
Now that we covered NVIDIA's ongoing woes (Blackwell delay or limited release, China-focused product, and supply chain easing), let's cover the waves of product releases from here as we approach their earnings report this week.
NVIDIA releases its Q325 (Aug-Sept-Oct) earnings tonight. This week, Premium covered Q3 expectations and their software & sovereign AI moves over the summer as they (and the world) await the release of Blackwell.
I covered NVIDIA extensively in the Premium service this year, with the stock up ~100% since. In February and March, I covered the NVIDIA tsunami heavily across a series of posts over their explosive financial execution, product moves in 2023, the rise of Blackwell, and their moves into software. Since then, I covered FY25 expectations and COMPUTEX announcements, their woes (Blackwell delays) and waves (this post), and reviewed their Q1 and Q2 earnings.
Premium has also recently covered hyperscaler results and their AI, chip, data, and security moves of late, Palantir's AI moves, CrowdStrike's July incident and recent Fal.con announcements, and the latest results from GitLab, Samsara, Monday, and CrowdStrike. October was Cybersecurity Month, which looked at CyberArk vs Okta, XDR shifts, and the CNAPP, SIEM, and Identity markets.
Join Premium for insights like this every week across AI & ML, Data & Analytics, Next-Gen Security, DevOps, and the hyperscalers.
- H200 will finally be ramping up this Q, and should drive Hopper sales for the rest of the year.
- There is also a refreshed Grace Hopper superchip (GH200), which should also be shipping at volume.
- They are also shipping new H20 chips into China this Q – but my expectations are low that it moves the needle much.
- Networking should rebound this Q too, with Spectrum-X shipments ramping up in volume plus InfiniBand supply issues have eased.
- Q2 looks to be strong, and H200 and the refreshed GH200 will likely drive results over the next few quarters. Blackwell may be delayed, but it seems like H200/GH200 demand can pick up the slack.
- Q4 may be where a lower volume of Blackwell supply starts to impact. Clouds & biggest customers should get an initial supply of Blackwell chips and DGX supercomputers over Q4/Q1, but it may take a few quarters for the B200A alternative to show up to help ease enterprise demand for Blackwell.
- Any delays or capacity constraints in TSMC's CoWoS are likely to impact AMD too.
Hopefully, we will hear more on schedule impacts & any chip changes, but strategy & roadmap aren't normally covered in earnings calls.
A few more Blackwell clues
I covered the rumors swirling around Blackwell delays in the last post [paid], but wanted to note how suppliers don't seem that worried, given that Hopper demand remains so high. All of these suppliers were named in the recent Blackwell announcement [paid] at COMPUTEX.
- Taiwan-based semi-analyst Dan Nystedt posted a thread with earnings comments from two Taiwanese data center system providers Wiwynn and GIGABYTE that confirm the Blackwell delay and strategy change. GIGABYTE was showing off Blackwell chips and a liquid-cooled DGX GB200 NVL72 at COMPUTEX in June, and suggested that Blackwell revenue is coming soon from GB200 and B200A (that rumored new lower-end Blackwell chip).
- In a later tweet, Nystedt noted comments from hyperscaler system provider Quanta Computer (QCT) that AI demand remains high. QCT provides systems for hyperscaler customers like AWS, GCP, and Alibaba, who need H200/GH200 now shipping and Blackwell chips soon to ship.
- Foxconn (through its Ingrasys subsidiary) has also stated it is ready to ship initial GB200 volumes in Q4, increasing into Q1 – but that rising interest in H100/H200 will cover any delay. They too were showing off H200, B100/B200, and the DGX GB200 NVL72 at COMPUTEX, plus noted how they were building a new Taiwan data center with a Blackwell supercomputer.
Foxconn spokesperson: "It is normal to dynamically adjust [shipment schedules] when the specs and technologies of a new product are largely upgraded. Whether the shipping schedule changes or not, Foxconn will be the first supplier to ship the first batch of GB200. Even if we don't consider the revenue contribution of GB200 for this year, we can still meet the target of year-over-year and quarter-over-quarter growth in revenue of AI server for the second half of this year."
An AMD aside
Beyond the hyperscalers' custom silicon, NVIDIA's primary competition is AMD and their Instinct GPU line, including the MI300X chip that released in Dec-23. AMD uses TSMC's 5nm/4nm and CoWoS-S packaging currently (any chip using HBM memory requires it).
Despite doubling their CoWoS capacity over the past year, there are rumors that NVIDIA and AMD have booked TSMC's entire CoWoS capacity through 2025. NVIDIA is the first user of CoWoS-L, and TSMC has been converting over -S lines to -L lines as NVIDIA begins to use the new process (and now, it seems, test its limits). But AMD has plans to leverage it soon – likely in their MI350 that was to debut at the end of this year and ship in volume in 2025, to compete with Blackwell.

Any retooling CoWoS lines (of -S to -L) or over constrained capacity also impacts AMD. NVIDIA has likely contracted an overall output over a set period, and if delays and constraints are impacting TSMC's output and yield, AMD will likely have to wait until that promised output level (pushed out from any delay) clears, before their future product can utilize this cutting-edge chip packaging process.
The Final Hoppers (plural this time)
Hopper is getting a major memory upgrade before it passes the torch to Blackwell, in what will be known as the "Ultra" release going forward per their roadmap. As I mentioned last piece, major HBM vendors SK Hynix and Micron started to ship their new HBM3e modules in volume around March. SK Hynix was NVIDIA's sole HBM3 provider thus far, and Micron has been heavily touting that they have also been added as a vendor as of the H200. Samsung seems likely to be approved soon too.
Micron ... today announced it has begun volume production of its HBM3E (High Bandwidth Memory 3E) solution. Micron’s 24GB 8H HBM3E will be part of NVIDIA H200 Tensor Core GPUs, which will begin shipping in the second calendar quarter of 2024.
Q2 should have the first contribution from H200 (aka "Hopper Ultra") shipping at volume. H100 & now H200 should then drive NVIDIA sales for the next several quarters – especially if Blackwell ends up delayed or with a more limited release.
A H200 performance blog post in Mar-24: "NVIDIA is sampling H200 GPUs to customers today and shipping in the second quarter. They’ll be available soon from nearly 20 leading system builders and cloud service providers. H200 GPUs pack 141GB of HBM3e running at 4.8TB/s. That’s 76% more memory flying 43% faster compared to H100 GPUs. These accelerators plug into the same boards and systems and use the same software as H100 GPUs.
... Even more memory — up to 624GB of fast memory, including 144GB of HBM3e — is packed in NVIDIA GH200 Superchips, which combine on one module a Hopper architecture GPU and a power-efficient NVIDIA Grace CPU. NVIDIA accelerators are the first to use HBM3e memory technology."
That blog post notes that H200 ultimately provides 76% more memory with 43% faster bandwidth. NVIDIA has noted that this provides a 2x performance increase in inference from these hardware advancements, which combines with an additional 2x boost over the past year from software optimizations (from TensorRT-LLM & Triton Inference Engine).
| Chip | HBM type | Stacks | Memory | Capacity | Bandwidth |
|---|---|---|---|---|---|
| H100 | HBM3 | 5 of 6 | 5x16GB | 80GB | 3.35TB/s |
| GH200 w/ H100 | HBM3 | 6 | 6x16GB | 96GB | |
| H200 | HBM3e | 6 | 6x24GB | 141GB | 4.8TB/s |
| GH200 w/ H200 | HBM3e | 6 | 6x24GB | 144GB | |
| B100 | HBM3e | 8 | 8x24GB | 180GB | |
| B200 | HBM3e 12-hi | 8 | 8x32GB | 256GB |
H200 seems an easy sell that fits right into existing Hopper system designs, so should start selling immediately through partners. H200 should spur a new wave of demand from clouds & large enterprises that want the latest & most performant chip within their AI supercomputers, this time with greatly improved memory capacity and bandwidth over the prior H100. An 8x HGX server would have 1.15TB of GPU memory overall. More memory means larger and larger models that can fit on a single system.
Any delays mentioned before are solely for Blackwell on TSMC's newest CoWoS-L process – H200 uses the same CoWoS-S process as H100, so NVIDIA should be able to make just as many Hopper chips as in past quarters (or hopefully more if TSMC increased 5nm/4nm capacity).
CEO at GTC IR Day, Mar-24: "Most of our customers have known about Blackwell now for some time. ... As soon as possible, we try to let people know so they can plan their data centers and notice the Hopper demand doesn't change. And the reason for that is they have an operations they have to serve. They have customers today and they have to run the business today, not next year."
NVIDIA can now focus over the next few quarters on filling H200 demand from hyperscalers and largest customers, and continued Hopper demand from enterprises. The interest from hyperscalers was high when H200 was (last) announced at SC'23 in November, with the top 4 clouds (AWS, GCP, Azure, and OCI) all committing to adding H200 instances, as well as specialized GPU clouds like CoreWeave and Lambda.
- AWS is adding H200 instances to EC2, as well as L40S and L4, plus is adding GH200 NVL32 supercomputers (32 GPUs) available through EC2 and DGX Cloud.
- GCP is adding a GH200 supercomputer available through DGX Cloud.
- Microsoft is adding H200 VMs instances alongside its existing H100s.
Once those hyperscalers and other top customers are satiated, sales will move into sovereign AI and enterprise. The rumors of a Blackwell delay or strategy change might help spur demand a bit more here knowing that Blackwell will not be as easily available to enterprise (and possibly only through a reduced capacity B200A chip, discussed last post).
An AMD aside, again
Competitor AMD has been touting its higher memory capacity, but NVIDIA has been taking note. AMD's latest MI300X chip arrived in Dec-23 with 192GB of HBM3, or 1.5TB total within an 8x system. FYI: AMD utilized 8 HBM stacks per GPU, while NVIDIA H100 has been using 5 of 6 available stacks, which expanded to all 6 in H200. Blackwell goes to 8 stacks (4 per die of the chiplet), and should be more on par with AMD in memory capacity going forward.
GH200 too
But H200 isn't the only one getting a memory upgrade - the GH200 superchip is also getting an upgrade to HBM3e. When the GH200 (1 CPU + 1 GPU) was first announced, it was based on an H100 with HBM3 memory – but the data sheet and whitepaper list both HBM3 & HBM3e configurations. That means the GH200 is upgrading from H100 to H200 as well (at least unofficially, by getting HBM3e memory). The earlier version of the GH200 had an overall max 96GB of HBM3 memory, while the new one has a max 144GB of HBM3e – again, a 50% increase in capacity and 2x improvement in inference performance.
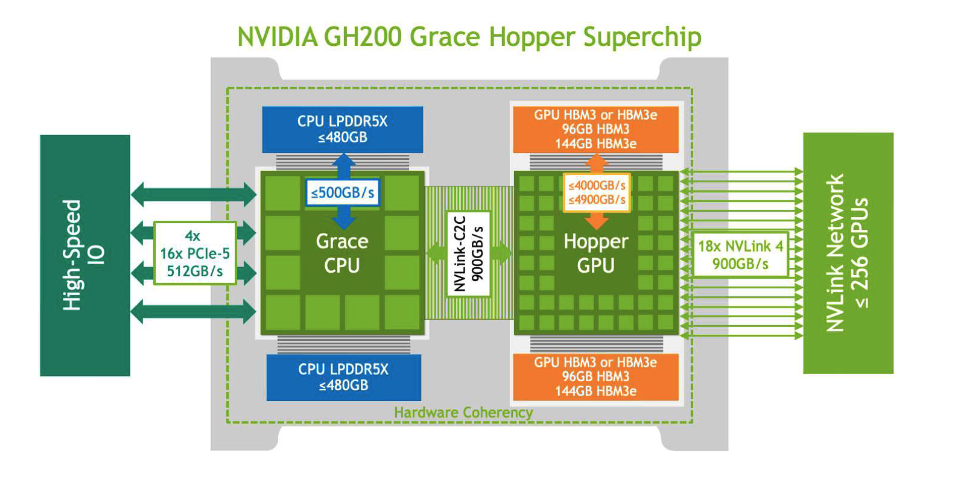
They didn't brand this upgrade as a separate release as they did in the Hopper chips themselves (H100 vs H200), but this newly revamped GH200 (aka "Grace Hopper Ultra") is now shipping in volume in Q2 as well as the H200 ("Hopper Ultra"). [NVIDIA adopted the Ultra moniker with Blackwell's next iteration in 2025, but I feel like backwards applying it to Hopper's step-up release too.]
NVIDIA has been focused on using the GH200 in its DGX supercomputer designs, including their larger GH200 NVL32 supercomputer-in-a-rack, made up of 16 trays of GH200s NVL2 (2x CPUs + 2x GPUs). With this revamped chip, the NVL32 went from 3TB to 4.6TB of HBM3e, with a combined 19.5TB in shared (coherent) memory overall that is usable across all 36 CPUs and 36 GPUs.
GH200 systems are ideal for running AI supercomputers that run adjacent CPU-based apps like databases. Besides handling the training and inference of massive LLMs, they are well suited for recommender systems (over dbs), graph/social networks analytics (over graph dbs), and RAG methods (over vector dbs).
Waves
Let's see what the next few quarters should look like, product contribution-wise.
Q2:
- H200 should be starting to ship in volume this quarter. This upgrades the Hopper line to HBM3e, which is supplied by SK Hynix and now Micron – and likely adding Samsung as a memory vendor any Q now. This gives it +50% memory capacity and 2x inference performance.
- The Grace Hopper GH200 superchips were shipping in volume in Q1, but likely just got the same refresh with HBM3e for +50% memory capacity and 2x inference performance – meaning Grace Hopper Ultra should start to ship this quarter. The top focus for the GH200 is likely in the DGX line, including the GH200 NVL36 rack system. (Remember how the CEO at IR day was telling customers to wait for GB200? Not anymore!).
- H20 has been shipping to China since April/May, so Q2 will be the first full quarter of H20 contribution. Hopefully, we get an update on their strategy here, as the company has been mum on it.
- Networking should be back to growth in Q2 given that InfiniBand supply issues eased by their Q1 earnings. But the real driver is how their new Spectrum-X started to ship in Q1, and is due to ramp up heavily in Q2.
CFO in Q1 remarks: "Spectrum-X opens a brand-new market to NVIDIA networking and enables Ethernet only data centers to accommodate large-scale AI. We expect Spectrum-X to jump to a multibillion-dollar product line within a year."
- Blackwell B100 (750W, air-cooled version) was originally due to be released in limited volumes this Q per mgmt comments in Q1 – but that seems unlikely based on the issues/delays in TSMC's CoWoS-L.
Q3:
- H200 should continue to ramp up, and hopefully H20, GH200 Ultra, and DGX NVL32 rack systems.
- Blackwell B100 may show up in limited release. It will still be on TSMC 4nm, and use the HBM3e memory just introduced in the H200, but supply will be extremely constrained by CoWoS-L capacity (and potentially retooling to deal with issues).
Q4:
- H100/H200/GH200/H20 should continue to sell.
- If Blackwell was delayed, B100 should start shipping in Q4, ramping further in Q1. Hyperscalers and big tech customers are likely the only ones getting demand filled due to CoWoS-L capacity.
- The new Grace Blackwell GB200 superchip (1 CPU + 2 GPU) should start to show up after the initial release of B100 chips. The top focus is likely to be on DGX systems and the GB200 NVL72 (36x GB200s, so 72 B100s) supercomputer rack.
2025:
- H100/H200/GH200/H20 should continue to sell into enterprise demand as Blackwell ramps up.
- Blackwell B100 and GB200 DGX supercomputers will continue to ramp up, plus see the Blackwell B200 (1000W liquid-cooled version) eventually show up.
- I assume we'll see a B20 chip emerge as the successor to H20 for the Chinese market. It is based on CoWoS-S (like the B200A that spawned from its design) so will be less supply-constrained than the rest of Blackwell.
- If the rumors are true, we will see a new less-performant Blackwell chip show up in 1H called B200A. It is reportedly based on single-die (instead of a hybrid chiplet), allowing NVIDIA to continue to use TSMC's original CoWoS-S process. This is rumored to use the next-gen 12-hi HBM3e (starts shipping in volume in Q4 2024), and have 4x HBM stacks instead of 6x. [This was discussed in an earlier paid post.]
- Blackwell Ultra will eventually release, upgrading the HBM3e memory from 8-hi to 12-hi to bump memory from 192GB to 256G per GPU, or 2TB in 8x systems. Grace Blackwell (GB200) will also get this Ultra memory bump, so is likely to renew demand for DGX line, such as their GB200 NVL72 rack system.
- Their newly announced line of 800G networking products will start to ship. (This was waiting on PCIe gen6 standard to take hold.) By the end of the year, we'll see a doubling of ports (radix) in an Ultra version to magnify the size of AI clusters possible.
Further out:
- Rubin is the next-gen GPU after Blackwell, and is likely based on TSMC 3nm tech and CoWoS-L. The latest NVLink will double interconnect speeds.
- Vera will replace Grace as the Arm-based CPU, to combine with their Rubin GPU in the new Vera Rubin superchip.
- Networking will double speeds in 2026 to 1600G as InfiniBand and Ethernet switches converge. (This is waiting on PCIe gen7 standard to take hold.)
Q2 expectations
Q225 is finally lapping the huge first wave of success they had with the Hopper line, which caused their data center segment to grow +141% sequentially.
| Q423 | Q124 | Q224 | Q324 | Q424 | Q125 | |
|---|---|---|---|---|---|---|
| Revenue | $6.1B | $7.2B | $13.5B | $18.1B | $22.1B | $26.0B |
| DC Revenue | $3.6B | $4.3B | $10.3B | $14.5B | $18.4B | $22.6B |
| ... % of mix | 60% | 60% | 76% | 80% | 83% | 87% |
| ... YoY growth | +11% | +14% | +171% | +279% | +409% | +427% |
| ... QoQ growth | -6.7% | +18.5% | +141% | +40.6% | +26.8% | +22.6% |
| Gross margin | 66.1% | 66.8% | 71.2% | 75.0% | 75.0% | 78.9% |
| Op margin | 36.8% | 42.4% | 57.6% | 63.8% | 66.7% | 69.3% |
| FCF margin | 28.7% | 36.8% | 44.8% | 38.9% | 50.8% | 57.4% |
They guided for $28.0B in Q2, which would be +7.5% seq or a mere +107% YoY growth. If they beat by ~$2B (as they have over the last 4Qs), that would be more like +15.2% seq and +122% YoY. This would mean over $26B in DC revenue, for +15.6% seq or a +153% YoY growth.
- The biggest supply chain constraint seems to be improving. TSMC's 5nm segment had revenue rise in Q2 (after dip in Q1), improving overall from Q4. This signals improved 5nm capacity. (Of course, that added capacity might be for other clients.)
- Hopper demand is likely moving from hyperscalers more to enterprises through system partners.
- Memory issues seem to have eased. NVIDIA was solely sourcing HBM3 from SK Hynix. As for the new HBM3e memory, NVIDIA is now sourcing from 2 HBM providers (SK Hynix plus now Micron) and likely soon 3 (Samsung). H200 should not have any new constraints over H100, and with multiple memory providers, I expect them to be shipping H200 in volume to clouds and top tech customers first. The revamped GH200 should also be shipping in volume.
- Spectrum-X should ramp up heavily in Q2, plus InfiniBand supply issues have eased per mgmt at the end of Q1.
- Blackwell delays likely pushed out Blackwell's appearance a bit, so don't expect much until Q3/Q4. Even then, it will likely be muted until TSMC gets CoW0S-L straightened out and at full yield.
One big question now is – if NVIDIA is having such difficulty with the new CoWoS-L packaging process (both in issues with chip and in finding enough capacity), how easily can TSMC shift its existing processes and lines around? As the first user of CoWoS-L, NVIDIA is the guinea pig for scaling this new process up. TSMC noted they doubled CoWoS capacity over past year, plus expect to double capacity again in the coming year.
- Does TSMC fix and improve its CoWoS-L process quickly?
- If so, NVIDIA can likely proceed as previously planned, with the production ramp-up of Blackwell chips being slightly delayed. They could stick with or discard any strategy change around the new chip.
- If not, NVIDIA has alternate plans of making a slightly reduced Blackwell chip that is compatible with -S in order to reduce the need for CoWoS-L in a subset of demand. This new chip would compete with the H100/H200/H20 assembly.
- To further complicate it, TSMC has been converting -S capacity into -L, which may mean that -S could be more constrained now than before. Thankfully NVIDIA is a preferred vendor, but AMD is also using -S in its new MI300X chip.
- Further delays here would disappoint, but again, this likely has a chain effect that impacts AMD in addition to NVIDIA.
The issue is mostly delays in revenue from Blackwell, not that the revenue is going elsewhere or that orders are being cancelled. Hopper demand appears strong per NVIDIA and suppliers, so should buffer the coming quarters from any strong impact from lower Blackwell revenue.
Beth Kindig of IOFund recapped the delay saga in a post today (plus covered TSMC earnings, past mgmt comments, and CoWoS), noting that the reliance on cutting-edge manufacturing processes means issues like this can and do arise.
"Nvidia is delivering the history’s most aggressive product road map on new fab processes. This is a “move fast, break things” problem, which contrasted to strictly a design flaw, does not mean the architecture inherently has issues. Rather to contrast, the progression of this generation is testing the upper limits of manufacturing complexities. Blackwell with CoWoS-L packaging seeks to increase yields by circumventing a silicon monolithic interposer, and instead, will use an interposer with higher yields to help package the processing and memory components seamlessly together. The result will be to break ground on unprecedented performance gains for memory-intensive tasks.
... There were many opportunities for TSMC to report a material impact from idle machines – quarterly numbers ending in June, July monthly numbers, commentary during the earnings call from the CEO who establishes the opposite, which is that capacity is primarily the issue (rather than a dire flaw that is halting production) and the company is working hard to increase this capacity."
Beth's piece also brought up mgmt quotes from GTC IR Day and onward, to show that mgmt noted multiple times how they were on the cutting edge of manufacturing processes.
CFO at GTC IR Day, Mar-24: "We've continued to work on resiliency and redundancy. But also, you're right, moving into new areas, new areas of CoWoS, new areas of memory, and just a sheer volume of components and complexity of what we're building. So that's well on its way and will be here for when we are ready to launch our products.... It's very true though that on the onset of the very first one coming to market, there might be constraints until we can meet some of the demand that's put in front of us.
I (and every investor) hope to hear a lot more about any Blackwell strategy changes on this coming call. But we may have to wait until SC'24 in November (the next big AI supercomputing conference) for a bigger picture.
Add'l Reading
- See my previous primer on NVIDIA's product lines.
- IDC thinks AI spend will see an overall 29% CAGR over the next 4 years, with Generative AI at 59.2% CAGR, and AI software at 24.3% CAGR.
- Per The Information, a new chip smuggler industry [paid] has emerged across southwest Asia to buy GPUs through shell corps, install them into dummy data centers, and then re-route them to Chinese companies. Despite trying to play "whack a mole" when it comes to Chinese access to GPUs & AI, the US gov will not be able to close all of the massive loopholes across all of NVIDIA's partners and customers over distributors, system manufacturers, hyperscaler clouds, and 3rd party AI services. SemiAnalysis [paid] covered this subject as well in October.
- A short report on SuperMicro came out from Hindenburg. To sum up: They rehired execs that got them delisted/fined by SEC, those execs are again doing shady rev recognition, there are a number of suspicious related party transactions, possible export violations to Russia, Dell is winning over key customers (Tesla/xAI, CoreWeave, Digital Ocean), and customers are seeing an elevated rate of hardware issues.
- Gavin Baker had an interesting point on a podcast (per this tweet), noting that mgmt comments on rising opex by hyperscalers/biggest tech are about winning in AI, not ROI. "So everybody is really focused on this ROI equation, but the people making the decisions are not."
- See my Premium posts on the latest hyperscaler earnings and capex, along with their AI, chip, data, and security moves of late.
In retrospect – most of this post played out in Q2 and into Q3 as expected. However, NVIDIA has demoted the importance of DGX GH200 NVL32 in lieu of their coming DGX GB200 NVL72 (twice the GPUs in Grace Blackwell).
NVIDIA reports Q325 tonight after the bell. Join Premium for insights like this every week across AI & ML, Data & Analytics, Next-Gen Security, DevOps, and the hyperscalers.
-muji