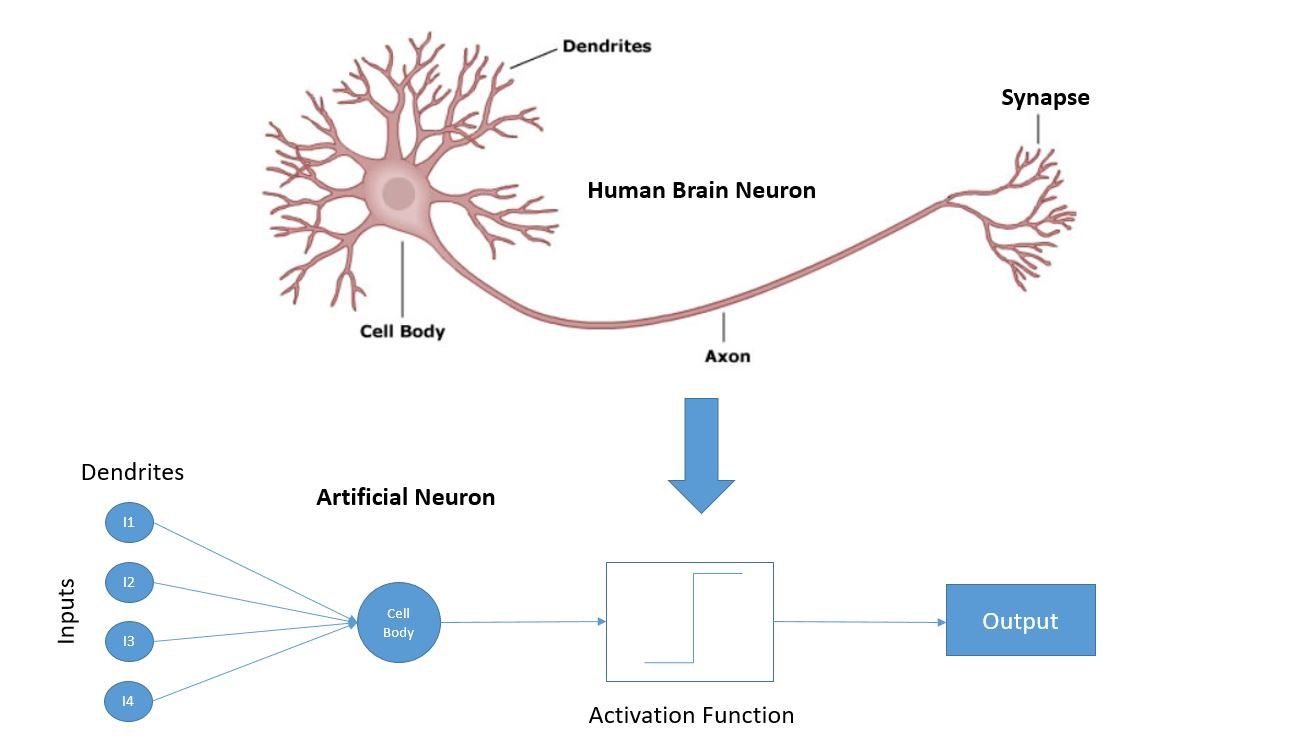
- Weights are the individual internal parameters of a neural network to weigh the importance of each input (feature) to the decision at hand and how each input relates to the others. These are the parameters set in a neural network during training, which are then summed up in each node to make a decision.
- Bias is a separate parameter per layer of a neural network that allows for increasing or decreasing the importance of the decisions within the nodes of that layer. This essentially equates to putting a thumb on the scale of any individual layer (decision point) within the neural network, to make it easier or harder to hit that decision.
- An activation function is the end result of an individual node, which sums up the weighted inputs plus the bias to make a decision and pass data onward.
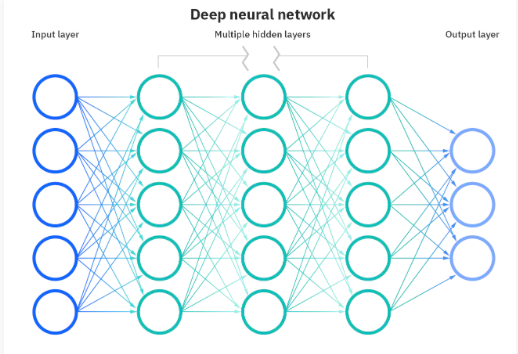
This architecture is known as deep learning, as it uses a number of separate layers (each with its own set of neural nodes) to be able to navigate through extremely complex decisions over a vast number of variables. The nodes within each layer combine all the micro-decisions into one final decision per layer, which then pass to the next layer, and on and on. It's a dynamic chain of logic engines that interact with other logic engines, iterating decisions together repeatedly, weighing outcomes, and coming to a final decision. There are many forms of neural networks, based on how nodes and layers interact, interconnect, and flow. One type is a Recursive Neural Network, which can iterate decisions over and over as it weighs factors from input, which are combined to decide how to proceed.
Neural Networks allow for processing data with high dimensionality (the relationships between a greater number of individual features, such as columns in a dataset or terms of vocabulary), making them well-suited for handling multi-layered decision-making over complex problems, and for finding correlations across disparate datasets. They are ideal for time-series forecasting, fraud detection, pattern recognition, object detection & classification, and language understanding & translation. But the ability to handle more complex problems means a more complicated architecture and training process. Some differences over ML include:
| Machine Learning (ML) | Deep Learning (DL) | |
|---|---|---|
| Data points | small | large |
| Hardware | low-end | high-end GPU (for matrix multiplication) |
| Featurization | needs features labeled | can learn features & create new ones |
| Approach | divides into smaller steps & combines | resolve end-to-end |
| Execution | little time to train | long time to train across many layers |
| Output | numerical score or classification | can be multimodal, over text, audio, image, video |
Infrastructure Advancements
One key to how rapidly neural networks have been iterating lately is in the use of GPUs for training and usage (inference). Ultimately deep learning models are a series of parallel mathematical algorithms (across all nodes in a layer) over vectors (arrays of numbers) and matrices (arrays of vectors). Once the province of gaming and advanced graphics, Graphical Processing Units (GPUs) from NVIDIA and others are ideal for multi-parallel processing over vectorized math (i.e. matrix multiplication). GPUs are especially well suited for neural networks, and all hyperscalers provide NVIDIA GPU instances in their AI/ML engines (as IaaS or PaaS), plus have developed their own highly honed chipsets (such as Google TPU, AWS Inferentia/Trainium – Azure is way behind here, though has hinted of coming specialized chips).
The scale of cloud infrastructure has greatly expanded how these AIs are built and how they can train, and hence have multiplied the complexity of the models and their capabilities. Azure has an exclusive partnership with OpenAI, creating a massive set of supercomputer infrastructure in Azure that is dedicated to training and usage (inference) of all of OpenAI's models. [More on that later.]
Another recent innovation is the emergence of vector databases, which are specialized databases that store and query over high-dimensionality vectors and their relationships to other vectors (tensors). These databases are extremely helpful in similarity searches for search & recommendation engines and Computer Vision, and are speeding up semantic understanding in NLP. These databases can be queried to find similar images on content & style, documents on topic & sentiment, and products on similar features & ratings. Vector databases can essentially provide long-term memory for AI.
All these advancements in deep neural networks are now driving huge advancements in NLP and Generative AI.
NLP
NLP (natural language processing) is a subset of neural networks that are focused on understanding the intent and context of language. NLP is an area of AI that is often consumer-facing, such as through voice assistant platforms like Apple Siri, Amazon Alexa, and Google Assistant ("Hey, Google"). NLPs can be focused inward (understanding the meaning of input) and/or outward (generating textual output). (Think of text generation as predicting how words string together, and you realize how similar NLP is to pattern recognition & time-series forecasting.) New advancements here are capturing a huge amount of attention, as it gives an AI engine the ability to better understand our requests and speak back to us.
- Tokens are the first step in NLP to break textual language or code into basic units (words, subwords, characters, punctuation). These are each given a numeric ID, which turns the words into numbers. These tokens are then stored as a vector (numeric row of tokens) and becomes the input (features) into an NLP. Byte-Pair Encoding (BPE) is a tokenization method that merges the most frequently occurring pairs of words into a single token, and is a method used by OpenAI in GPT.
- An embedding is a deep learning process of training on word vectors to build them into a high-dimensionality model (tensor). This allows an NLP to align vectors around similar meanings and understand the semantic relationship between them. This is used to ultimately build an understandable vocabulary, allowing the model to understand and generate sentences and paragraphs, and understand similar words with different meanings.
Transformers became an important advancement that allows an NLP engine to better extract the meaning and context of language. They are designed to quickly process text input and are ideal for language translation and summarization. Key to transformers is the concept of self-attention, which allows a transformer to weigh the importance of each word in a sentence to the other words during embedding. This allows the model to focus on the most important factors of the text and ultimately improve the overall context. (An example of context would be knowing when you say "pool" that you mean either a verb to group something together, a swimming pool, or a game of billiards.) Transformers can combine words into relevant groups, split them into sequences of meaning, and combine those into context to fully understand the intent. This mechanism allows it to weigh the importance of segments within an overall text and be able to summarize it.
Another critical aspect is how transformers allow the processing of all textual input at once, instead of sequentially. This essentially has allowed NLP to better use multi-parallel processing during training, which, combined with cloud performance improvements, has greatly sped up how NLP models can be iterated over and improved.
Generative AI
Generative AI is a catch-all term for this new breed of AI that can be used for generating content built on its trained "knowledge", instead of one honed around typical ML uses cases of data prediction and classification. (Though in fact, it is predicting – predicting its answer from the pool of knowledge it has built.) What interactive chat prompt interfaces are allowing is better honing your requests, so there can be a refinement process. What we see exploding in the news of late are advanced deep neural networks that are:
- Generative AIs: AI engines specializing in generating creative content (image, videos, audio, text, or multi-modal). Text-to-image engines like OpenAI's DALL-E, Midjourney, and Stable Diffusion (open-source from Stability.ai) emerged over the past year to allow you to create images from text-based prompts. Video, audio, and other formats are emerging.
- Large Language Models (LLMs): A form of Generative AI that is a massive NLP (natural language processing) engine capable of understanding and responding to textual language. These models are extremely useful for classification, summarization, translation, and text generation (dialog) – which all combine into a helpful virtual assistant for understanding, summarizing, and generating text. Advanced LLM engines like OpenAI's ChatGPT, Google Bard, LLaMA (open-source from Facebook), and Dolly (open-source from Databricks) have emerged within the past few months.
Generative AIs train on a huge body of prior content (such as existing imagery) in order to derive object characteristics and context. LLMs train on a huge body of text (such as public web pages) in order to build up a general knowledge of language, and both understand and generate it. LLM models are well suited for:
- text classification: assign labels/categories to text
- text summarization: extract the most relevant info from text, recap important points
- text translation: convert from one language to another
- text generation: create new and original text
Transformers were key to unlocking all the new LLMs that have since emerged from OpenAI and others, and why more emerge each week. And those advancements are not just for text (language and code) – transformers are multi-modal and be applied to other formats, making them also helpful in advancing Computer Vision in the extraction of meaning from unstructured data, and the generation of images and video.
OpenAI has become a household name in its continued advancements in LLMs over the past few year, and has been busy honing them for different purposes. One advancement was in its Codex engine, a specialty LLM that can understand and generate application code (programming languages). Another was in ChatGPT, where OpenAI trained its main LLM (GPT-3) using reinforcement learning (from human trainers) to train it to understand and respond via an iterative chat interface (making for the most advanced chatbot the world has ever seen). Their new GPT-4 is promised to be multi-modal, and will soon accept images as input as well as text.
Transformers have proven to be a huge breakthrough in Generative AI – so much so that a Transformer engine has now been directly embedded into NVIDIA's latest "Hopper" line of GPUs (H100), with their announcement in Mar-22 stating:
"Now the standard model choice for natural language processing, the Transformer is one of the most important deep learning models ever invented."
And it's not just Transformers that are unlocking the potential in Generative AI. Generative Adversarial Networks (GANs, a 2-sided model for generating content and evaluating it against reality) & Diffusion (noise addition/removal to better isolate objects in images, which improves the generation and merging of objects) are 2 other neural network models that are helping advance Generative AI to create realistic content in images and video.
While there is a clear "gold rush" mentality with AI/ML, it is not unwarranted, as there has been a huge paradigm shift with Generative AI and LLMs. I will be focused most on opportunities in the picks and shovels of AI/ML tooling, as well as new vertical apps that are emerging that are honing AI/ML into specific verticals.
Add'l Reading
- Read the entire 3-part AI series [paid], including 2 podcasts.
- See the Modern Data Stack in Sep-22 [paid] for a round-about primer on the ML stack and workflow (Feature Stores, MLOps, AutoML).
- Matt Turck released MAD (ML, AI, Data) Landscape for 2023 in Feb-23. Part IV in particular covers a brief history of the AI/ML trends of late as text-to-image and LLMs emerged and blossomed over 2022-2023.
- Play with OpenAI's ChatGPT and DALL-E if you haven't yet. (It just takes a Google login to access their free tier.)
As mentioned, I will be exploring a number of AI/ML themes going forward in the Premium service. Sign up! I have already covered layers to watch for investments, Microsoft + Open AI moves, and Google's recent advancements at I/O. I'll be diving into the AI landscape further, including Databricks, Snowflake, NVIDIA, and the hyperscaler moves.
-muji