
AWS held re:Invent in Nov/Dec-22, their largest conference for product announcements that has been run annually since 2012. As always, it was filled with a wide variety of keynotes and sessions to cover new announcements in IaaS (cloud infrastructure) and PaaS (cloud platform) capabilities across data & analytics, DevOps, and security. Let's look at what announcements are most relevant to data & analytics platforms like Snowflake, Databricks, Confluent, and Elastic, as well as, of course, the other hyperscalers (Google and Microsoft).
Here's a shortcut list of product news that is relevant to each company.
- Snowflake & Databricks: Security Lake, Data Exchange (marketplace) over data lakes, Redshift enhancements (Zero-ETL, Streaming Pipelines, Spark integration, Dynamic Data Masking), Amazon DataZone, AWS Clean Rooms
- Confluent: MSK Tiered Storage, Redshift Streaming Pipelines, Athena Streaming Query, Glue Data Quality, expanded ingest sources in ETL tools (Data Wrangler and AppFlow)
- Elastic: OpenSearch Serverless
Let's dive into the Data & Analytics product announcements and my thoughts on the impacts. While AWS focused heavily on Redshift enhancements and cross-service integrations, I was mostly underwhelmed. I find Redshift is staying busy catching up to Snowflake's features while Snowflake moves farther forward. But their new Security Lake holds promise as a way to corral security analytics into S3 data lakes, and (despite competing with them) AWS continues to focus on co-sell with infrastructural partners like Snowflake and Databricks.
Data & Analytics
AWS has been building up a set of capabilities around its data & analytics services, and continues to expand and cross-integrate across them. In particular, I am most focused on their data warehouse (Redshift), data lake query engine (Athena), and their AI/ML (SageMaker) and big data (EMR, to run Hadoop/Spark) analytical engines. As for data movement, I am most focused on their data streaming capabilities (Kinesis and MSK) and serverless ETL service (Glue, to run Python/Spark).

Last year's focus was on adding serverless flavors of their analytical & streaming engines, plus on expanding their data marketplace features. However, AWS's push towards "serverless" was soon criticized as only delivering auto-scaling capabilities rather than truly lifting infrastructural burdens off the customer. If it does not have on-demand pricing nor turn off fully when idle, it is not serverless by most cloud observers' definition (which is also AWS's own definition when they invented serverless functions with Lambda).
Yesterday AWS announced serverless versions of Kinesis, Redshift, and MSK (Kafka). That's great.
— Maciej Radzikowski (@radzikowski_m) December 1, 2021
HOWEVER, they are not as "serverless" as you may think - pay-per-use, like Lambda. With all three you have to pay a flat rate for the cluster existence 💰
This year saw additional moves towards "serverless" and expanding the data marketplace, plus a focus on cross-integration between all of the separate data & analytics services. The announcements most relevant to Snowflake, Databricks, Elastic, and Confluent:
- They announced Amazon Security Lake in preview, a new focused data lake for security analytics over logs pulled from AWS services and 3rd-party security partners. The ingested data is then normalized into their new OCSF standardized format, and can then be analyzed by AWS analytical tools or 3rd-party SIEM partners.
- Last year they were most focused on adding "serverless" versions across all of their analytical & streaming engines, including Redshift, MSK, SageMaker, and EMR, and most went GA by Jun-22. This year they added OpenSearch Serverless in preview, a managed search-oriented database from their open-source fork of ElasticSearch.
- Last year they expanded their data marketplace (Data Exchange) into being able to buy and sell data via Redshift tables and APIs. This year they extended it again to support in-place access to S3 data and data lake tables.
- They had a number of announcements for Redshift around "Zero-ETL", adding new auto-ingest capabilities from S3 data lakes and Aurora operational databases, plus new streaming ingest capabilities in Redshift from Kinesis Data Streams (serverless ETL pipelines) and MSK (managed Kafka clusters).
- They announced AWS Clean Rooms in preview, a new secure data-sharing capability over data lakes to co-mingle data in a privacy-preserving way, and run analytics over the final joined dataset.
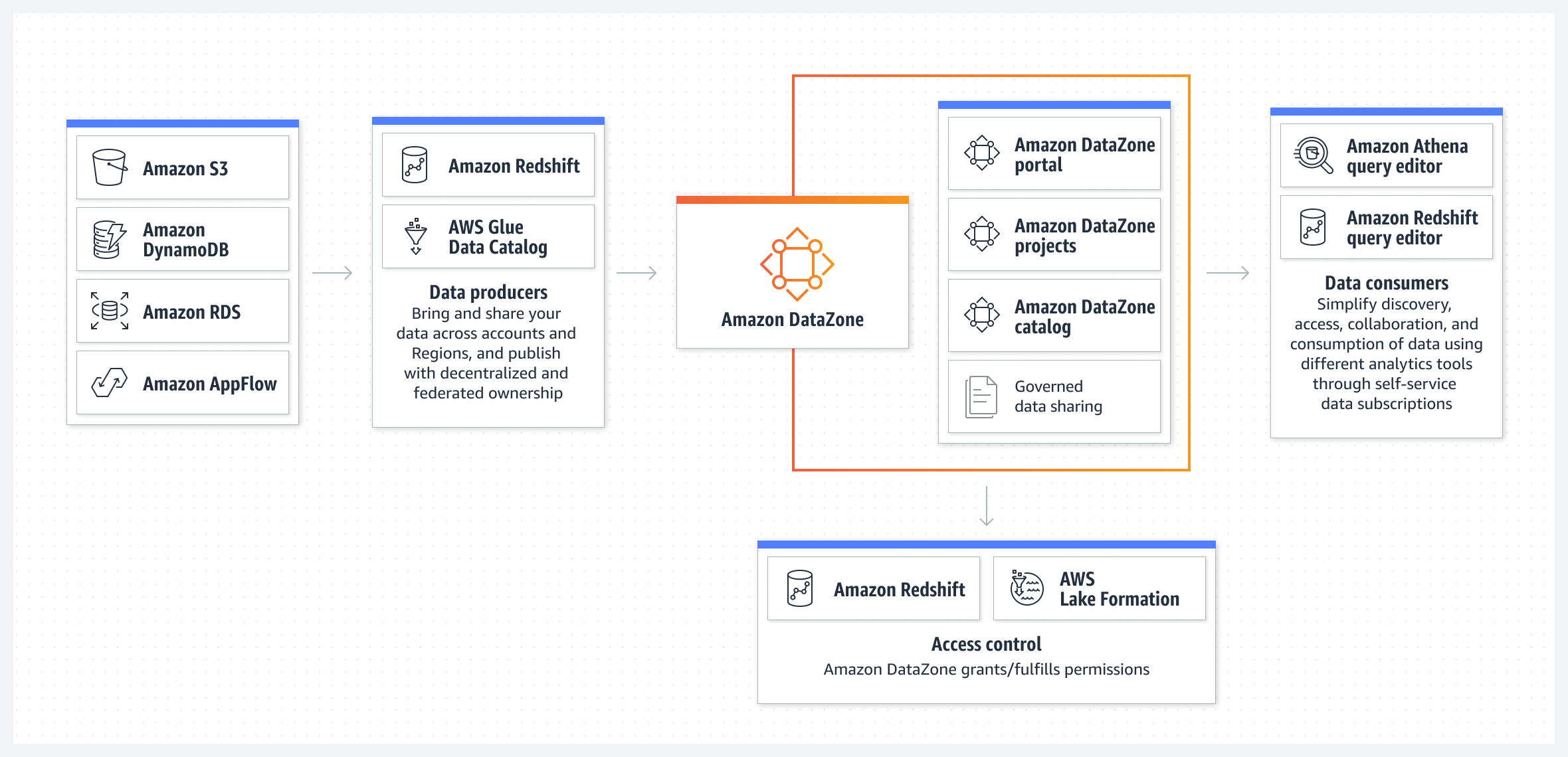
- They announced Amazon DataZone in preview, a new data governance platform to catalog and grant access to BI datasets in Athena, Redshift, and QuickSight, as well as 3rd-party partners Snowflake and Databricks.
- They added marketplace seller dashboards to QuickSight (their BI platform), as well as a new integration with Databricks's SQL Lakehouse.
- Amazon Athena (data lake query engine via SQL) added a Spark engine to allow programmatic queries over data lakes and other databases. Later in Dec-22, Athena also added SQL query capabilities over data streams in MSK.
- Redshift got a revised Spark connector to programmatically access Redshift data when using Spark in EMR, SageMaker, and Glue (and presumably Athena's new Spark engine too?).
- Redshift Serverless added the ability to deploy across multiple Availability Zones (AZs) within a region for high availability and failover on AZ failure.
- AWS Glue (their serverless ETL service via Python/Spark) added support for data lake formats like Delta Lake and Iceberg, added Data Catalog crawlers for Snowflake (plus added Databricks's Delta Lake later in Dec-22), and added a new Data Quality capability in preview to monitor data pipeline health.
- Amazon AppFlow nearly doubled its connectors to now be able to pull data from 50+ SaaS services into S3 data lakes, such as financial data (Stripe), ad tracking (LinkedIn, Facebook, Google), source code repos (Github), and customer communications (SendGrid, Zendesk).
- AWS SageMaker Data Wrangler (ETL service for ML jobs) could already pull data from AWS's databases plus 3rd-party providers Databricks and Snowflake. They also added AppFlow as an ingest source to allow pulling data from SaaS services into SageMaker.
- MSK (managed Kafka clusters) added support for Tiered Storage in Oct-22. This allows Kafka to save data to S3, allowing customers to retain data longer and control storage costs by using a storage tier outside of the MSK cluster.
Redshift is having its 10th birthday this year, a mark Snowflake will also hit this summer. Redshift has been inching its way towards Snowflake over the past few years. In Dec-19, they added instances that separated storage and compute. They added data sharing between Redshift clusters in Mar-21, and later expanded it to cross-region sharing in Feb-22. During a session on Redshift, they stated that 1000s of Redshift customers are now using data sharing, for over 12M queries a day. At the last re:Invent, they announced Redshift Serverless with an on-demand pricing model in Dec-21, which finally went GA in Jul-22.

Security Lake
One of the bigger announcements of the event was their new Amazon Security Lake capability, making it easier to create and manage S3-based data lakes as the centralized store for security analytics over AWS's platform. This is akin to their previously announced Amazon Health Lake capabilities announced in Jul-21, in that it serves as a centralized data lake over a specific use case, with data from partners normalized into a common format (FHIR format for healthcare, vs the new OCSF schema for security data). For AWS, this is all about making their S3 data lake the center of attention, where they can then leverage using Athena for data lake querying and SageMaker for ML.
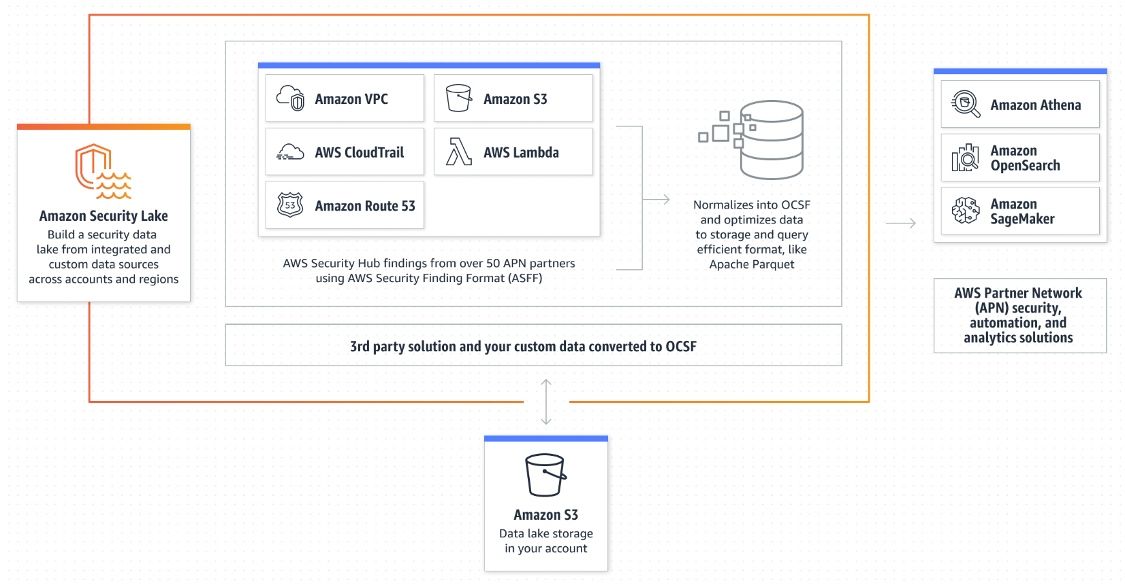
Snowflake has also moved into being a centralized store for cybersecurity workloads in Jun-22 [as previously covered in premium], and Databricks is sure to move in this direction with its Delta Lake ecosystem (as it did into industry verticals). One advantage AWS has over Snowflake's approach is how it is normalizing the data into a specific schema which more easily allows customers and partners to intermix the data as it comes in from various sources. In this case, it is using AWS's and Splunk's new OCSF open security data format announced in Aug-22 [previously covered in "XDR face-off" in Sep-22 in premium].
Data Exchange (aka the data marketplace)
Beyond Redshift catching up to Snowflake on the separation of storage and compute, data sharing, and serverless with on-demand pricing, they have also caught up on data marketplace capabilities. AWS has long had Data Exchange, a marketplace for buying data that is then copied into your S3 bucket. After Redshift Spectrum was added in 2017, Redshift had the capability to query data in S3 data lakes, so Redshift customers could use the data marketplace if they copied the purchased data into S3 and then queried it as an external data lake. But that method is cumbersome, and is not "live-queryable" in that it requires duplicating a copy of the purchased dataset into the customer's S3 data lake (putting the storage costs on the customer).
Last year, they finally announced that Data Exchange was extending into Redshift tables in Oct-21 (which went GA in Jan-22) and into APIs in Nov-21. Allowing the sharing of Redshift tables finally begins to approach the "single copy" secure data sharing capabilities within Snowflake, and it was the first in-place sharing capability in Data Exchange that allows the customer to access the data from the data provider's storage (removing the need for the customer to store a copy of it in their own account). But after a full year of having a data marketplace for Redshift, there are only 85 listings (compared to Snowflake's 1851 listings), so it doesn't seem to be getting much traction. Of course, customers might still be using the S3/Spectrum workaround above to gain access to the much richer core Data Exchange, which has over 3700 listings.
This year, they extended Data Exchange in two ways – both of which are in-place data shares (like with Redshift tables above). Data Exchange now allows the sharing of S3 objects in-place, serving it from the broker's data lake instead of having the customer need to make a separate copy. They then extended this into adding the sharing of Lake Formation tables, which means brokers can now share live-queryable tables from their data lake into a customer's data lake, mimicking how the table sharing in Redshift works. So far it only has 7 listings, all of which are from AWS. This is similar to where Databricks is going with Delta Sharing to share data in Delta Lake, which also allows access to the S3 objects in-place.
Redshift enhancements
One of the bigger advantages that hyperscalers have over data lakehouses like Snowflake and Databricks is their broad portfolios of operational databases, which they can better interlink with their data warehouse and data lake engines to simplify how operational data is transferred in – so the customers don't need ETL services or data pipelines in between. The big focus on Redshift this year was on "Zero-ETL" – eliminating the barriers between Redshift and other services to better allow cross-sharing of data. Their announcement was focused on the new auto-ingest capabilities that help bridge the divide between operational data and the data warehouse. I was pretty underwhelmed by it all given the amount of attention it all received.
They announced new auto-ingest capabilities from S3, which first ingests existing historical data and then monitors the S3 bucket to incrementally ingest any new data that arrives from there. However, Snowflake's Snowpipe ingest service already works this way (and over every hyperscaler data lake, not just S3) – so Redshift is catching up with this feature. And, of course, there isn't the need to move the data from S3 if you are using Redshift Spectrum to directly query the data lake!
The bigger announcement was their new auto-ingest capabilities from Aurora, AWS's cloud-native relational SQL database. Transactional data from the SQL database can auto-replicate into the Redshift data warehouse, to become available for querying within seconds of being written. This removes the need for any ETL processes for getting operational data ingested (including AWS's own ETL services in Glue and Kinesis Data Streams).
AWS is beginning to leverage the fact that it has a wide variety of database flavors that it can better integrate and interconnect, and I believe this is just the start – their auto-ingest capabilities are likely to spread from S3 & Aurora to other operational databases like RDS, DynamoDB, and DocumentDB, which could all continuously push the data to Redshift – plus they could expand it to allow S3 data lakes as a destination. But Redshift is not the first data warehouse with Zero-ETL from its operational databases – Azure added a similar capability called "Synapse Link for SQL" that auto-copies operational data from Azure SQL (their cloud-native SQL db like Aurora) and SQL Server. It released it to preview in May-22, and went GA in Nov-22, right before re:Invent.
These features allow an organization to auto-copy the operation data into the data warehouse (or data lake), which removes the need for ETL pipelines to move the data between data stores. However, copying the data from the outside database into the data warehouse is but one way to work with operational data. Hyperscalers have all been adding federated query capabilities into their data warehouses to allow live-querys into their other operational databases and data lakes, which then avoids needing to move the data at all (or having a duplicate copy of the data in both systems). Redshift has had federated query capabilities into Aurora and RDS databases since 2020, so can directly query into the operational databases as necessary. The other hyperscalers allow the same type of federated queries into their SQL databases, such as how GCP BigQuery allows you to directly query Cloud Spanner (their cloud-native SQL db like Aurora) and Cloud SQL (their managed database service like RDS). So customers have multiple options here, and can use either method based on their needs – but it feels like auto-copy is just creating more data silos.
I want to note that Azure is actually doing both methods (auto-copy and federated queries) across their Synapse Link lines, but to different databases. Long before their new SQL link, they first introduced "Synapse Link for Cosmos DB", which allows federated queries into Azure Cosmos DB (their cloud-native NoSQL document db, like DynamoDB and MongoDB Atlas) from Synapse. They sold it as a "cloud-native hybrid transactional and analytical processing (HTAP) capability", which stores operational data in Cosmos DB in both row-based (transactional) and column-based (analytical) formats, which then allows Synapse to query over the analytical format directly.
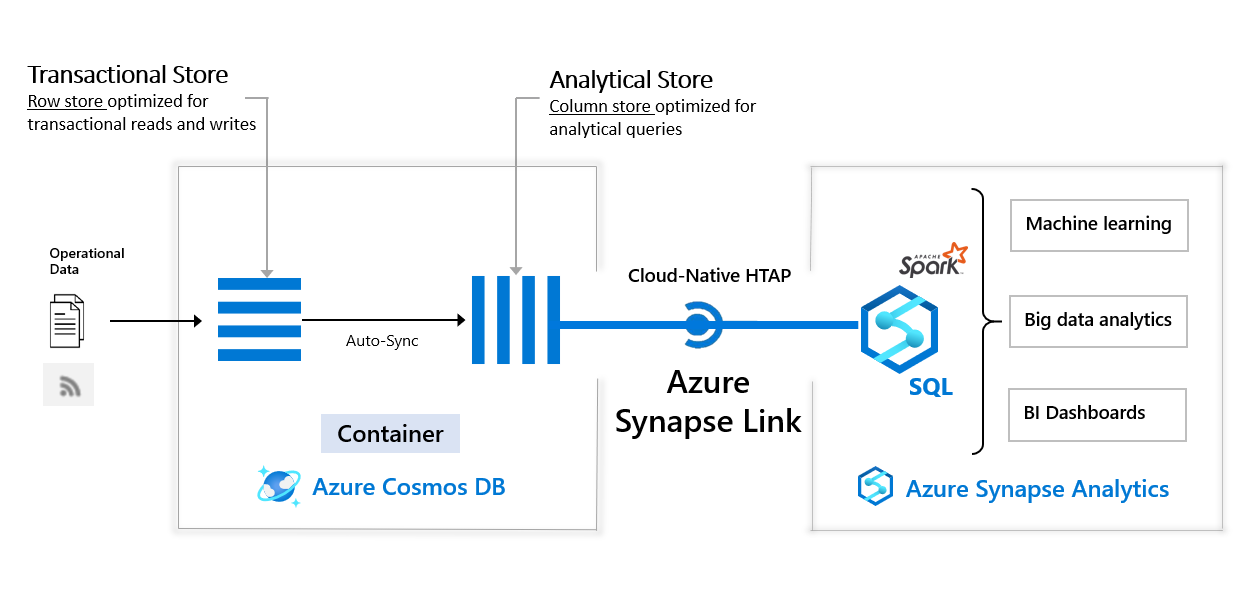
Sound familiar? Snowflake announced Hybrid Tables to power its new Unistore workload at Summit in Jun-22, which uses the same model of having operational data stored in both row-based and column-based tables internally in order to query it both ways. A big difference with Azure's solution above is that Azure does the hybrid tables in their existing NoSQL database, while Snowflake is adding an all-new transactional SQL engine to its Data Cloud (akin to Aurora or Azure SQL). Azure and AWS are both moving towards auto-copy from SQL databases instead of this hybrid table structure.
While Snowflake doesn't have other operational databases in its portfolio like the hyperscalers, they too have moved towards "Zero-ETL" to some degree. In Sep-22, they extended their partnership with Salesforce to allow bi-directional integration with the Salesforce Customer Data Platform (CDP), to allow cross-queries between platforms with no data movement.
Informatica Data Loader
One other announcement in its Zero-ETL efforts was a new direct integration in Redshift for Informatica's free serverless ETL service, Data Loader. This can be used to continuously auto-ingest data into Redshift from databases and SaaS apps like Salesforce and Marketo. This competes with AWS's own ETL services (Glue) and SaaS connectors (AppFlow), yet Informatica won AWS's Data Partner of the Year for North America.
Data Loader can pull data from 30+ connectors to databases and SaaS apps into any of the "big 5" cloud data warehouses (Redshift, Synapse, BigQuery, Snowflake, and Databricks), and Informatica has a partnership with each. Informatica expanded its partnership with Snowflake in Jun-22, announcing a new native (embedded) app is under development called Enterprise Data Integrator to auto-ingest SaaS data into the Data Cloud. [Informatica was mentioned as being one of the first native app partners when the Native App Framework was announced.] It is likely adding those same 30+ connectors in Data Loader in this new native app, but there is no sign of it being released yet.

Streaming Ingest
In addition to the Zero-ETL no-copy methods above, Redshift also added streaming ingestion capabilities from MSK (managed Kafka) and Kinesis Data Streams (serverless ETL platform for pulling data from AWS services). Users previously had to stage streaming data by storing it first in S3 data lakes, then ingesting it into Redshift manually from there. This greatly simplifies the process by allowing direct ingestion of streaming data into Redshift tables, which, per a blog post, can then be queried within a few seconds via a materialized view that updates as data streams in. This is very similar to Snowflake's new Snowpipe Streaming and materialized tables features announced at Summit in Jun-22 (with the "materialized tables" later renamed to "dynamic tables" by Snow Day in Nov-22). [Also see Athena getting the capability to query over MSK below.]
Dynamic Data Masking
Redshift has been improving its security capabilities lately, including adding an integration with Azure Active Directory and role-based access (RBAC) in Apr-22, and row-level security (via RBAC) in Jun-22. These were all long overdue to catch Redshift up to Snowflake's advanced security controls.
Dynamic Data Masking expands column-level security to allow using policy rules to apply masking on the fly to PII and sensitive data, so certain roles cannot see that data, which has become a common feature in cloud-native data warehouses. Snowflake first added dynamic masking (to obscure on the fly) and dynamic tokenization (to obscure at rest) back in Jul-20, which both went GA in Feb-21. Azure Synapse added dynamic masking in Mar-21, and, more recently, GCP BigQuery added dynamic masking (on the fly) and field-level encryption (at rest) in Jul-22. Redshift is trailing here, having just added dynamic data masking capabilities, as one of the last cloud-native data warehouses to add this feature. Redshift allows controlling the masking via SQL, Python, or using Lambda UDFs.
Redshift Spark
There was big-sounding news on how Redshift was integrating with Spark, but again it was a bit disappointing. It was merely a new open-source connector from AWS that allows accessing Redshift data from Spark jobs running on EMR, Glue, or SageMaker analytical services, which is a fork of Databricks's 3rd-party connector that already existed. It seemed like AWS didn't know the best approach for this relatively trivial announcement, so put out both EMR- and Redshift-focused announcements for the same release.
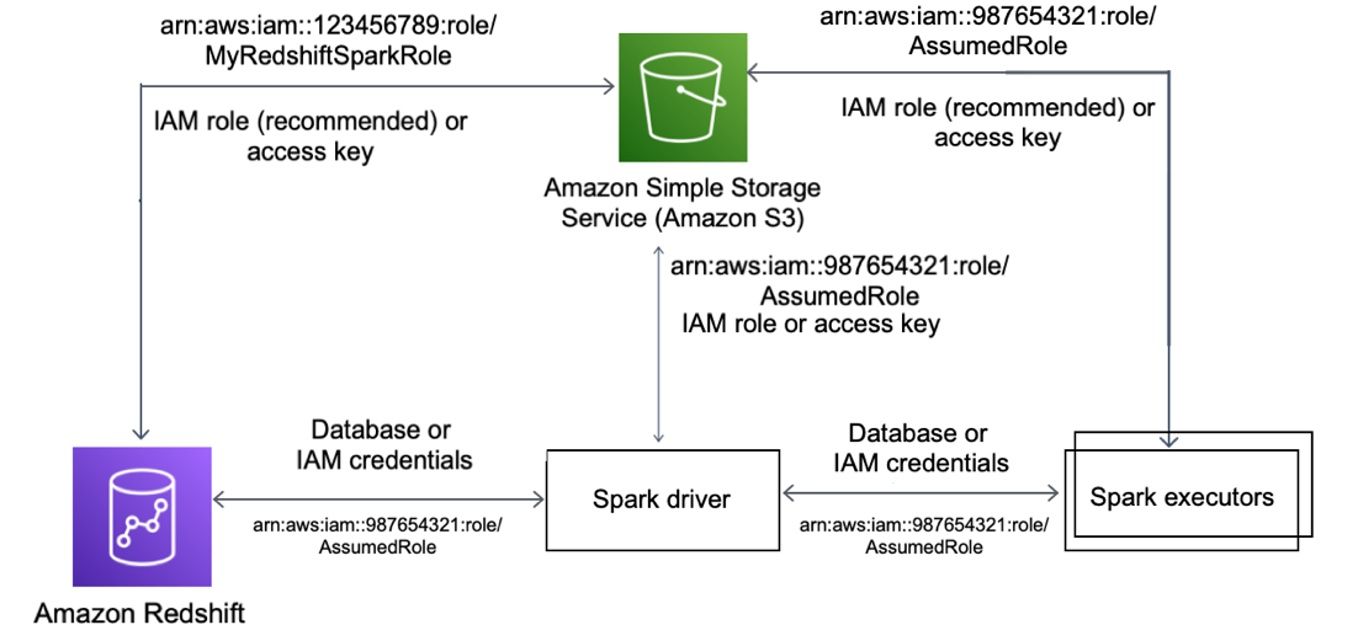
While this simplifies running analytics over Redshift via EMR (managed Hadoop/Spark clusters) or SageMaker (serverless ML), customers can also use the new Spark connector in Glue for both import (source) and export (sink), so customers can use Glue + Spark as a way to do more customized ingest pipelines into or out of Redshift. This is where Databricks is going by allowing Spark over Delta Lake lakehouses, while Snowflake has a Spark connector plus allows using Snowpark for programmatic access to data.

Athena enhancements
Amazon Athena is their serverless analytical service built atop Presto, an open-source federated SQL engine that can cross-query over data lakes, databases, and data warehouses. It serves as a good way to query over S3 data lakes, but can also intermix it with data from all types of operational databases and Redshift. They added connectors in Apr-22 for querying over more 3rd-party data stores like Snowflake, Azure Synapse, Azure data lakes, GCP BigQuery, and SAP HANA.
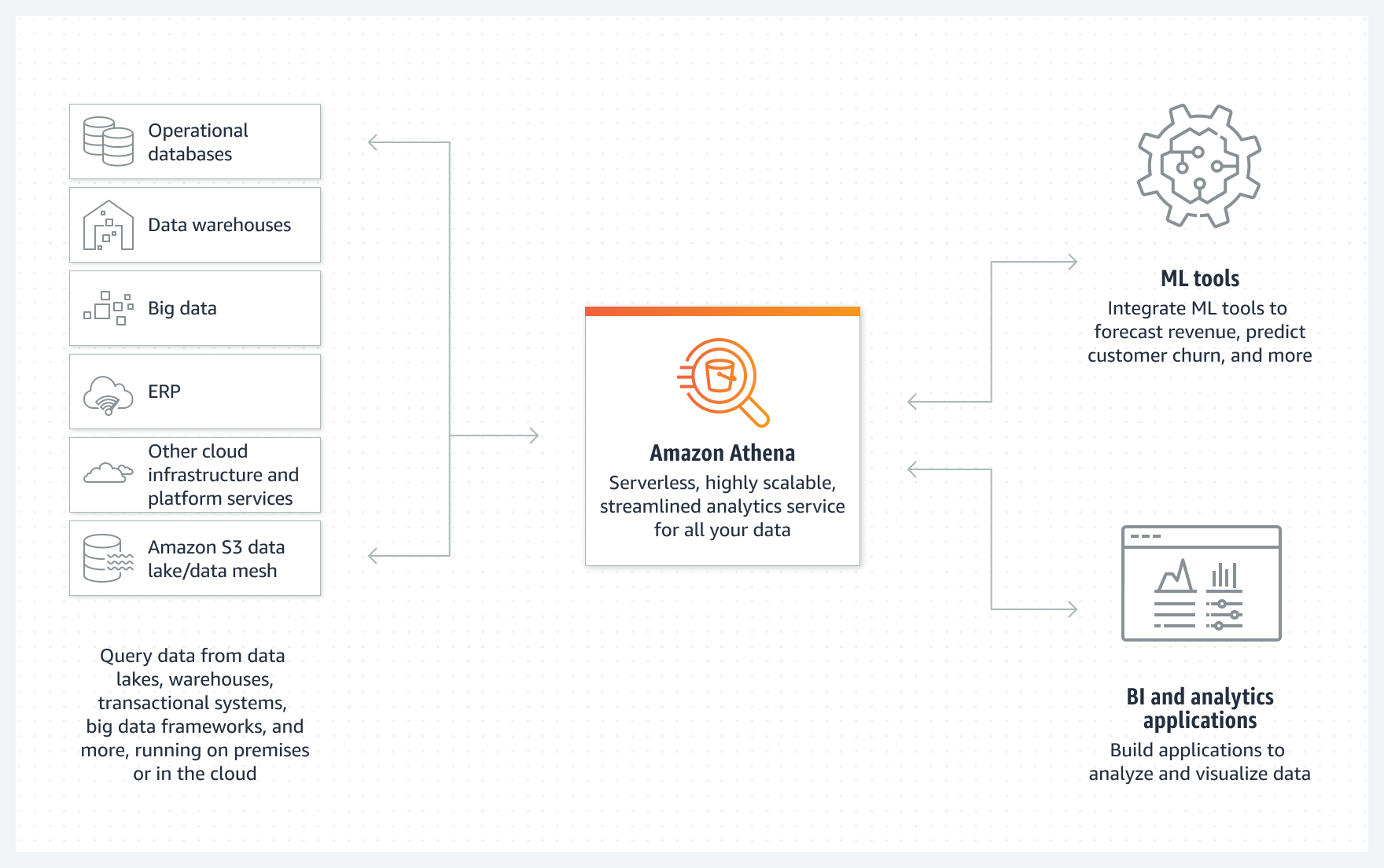
There are multiple ways to cross-query across data lakes & data warehouses via SQL on AWS – which is likely quite confusing for its customers. Redshift can query data lakes directly via Redshift Spectrum to intermix it with data from Redshift. Athena, on the other hand, can query over data warehouses as well as data lakes. It likely depends on where the customer's center of data gravity is as to which approach they will take. [If a customer is data lake centered, Athena is likely heavily in use, and if they are data warehouse centered, Redshift is likely the preferred analytical engine.] AWS is really leveraging the fact that they have a wide variety of operational databases for every need, and can provide a single serverless query engine over them all.

At this re:Invent, AWS is clearly starting to focus more on cross-integrations between these tools, but that isn't enough to make up for the lack of overall vision, and, I feel, just continues to confuse customers with too many choices and too many products to keep track of.
Athena Spark
While the Redshift Spark announcement was merely a new open-source connector for Spark to use data in Redshift, the Athena Spark announcement was much bigger in scope. Beyond the SQL query engines in Athena (both Presto and the forked Trino project), they have now embedded Spark as a programmatic query engine, that can be used to access data via Java, Scala, or Python code instead of SQL. This now marks 4 different analytics services that can use Spark to interact with data (EMR, SageMaker, Glue, and now Athena). Redshift does not have Spark available directly – you have to use another analytical service to use Spark over Redshift data. [No word from AWS as to whether Athena Spark supports the new Redshift Spark connector.]
Athena Streaming Query
Announced just after re:Invent, Athena added the ability to run queries over streaming data in MSK and other Kafka clusters. Similar to Confluent's KSQL, this allows for querying real-time data via SQL, plus allows intermixing data between Kafka streams or with data from any databases or data lakes that Athena supports as a data source. This seems similar to Snowflake's new "dynamic tables" that can query over real-time data coming into Snowflake via the new Snowpipe Streaming capability that was announced at Summit in Jun-22. [Also see Redshift getting the capability to ingest from MSK above.]

DataZone
AWS announced their new Amazon DataZone product, which helps customers create a self-service portal for tracking and granting access to data sets across an organization. This is very similar to data catalogs & governance tools like Collibra or Privacera, as well as open-source tools like Unity Catalog from Databricks for data lake governance. [See The Modern Data Stack for more on data governance capabilities.]
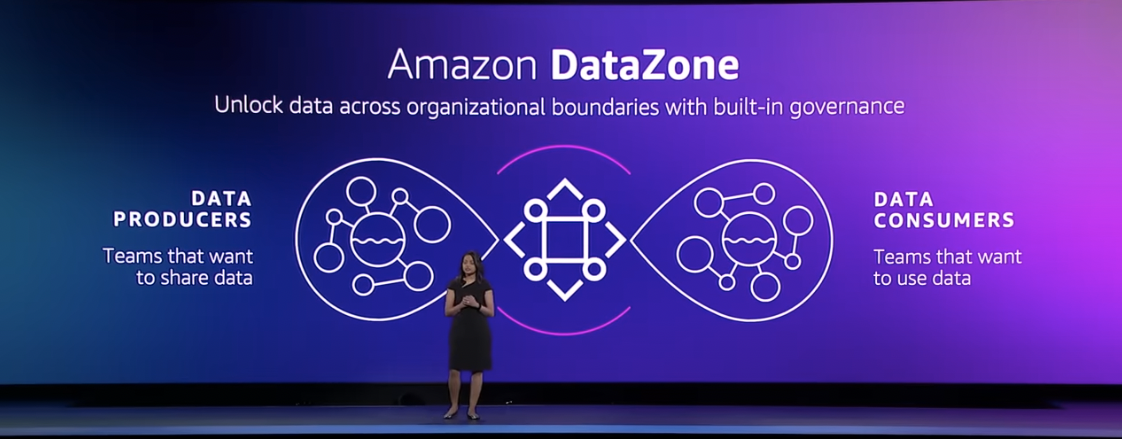
It will integrate with AWS data sources (S3, DynamoDB, RDS, AppFlow) and analytics services (Redshift, Athena, and QuickSight), as well as 3rd-party data platform partners Databricks, Snowflake, and Tableau. Snowflake isn't going this route, instead preferring to rely on partners for advanced data governance.
Data Clean Rooms
As mentioned, Redshift took a cue from Snowflake and added data sharing between separate Redshift clusters in Mar-21. They are finally expanding that into data clean rooms with their newly announced AWS Clean Rooms in preview. This leverages data sharing across data lakes, allowing up to 5 organizations to share data while preserving their data privacy by obscuring or hiding PII or sensitive data. The end result of the joined data gets encrypted and stored in S3, where one party can then analyze it in AWS's analytical tools like Redshift and SageMaker without direct access to the underlying data. For now, AWS released this as part of their "AWS for Ads & Marketing" solutions bundle, which is odd as this feature cross-applies to a lot of verticals outside of ad-tech, including the financial and healthcare industries. It is not clear yet what engine is used to do the internal queries over S3 for data joining and filtering – perhaps it uses Athena under the hood. One major shortcoming of AWS's solution is its limits – it only allows sharing across 5 participants, and only one of those is allowed to run analytics over the joined data. No word yet if it can work across more than one AWS region.
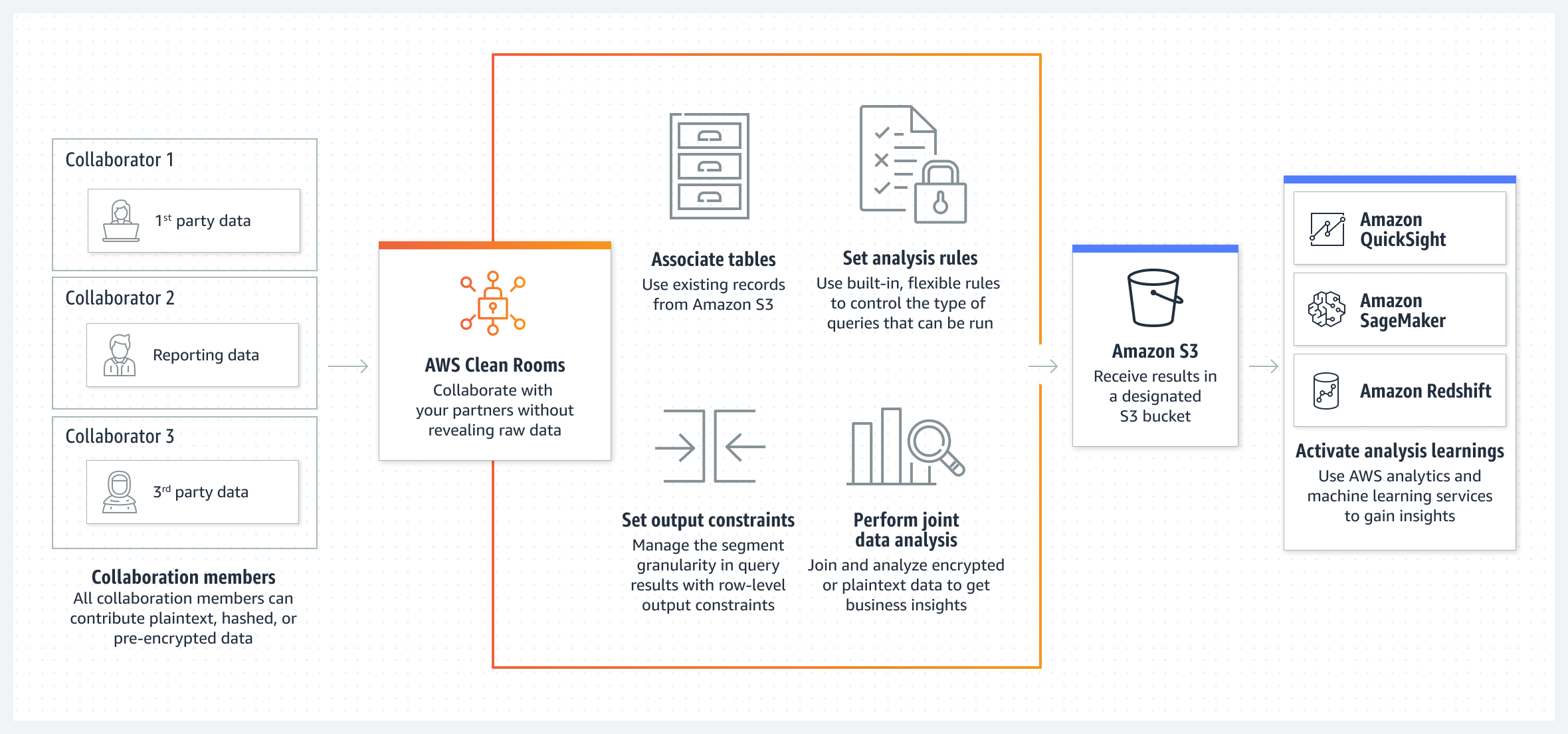
Snowflake has long had data clean rooms as part of their data sharing capabilities, including across clouds and regions. They have been more focused on it lately as a major feature in their Industry Cloud announcements – such as the Media Data Cloud in Oct-21, where it is used to avoid exposing PII when sharing marketing/ad data. Databricks has also announced data clean rooms in Jun-22 over shared data lake tables (powered by Delta Sharing, Unity Catalog for governance, and Spark for analysis). Neither of those solutions limit the number of participants nor how many of the participants can run analysis over the final datasets, so AWS's solution seems quite restrictive.
OpenSearch "Serverless"
OpenSearch is AWS's open-source fork of ElasticSearch in 2021, after Elastic changed its licensing. The not-so-creatively named OpenSearch Service is AWS's service to create managed OpenSearch clusters. This was their last analytical service that hadn't gotten the "serverless" treatment, after Redshift, MSK, and EMR all went serverless over the last year.

However, like many of last year's "serverless" announcements, it was soon criticized as not truly being serverless (see here and here and here and here and here and here), after pricing showed it having a ~$700/mo minimum cost for running idle.
Serverless === scale to zero
— Garret (@imUnsmart) November 29, 2022
What it is right now is managed auto-scaling. Not serverless. There's nothing necessarily wrong with auto-scaling but it isn't serverless and it shouldn't be advertised that way.
Elastic is finally signaling it is moving this same way. In their new product announcements in Oct-22, they detailed how they plan on moving their Elastic Cloud architecture towards serverless (aka moving towards where Snowflake, BigQuery, and MongoDB have already gone) to erase the need to worry about infrastructural concerns (pre-planning the capacity, number of nodes, updating/patching, etc). As part of this, they are moving towards decoupling compute from storage (like Hadoop pioneered, and how Snowflake and BigQuery were architected from the start), which sets them up to allow users to have ElasticSearch work over existing data lakes in AWS, Azure, GCP. While early in these shifts, this is great to see, as I have been waiting for Elastic to move from managed infrastructure towards turnkey managed serverless for few years now.
Streaming enhancements
Amazon has always had several data streaming solutions between MSK (managed Kafka clusters) and its cloud-native Kinesis (serverless data pipelines) – which not only compete with each other, but also with Confluent. MSK is a direct competitor to Confluent Cloud, while Kinesis is a serverless streaming platform that splits itself between Kinesis Data Streams (raw messaging like Kafka), Kinesis Data Firehose (serverless ETL platform for pulling data from AWS services), and Kinesis Data Analytics (managed Flink service for stream processing over Kinesis). They also have serverless data movement services like Glue (ETL pipelines via Python/Spark), Glue DataBrew (no-code ETL pipelines), SageMaker DataWrangler (ETL for ML jobs), and AppFlow (ETL from SaaS apps).
As part of its push into serverless capabilities, AWS announced MSK Serverless in preview in Nov-21, which went GA in Apr-22. Like with OpenSearch Serverless above, the criticisms came quickly that it was not truly serverless, as it was not on-demand and has minimum costs to keep the cluster idle. Confluent Cloud, on the other, has added on-demand pricing (pay-as-you-go) in addition to its regular capacity pricing. [This is after years of them improving the elasticity of Kafka in their Project Metamorphis, in order to make it more cloud-native and move towards serverless. See the Confluent deep dive for more on those improvements.]
AWS MSK Serverless looks cool. Though, I'm surprised you can get away with calling it Serverless when there's a minimum up front cost of +$500/mth just get started. I think most people would consider "scale to zero" a property of a real serverless offering
— Ron Cohen (@roncohen) December 29, 2021
In Oct-22, MSK finally added Tiered Storage to allow using S3 as a storage tier in Kafka. This is adding a feature that has been in Confluent's Kafka since its v6.0 release in Oct-20, which allows for having tiers of storage under data streams for much longer data retention and control over storage costs. AWS is catching up with Confluent here, adding Tiered Storage to divide storage and compute layers to allow Kafka to sit over other data stores. [Also see the streaming ingest from MSK in Redshift, and streaming querying over MSK in Athena.]
As recently mentioned [premium], Confluent just acquired a serverless Flink service to embed in Confluent Cloud, which will allow them to compete directly with Kinesis and its embedded stream processing features found in Kinesis Data Analytics (managed Flink).
AWS Glue already has a Data Catalog feature to track the data sources it is pulling from in ETL jobs, which has now been leveraged in new ways, including their new DataZone data catalog and Clean Rooms products above, and can be used by EMR clusters running Flink. Glue is also adding a new Data Quality feature to monitor the health of ETL pipelines. Both of these are similar to features already in Confluent's Stream Governance product, which beyond data catalog and data quality, also has data lineage tracking. Confluent announced Stream Governance Advanced at their Current conference in Oct-22, a new managed service in Confluent Cloud that wraps up all of their Kafka governance capabilities over Kafka.
Partners
AWS also announced its Partners of the Year at re:Invent:
- Security: Orca Security (global), HashiCorp (NA), Deloitte (LatAm)
- Data: Informatica (NA), Databricks (LatAm)
- ISVs: Salesforce (Global), Splunk (NA)
- Marketplace: TrendMicro (Global), Snowflake (NA), Viz (startup), MongoDB (EMEA)
- Rising Star ISV: PagerDuty (NA)
- Fed Gov Partner: Databricks (global)
AWS called out Snowflake as a top partner in its Partner keynote and partner awards, as well as Databricks, MongoDB, and Confluent – despite having them all being direct competition for AWS's own data & analytics services. All are top partners in AWS's ISV Accelerate program for joint co-selling, where AWS has discovered it can cross-sell ancillary capabilities with these competing infrastructural services, including boosting S3 and Lambda usage, data transfer fees, and private networking needs via PrivateLink. See Confluent's comments on joint co-sell partnerships in the last post, who took part in an ISV fireside chat during the Partner keynote.
Snowflake has been an AWS partner for a long time, and won AWS's Marketplace Partner of the Year for North America. Snowflake's CEO did an interview with SiliconAngle at re:Invent to discuss their deep partnership with AWS. Snowflake has been an AWS partner since 2013, and has been at every reInvent since 2015 – pointing out that 80% of Snowflake is hosted on AWS. This partnership has matured into a huge win-win for each other and for their joint customers, and he pointed out how the joint co-sell has helped close 100s of new opportunities.
Snowflake CEO: "We are very happy with the AWS partnership now. Both companies have come to the table time and time again to expand strategic investment across joint sales, marketing, and alliances – a focused effort to explore new frontiers and drive customer-focused innovation."
He again stated that last year they did $1.2B in co-sell with cloud partners (mostly AWS), and how it will be much larger this year. AWS has been a partner in all 4 of the Industry Clouds that Snowflake has launched over the past year, and has collaborated on multiple initiatives across sales, marketing, and product.
Databricks is also a close partner of AWS, and got several mentions. They won 2 awards at AWS's Partners of the Year, including Data Partner of the Year in Latin America (with ETL tool Informatica winning for North America), and Federal Government Partner of the Year. QuickSight BI tool added support for Databricks's SQL Lakehouse, while their AWS Glue (serverless ETL service) added support for Delta Lake and other open-source data lake table formats (Hudi, Iceberg). Both Snowflake and Databricks are partners in the new DataZone, and can now be queried with the Athena query engine, plus Glue Data Catalog added support for Snowflake and Databricks in their schema crawlers.
Add'l Reading
- Can't really recommend watching them due to their length and amount of filler, but the vital keynotes and sessions are the CEO Keynote, Data & ML Keynote, Partner Keynote, CTO Keynote (DevOps), and a session on Redshift's new features.
- TheCube did video analyses of day 2 (CEO keynote), day 3 (Data & ML keynote), and day 4 (CTO keynote), plus a wrap-up. Plus see SiliconAngle's interview with Snowflake CEO.
After this premium post in Jan-23, I looked at AWS's other announcements in security and DevOps, which was of interest to security and DevOps platforms like CrowdStrike, SentinelOne, Datadog, GitLab, HashiCorp, Palo Alto, Okta, Cloudflare, and Zscaler. Join Premium to read more.
- muji