
Snowflake has a lot of things going for it. I extensively covered their unique position in the industry in my original deep dive back in September, but, since then, have wanted to condense down what I feel are the key points to consider.
Ultimately, it all comes down to how Snowflake has the ability to exponentially scale. In all their events and earnings since IPO, I am finding that this company has a consistent message.
- We are not a SaaS model, we are a consumption model.
- We are not a cloud database, we are a data cloud.
Both of these are extremely important to fully grasp as an investor in the company. Clearly, Frank Slootman grasped it, enough to coax him out of his cozy, sailing-filled retirement in order to take up the challenge of building the likely crown jewel of his success-filled career. Let's go over the clues we have from within their platform architecture & earnings, and how they relate to those two points.
Consumption
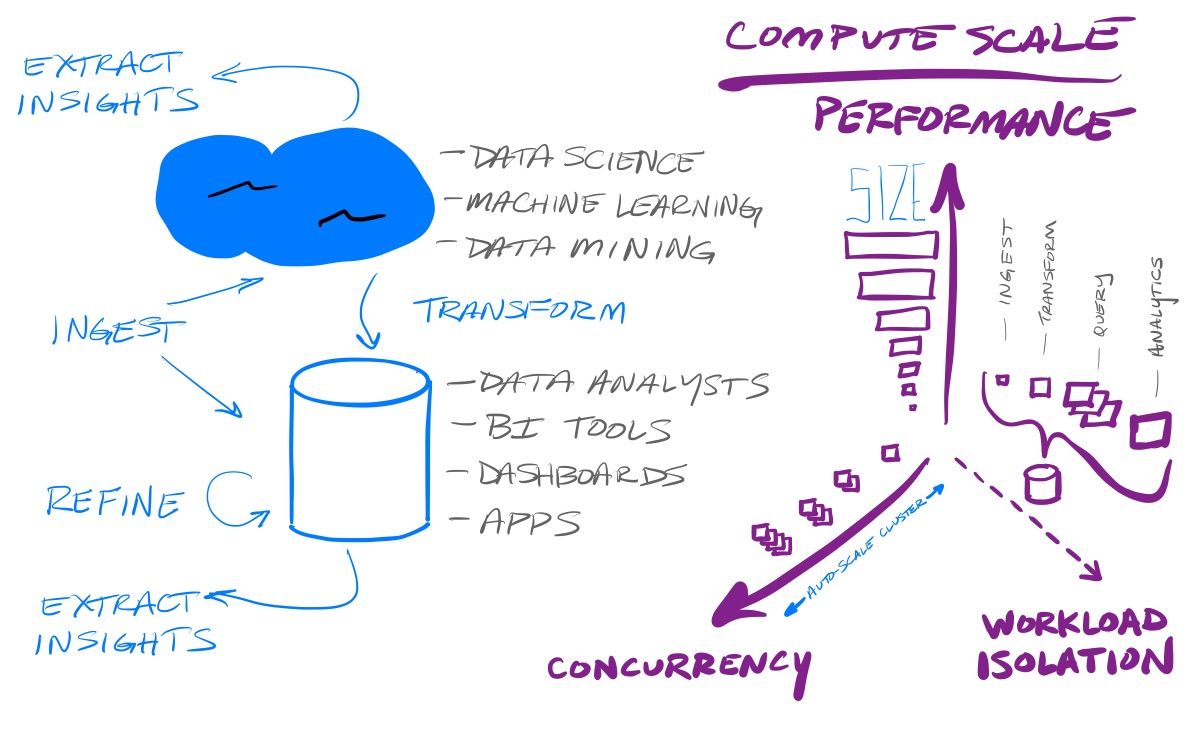
An important decision they made within their platform architecture was the (Hadoop inspired) split of storage and compute. This allows customers an extreme amount of control over their individual usage of the platform. There is a focus on simplicity in using Snowflake – it is a turnkey system that "just works", sitting within the cloud vendor & region of a customer's choosing, and it handles all the maintenance, security, and governance concerns for you. There are very few knobs and levers for a customer to adjust in the settings, however, the separation of compute within their platform ultimately means customers can hone their usage around the costs they want to pay. The control a customer has is in adjusting the size, elasticity and separation of their compute clusters. This allows them to improve the performance (size) & handle more concurrency (elasticity, aka auto-scaling), for the cost they want. If they want to pay less, they can have their queries take longer and have concurrent requests queue up – or, if they pay more, can achieve better performance and/or more concurrency. And customers have that level of control for each workload they need to run, as they decide how they want to pool or isolate the various workloads they do over their pool of data. Low-compute ingest tasks can be handled by one compute cluster, while heavy-compute querying is handled by another.
Price vs Performance
This tuning of compute that any customer can do, over their highly efficient underlying storage architecture (compressed micro-partitions) and incredibly performant query engine, leads to achieving high performance for low cost. This is backed up by research published by Fivetran, an ingest tool that works over all major cloud data warehouse platforms.
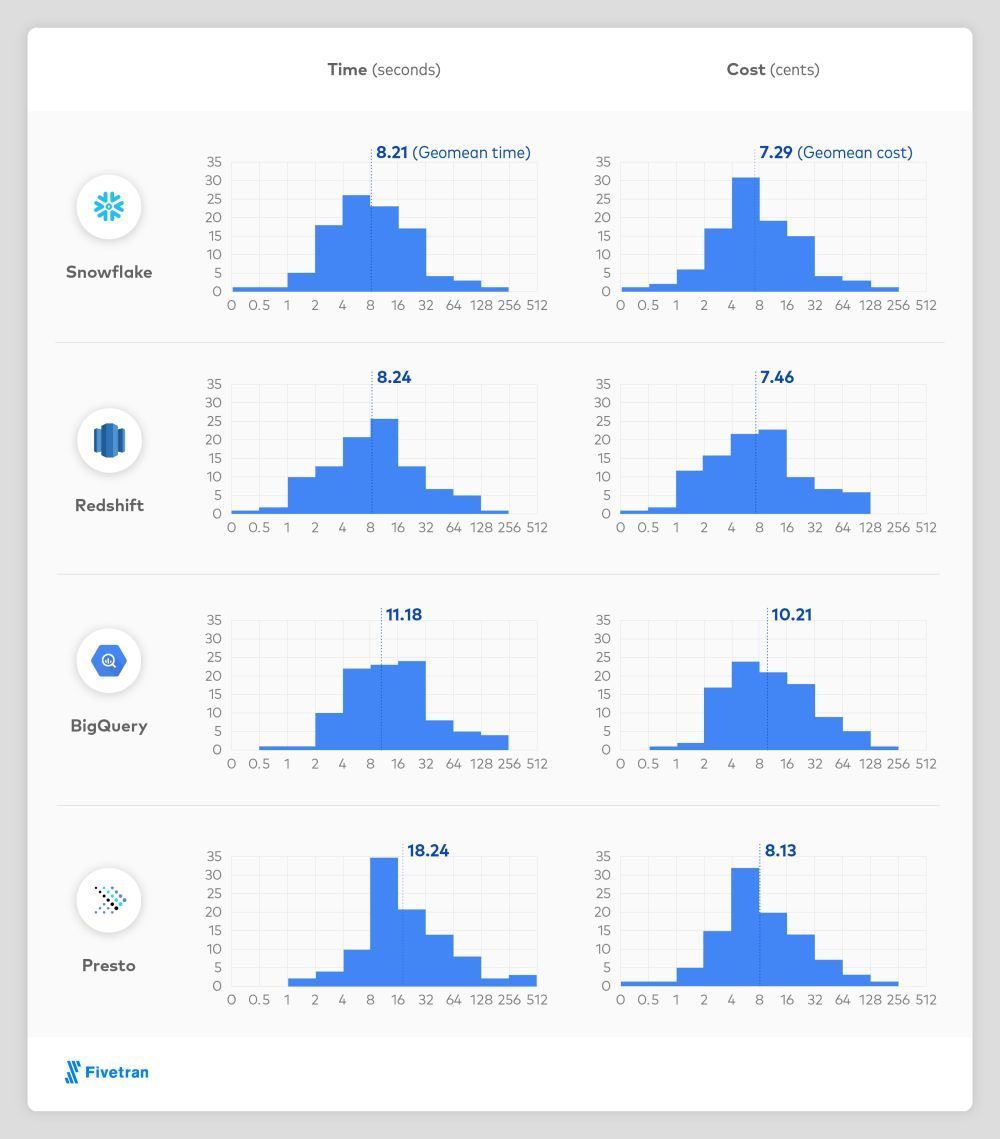
A Growing Ecosystem Driving Compute
Consumption is everything for Snowflake. They admit that storage costs are basically pass-through costs – they want all the data to permanently sit within Snowflake's platform, and not have the customer worry about the long-term costs of that. Their success (and profits) are on the compute over that data. In order to drive consumption on both ends of the data workflow – ingest and analytical queries – they want to serve as an ecosystem that works with every partner, in order to drive further consumption. They aren't likely to build their own advanced ingest and analytics capabilities, as they have a wide variety of partners better focused on those problem areas. Instead, they solely concentrate on driving more compute.

A Vision into Usage
Knowing that this is not a SaaS recurring subscription model, it is amazing how much vision they clearly have into their platform's usage trends. They have claimed that net retention will remain above 160% for the remainder of this year, and that FY22 revenue will grow 84-87%. [For a usage-based pricing model that can fluctuate based on every individual customer, I find this astounding.] As of Q122 in May, their RPO grew +206% compared to platform revenue at +110%. Customers are pre-purchasing a massive amount of planned consumption. And most of those new customers flowing in (at +67% YoY) aren't even contributing yet! Management has stated that it takes a good 6+ months for newly onboarded customers to fully grow into their planned usage of the platform. Customers gained today will likely not show up as revenue until 2 or more quarters later.
CFO on Q4 earnings call: "...if you're doing a legacy migration, it can take customers six months-plus before we start to recognize any consumption revenue from those customers because they're doing the data migration. And what we find is -- so they consume very little in the first six months and then in the remaining six months, they've consumed their entire contract they have. And when we do a renewal, that's when most customers are doing the multiyear renewals once they've proven the use case on Snowflake."
Compute's Odd Dynamic
Even though consumption is everything for Snowflake, there are two necessary design decisions within their platform that reduce a customer's consumption. First off, as a managed turnkey system, they tightly control how the customer's compute clusters start and stop, and grow and shrink, as the usage demands. The compute clusters turn off when they are no longer being utilized, keeping them inactive until usage resumes. And the cluster can grow or shrink as it auto-scales based on the number of concurrent users. If a customer knows that a workload will have variability in how much it is used at a given time, they can set bounds for the cluster to auto-scale, in order to grow to handle an increased load that suddenly appears, then shrink when that load wanes. All that leads to a highly honed platform that assures the customer it isn't paying for idle time, ultimately reducing the amount of compute needed, and, subsequently, the customer's bill.
Beyond that, they continue to iterate on improving the performance of their platform, in order to differentiate their service over the competition. They charge by compute time, so performance improvements mean that customers ultimately pay less and less for the same action. Snowflake announced (during Data Cloud Summit) that over 2020, performance improvements made 3/4 of queries more than 50% faster than the year prior. So they grew platform rev 116% last Q even after making their customer’s compute way more performant.
Over 2020, performance improvements by $SNOW made 3/4 of queries more than 50% faster YoY. So they grew platform rev 115% last Q even after making their customer’s compute way faster.
— muji @ hhhypergrowth (@hhhypergrowth) February 23, 2021
I (very roughly) calc this to mean it would have been 142% growth w/o those improvements.
I roughly calculated that they may have seen revenue growth of 142% without those improvements – but that made-up number doesn't matter. Snowflake has made the conscious decision to continually improve its platform to keep its customers happy with its high performance and low cost. They are focused on the long term stickyness of their platform to the customer, not the short term gains from today's usage. And while doing so, they are also improving their platform's internal efficiency, lessening the "infrastructure tax" they pay to the underlying cloud vendors (as seen in the rising platform gross margins, +600bps YoY to 72%). [This is a metric I watch closely on usage-based platforms.]
Driving Entire Platforms
One of Snowflake's potential usages is how analytically-driven application platforms can be entirely built upon it as a DBaaS (database-as-a-service). One such company is Seismic, a SaaS service for sales enablement. They gave a presentation during Snowflake App Week in April 2021 on converting the core of their platform from Azure SQL to Snowflake. In doing so, they reported a 1000x improvement in analytical queries (to be fair, their prior database wasn't analytics-oriented), at 40% of the cost. So now, as Seismic succeeds, it drives more and more compute into Snowflake.


Another company built on top of Snowflake is Lacework, a cybersecurity service that does all the data collection and analytics within Snowflake. Snowflake liked them so much, in fact, their Venture arm invested in them. So again, as Lacework succeeds, grows its customer base and the amount of data it analyzes, it again drives more and more compute within Snowflake.
In February, BlackRock & Snowflake both announced that BlackRock's new Aladdin Data Cloud is built upon Snowflake. I expect more and more customer-based partnerships like this, where Snowflake is providing the underlying architecture for new platforms to be built upon. This is the "Data Applications" use case that they tout in marketing about workloads. Using Snowflake as the underlying architecture allows these applications to have a feature set that are not available in other cloud-native data platforms, like live queryable Data Sharing with the app's users & partners, and being able to intermix those queries with their own data (if they are Snowflake customers), plus additional enrichment from Data Marketplace.
They held a Snowflake App Week in April 2021, to heavily focus on using Snowflake as the underlying data architecture for new data-driven applications. The message was that the platform allows a fast time-to-market, letting developers focus on app development not infrastructure, all on a platform that can deliver fast & reliable customer experiences at scale. App platforms from BlackRock, Lime, Twilio SendGrid, Blackboard, Instacart, Seismic, Lacework, and Rakuten, have been built over Snowflake. In June, then extended all this further with a new announcement for their Powered by Snowflake initiative, a new partner program for apps built atop Snowflake. This provides these app platforms access to resources in Snowflake, like technical expertise, plus gives them a say in directions of new features. Adobe spoke at the Snowflake Summit about how their Adobe Campaigns, debuting next month, was built upon Snowflake. The decision factors for them were speed, scale, and cost – and Snowflake won on all. It allowed Adobe a quick time-to-market, and ultimately gave them a differentiated product that they state will unlock more use cases from here (hinting at allowing customers to access live queryable data via Data Sharing, as Seismic does).
Data Cloud
This centralized data store eliminates "data silos" within an enterprise, so customers no longer need to maintain separate copies of the data across different systems – there is now a single source of truth for that business's view into its own operations. It doesn't have to copy the data into different systems that various groups within the organization each use; all the segments within an enterprise can all be working on the same single pool data at the same time. And of course, the customer can use the security & governance features within Snowflake to tightly control what employee can see what data within. One can assume that these customers will do well, and will expand their pool of data and the usage over it as they succeed and grow as a business. But as I have said before, even just the passage of time will cause the overall amount of data to expand – the metrics a customer collects this month will need to be collected next month.
Data Sharing
But beyond having a single source of data for their own internal use, Snowflake allows customers to share any part of their pool of data with others on the platform. A business can put a secure fence around a portion of the data (through security at the table, row, and column level), and then share it with someone else. The user they share it with, in turn, can directly interact with the live, queryable data, including intermixing it in queries against their own pool of data. This eliminates a big pain point in data sharing - there is no need for exporting & importing, of pushing files to FTP sites, or exposing internal APIs or databases to external users. Snowflake's service layer handles all the security and governance over your data, to assure that each user you share with can only see and query what they are allowed to. All those queries against the shared part of the data, of course, means more compute, with either the original customer paying for it (creating what they call a "reader" account), or, having the shared users being billed on their own existing compute cluster.
When you expand out on what is possible with this capability, you can begin to envision a completely new paradigm. Groups of companies can be creating live, queryable shared pools of data between themselves. This would allow bi-direction data flows between those groups, where all parties could be writing into or reading from a shared pool as needed. This is where you can begin understanding their overall "data cloud" vision and the network effect it enables – Snowflake can become a global mesh of data, with every customer having their own private pool of data, but with all kinds of shared pools between themselves now possible. And as the data changes and grows, every user with access to that shared data sees the updates in real-time. This allows for sharing data between partnerships, consortiums, and joint ventures, but beyond that, enterprises can also share data directly to their own customers! Seismic, the company mentioned before, not only has their clients using its data application that sits over Snowflake, but they also share live, queryable datasets with their clients, to use directly as if it were their own data.
Data Marketplace
Expanding upon data sharing, Snowflake also provides a Data Marketplace capability that allows for the publishing of free or monetized data sets. Take those security & governance features above, and any enterprise can now carve out a part of their pool of data that they wish to share with the public. This creates a platform perfectly geared for data brokers – companies that are in the market of selling data to gain insights from. Data brokers can maintain complete control over the data they publish to subscribers, and that published data is always up to date and directly queryable. Like before with data sharing, subscribers can intermix the published data into queries they run against their own pool of data. Examples of popular datasets include COVID-19 tracking, weather, geolocation lookup, economic trends, and business profile data, coming from data brokers like S&P500, IQVIA, FactSet, WeatherSource, and the State of California.
Chief Product Officer at S&P500 Global Market Intelligence, in an interview: "What we’re focused on is productizing data — creating new data-driven products, linking all of that together and combining it so that clients can get incremental value. And then also making it available to clients in the way they want to consume it. And that’s what we’ve really done with Snowflake, which is make all our data on the S&P Global Marketplace available through the Snowflake distribution and couple it with Snowflake compute power, so that clients can take advantage of bigger data queries, and all the advantages of compute power, so that they can study and research and analyze and evaluate, not just our data, but our data in combination with their own data."
And beyond being a platform that supports data brokers (who are in the business of publishing data), this also enables enterprises to anonymize and publish datasets from their own pool of data already on Snowflake, in order to find new ways to monetize their assets. Snowflake published a guide on how to go about it, and Foursquare (the social-media oriented mobile "check-in" app), is one such company finding new ways to monetize their data and pivot their platform, publishing a dataset of 95M+ retail locations.
Data Services
Snowflake added a new category of "Data Services" to the marketplace in November 2020.
Data Services on Snowflake Data Marketplace – Snowflake Data Marketplace enables any Snowflake customer to discover and access live, ready-to-query, third-party data sets from more than 100 data providers, without needing to copy files or move the data. Announced today, the marketplace now also features data service providers. A Snowflake Data Marketplace user can create live, secure, and bi-directional access to the data they want a service provider to perform a range of data enrichment services on, such as running risk assessments on a customer’s data, augmenting a data set with behavioral scoring, or simply outsourcing the more advanced analysis such as predictive and prescriptive data analysis.
Beyond data sharing and the marketplace, Snowflake is allowing a new breed of data services to emerge to provide services around data enrichment & analytics. New programmability features enable all kinds of interconnectedness within Snowflake's platform to allow any customer to act as a 3rd party service. You can build services to do data cleaning & enrichment tasks, as well as performing far more complicated analytical services, like risk assessment, behavioral scoring, or fraud detection. A service vendor (within Snowflake) can now expose their analytical or enrichment services within the platform itself, so that their customers (also within Snowflake) can call into it to process that data at scale. Snowflake illustrated the possibilities with the following bi-directional sequence:
- A customer can expose a subset of data to vendor (via data sharing), such as a table of customer records.
- The customer would then trigger the vendor to process it (via external function).
- The vendor would run its analytics over its data in Snowflake (via embedded analytical code in Snowflake's compute, or using some externally run method).
- The vendor would then share back results (via data sharing) so that the customer can merge back in the results as needed.
What will power this new breed of data services built upon Snowflake? The programmability features that are being extensively added, like External Functions and Snowpark.
Programmability expanding
They have been creating more and more ways for customers to utilize their platform in a deeper way. These features are not about creating new ways to profit – they are about driving more query usage (the key to Snowflake's success), with the huge bonus of greatly increasing the stickiness of their platform. These features (and many others around governance and performance improvements) were covered heavily in the Snowflake Summit in June, and recapped on Investor Day.
Right now, you can only create stored procedures (snippets of logic you can access from SQL) using embedded Javascript. They announced Snowflake Scripting in order to use SQL for more advanced logic as well, expanding their SQL command set with new logic capabilities (if/else, loops, case statements) and file handling capabilities (using underlying S3/Blob storage exposed to that the user). It is now in private preview. (This provides the underlying file handling capabilities needed for Java UDFs and Unstructured Data, discussed further down below.)
SQL API is another way they are extending the SQL capabilities, allowing users to bypass needing a native client driver for their programming language of choice, and instead use a REST API to interface with Snowflake. This allows for more easily embedding query calls within external apps, like data pipelines & orchestration tools. It is now in public preview.
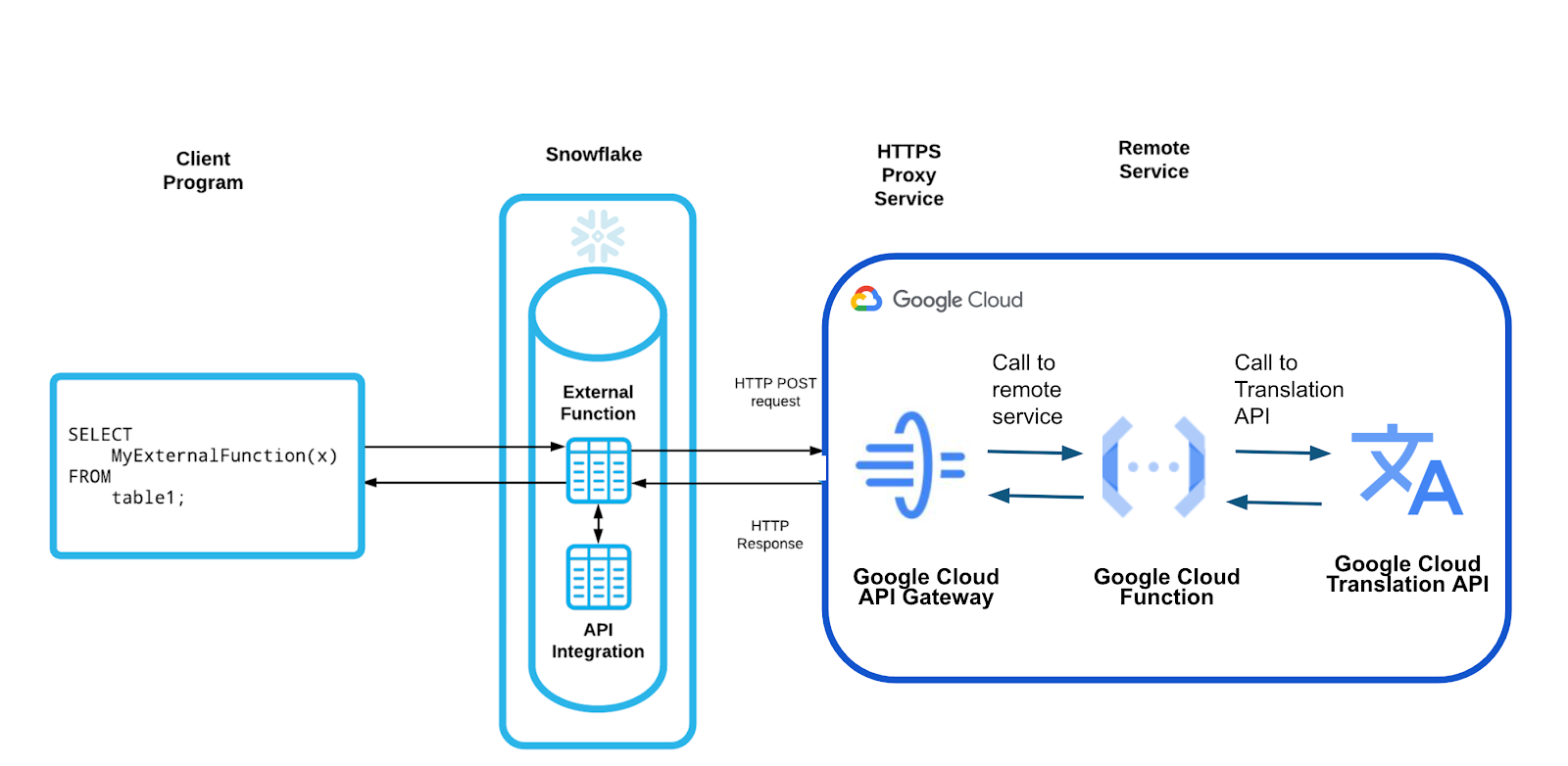
External Functions were announced in June of last year on AWS, and they since added Azure. It went GA in February, and in April they added GCP. This allows for creating an inline logic function that can be directly used in SQL queries – typically for data enrichment, like cleaning, geo-coding, or analytical scoring. You can set up a serverless function & API gateway in AWS, Azure, or GCP, and then in hook up the ability to call it from Snowflake. From the serverless function, you can take advantage of any other service in those cloud providers – giving customers the ability to customize their business logic within Snowflake in a very easy to use way. For now, these functions are scalar and only work upon one row. They announced they'll be extending it greatly from here, such as expanding it to work over entire tables or groups of rows.
These programmability features continued to evolve, and Java UDFs (User Defined Functions) and Snowpark proceeded to steal the show at Snowflake Summit. These features allow for data engineers, data scientists, and app developers to more directly code their applications into the Snowflake platform. The CEO, later on Investor Day, highlighted that these new features are the most important ones to take note of. Snowflake has now created the ability to run logic & applications inside Snowflake AT NO COST. (Once again, this is all about driving more query compute.)
Java UDFs take the logic capabilities exposed by External Functions, and allows for running it all inline within the compute clusters, via a highly secure sandbox that runs on each node of a customer's compute cluster. You can now create a compiled Java application (jar), enrich it further with open-source or 3rd party capabilities (import other jar files), in order to provide custom logic that is again accessible directly inline in SQL queries. They also allow developers to create External Functions and Java UDFs inline right in SQL (without uploading a jar), but these new UDF features really expose the ability to have deployable applications with more complex capabilities than serverless functions allow for. In creating the sandbox for Java, they focused on security combined with ease of use – customers should be able to directly migrate app logic into Snowflake, with minimal changes to code (if any). Again, this can be used for all kinds of data enrichment and analytical capabilities. For one, developers can now directly embed decision making by deploying ML models directly into Snowflake.
Snowpark is the feature for tying all this programmability together over querying capabilities. It provides an SDK for interfacing with Snowflake through the use of DataFrames, a concept heavily used in Spark that provides an API-driven method for database querying (instead of SQL). Under the hood, in Snowflake, this all turns into SQL queries. Snowpark will support Scala first, then Java immediately after -- soon followed by Python by end of year. For now, a developer must run their applications directly on their own environment, but going forward, Snowflake is creating the ability to embed Snowpark-based applications directly into Snowflake compute by making it an inline stored procedure. This will also tie more deeply into their Tasks system, to be to control how that embedded application run and be scheduled. Snowpark ties very deeply into Java UDFs, and allows for creating them on the fly, lessening the steps needed to deploy them. I expect Python UDFs to be coming eventually too, since this feature ties so closely to Snowpark, and from there, Spark's method of data querying via DataFrames.
I was hoping to see explicit mention of Spark features (in a direct move towards Databricks), but that has not yet occurred. But the clues are all there (having Scala/Java/Python support over DataFrames), that Snowpark is designed to replace the need for Spark use. I believe the focus on Snowpark is eliminating the need to push data enrichment and analytical services to outside compute platforms like Databricks. Snowflakes wants to become a full-service COMPUTE platform for data-driven applications, not a mere database. You will soon be able to embed entire applications directly within its Data Cloud. Snowpark is the foundation for building new solutions (or more closely embedding with outside platforms) for that new Data Services category in the Marketplace (announced in Nov-20 with Snowpark), as now, entire applications can be built into Snowflake for data enrichment and analytics services. I expect the Marketplace to further expand, to allow signing up and having usage-based pricing over new Data Services that emerge from all of this.
They added a Snowpark Accelerated Program in order to give partners wanting to use these features access to insider tech experts, and improve their exposure with customers. Initial partners building in Snowpark (or already have built) are a who's-who of data & AI services, including Alteryx, Streamsets, Monte Carlo, H2O.ai, Dataiku, Matillion, Rivery, Informatica, TIBCO, Talend, and many, many more. These platforms are beginning to more deeply embed within Snowflake. The possibilities of the Data Cloud are just beginning.

Snowflake is also adding Unstructured Data capabilities, so that this Data Cloud can corral (and subsequently secure, govern and share) any associated files that an enterprise needs to track, like PDFs, images, audio/video, and the like. They believe this will tie in nicely with the use of External Functions, Java UDFs, and Snowpark, in order to be able to process those files to extract out usable data. They demoed how to extract details from a PDF invoice using OCL libraries, using both an External Function (via AWS Lambda) as well as as Java UDF. They mentioned they will be extending Snowpark to more closely work with inline files. Data Services will soon emerge around processing unstructured files to extract the valuable data within.
Cloud-Agnostic, Global Reach
Over all the above platform features lies the fact that Snowflake's platform has global reach. Their platform can exist upon on any region within the big 3 cloud vendors. While a single customer's dataset is stored in a single region with a single cloud vendor upon signup, behind the scenes, Snowflake can replicate that pool of data to any of their supported cloud locations around the globe.
If an enterprise just has a single pool of data for internal use, this enables spreading that pool of data to other regions (for global reach), or other cloud vendors (if different segments of your company use different vendors). Either way, you can be sure that Snowflake's platform can live right next to any other cloud services your enterprise uses (like ingest tools, data services, or analytical tools).
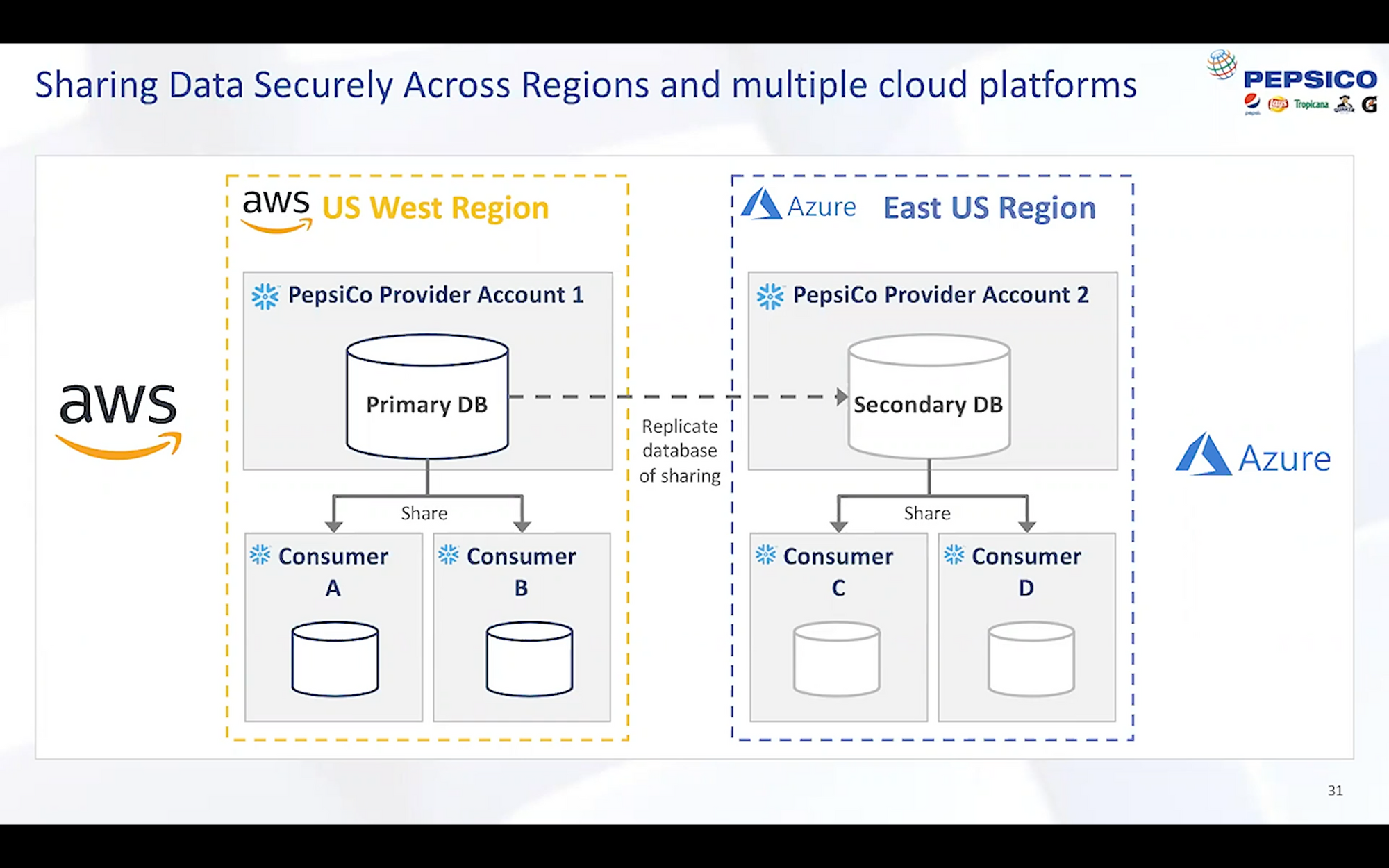
And if you are sharing pools of data between partners, what if one is in London and the other in Hong Kong, or if one uses AWS and the other Azure? The same pool of data can be replicated between those regions or vendors and be shared by users coming from any of those cloud locations. You can use external data enrichment services from any of those cloud locations too, and be sure your data changes show up in all the other locations. To the customer and all its shared partners, it's a single pool of data, regardless of where you are on the globe or what cloud vendor you are utilizing; Snowflake handles all the replication complexity internally. If you are publishing data to the public marketplace, again, that data set lives everywhere and anywhere the customers will be. A published dataset can be available to AWS, Azure and GCP customers in any region. While they only support a set number of cloud regions at the moment across the big 3 clouds, I only expect this to grow from here, especially as Snowflake continues to grow internationally.
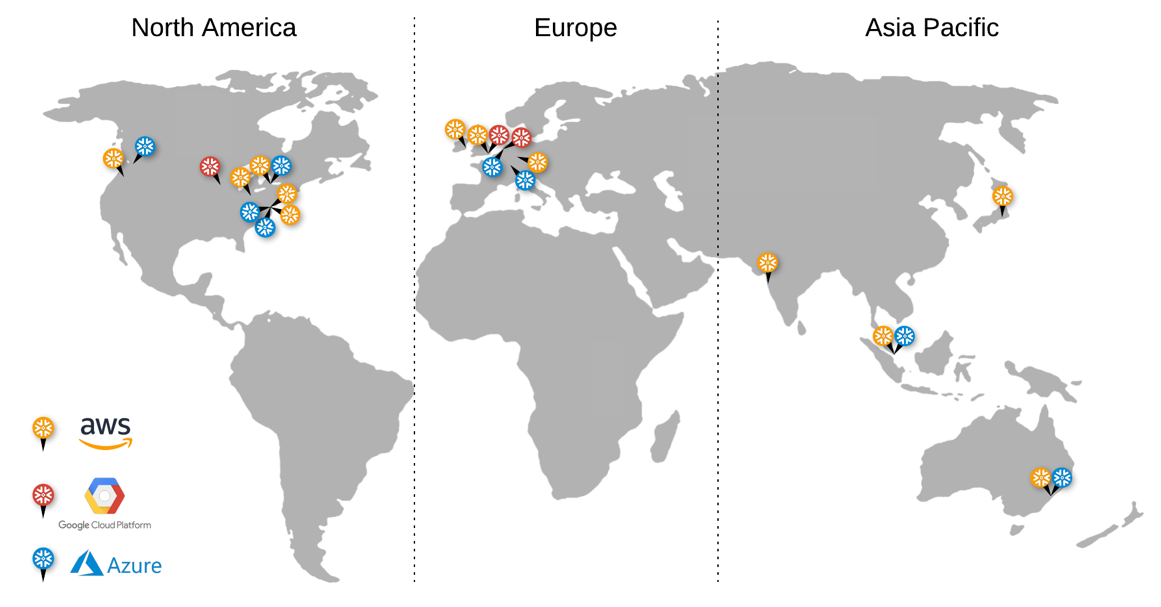
This is not a feature that the cloud vendors (the primary competition) have any incentive to replicate; their prerogative is to keep their customers on their platform. This means Data Sharing and Data Marketplace, in particular, will remain features unique to Snowflake. Pure play competitors might eventually go this route, but Snowflake has the lead in building the network effect necessary to make these features worthwhile.
Scale upon scale upon scale
Ultimately all those clues above tell me that this company has 3 levels of scale that will continue to swirl around each other to increase the amount of data within this platform, and the usage that is done over it all.
Scale 1: Each individual customer
The 1st layer of scale is how each customer can individually scale their particular needs on their own, each having their own compute needs around ingest, transformation, refinement, and querying of the data. Each of those workloads can be a separate compute cluster, and each can be sized and scaled to the needs of that load. For instance, ingest might be a small, always running, compute cluster to ingest new data in real-time, while BI tool queries might require a medium-sized cluster that can auto-scale as concurrent usage rises and falls, and that only runs during business hours.
Scale 2: Platform expansion
The 2nd layer of scale is the fact that the usage of the platform grows with data growth of existing customers, plus the addition of new customers and data apps built over the platform. However, the data sharing, data services and data marketplace usage from those customers also provides other directions of growth, and in turn, create a massive network effect that adds more customers and more compute. Those new customers will then do the same things, and scale and grow into their own data usage.
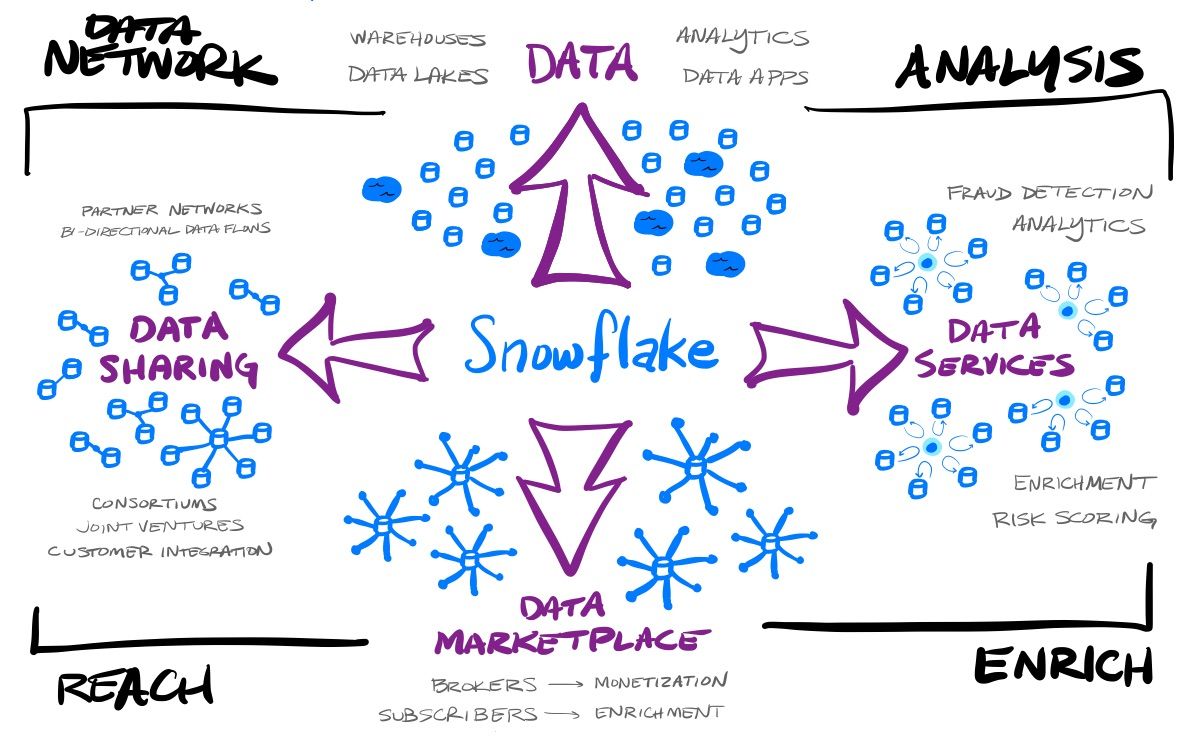
All of this means that any individual customer can use Snowflake to create a data network between themselves and partners, customers, data providers, and data services. The value these features add for customers makes Snowflake an extremely sticky platform to use. Not only can they use Snowflake to create a data warehouse, data lake, or a database driving their data applications (what the competition all provides), but can then share parts of that data with others, create bi-directional shared pools of data, can enrich their data from the marketplace or data services, and can offer datasets or services themselves on the marketplace.
- Data Network - a customer can share and interexchange data with others, or create specialized apps over their data.
- Analysis - a customer can perform analytics themselves via tools that work over Snowflake, or can use specialized interactive services that are built on top of the platform.
- Enrich - a customer can enrich their data set with 3rd party data, either from the marketplace, or from specialized interactive services.
- Reach - a customer can share out its data as needed, with either partners and customers, and can share it with the public as free or monetized data that can be subscribed to.
Scale 3: The global reach
The 3rd layer of scale is how the cloud-agnostic platform sits atop all cloud vendors, in any region across the globe (as customer usage demands). The global reach of the platform can serve up customer data from a data center near to their location, further increasing the performance of this platform. All the above gets magnified as companies expand the reach of their data into new parts of the globe. Data Sharing and Data Marketplace, in particular, are greatly enhanced by this feature – you can now easily cross cloud vendors and have the platform live near to where the partners and subscribers are (or rather, near to where their infrastructure lives that is making use of Snowflake).
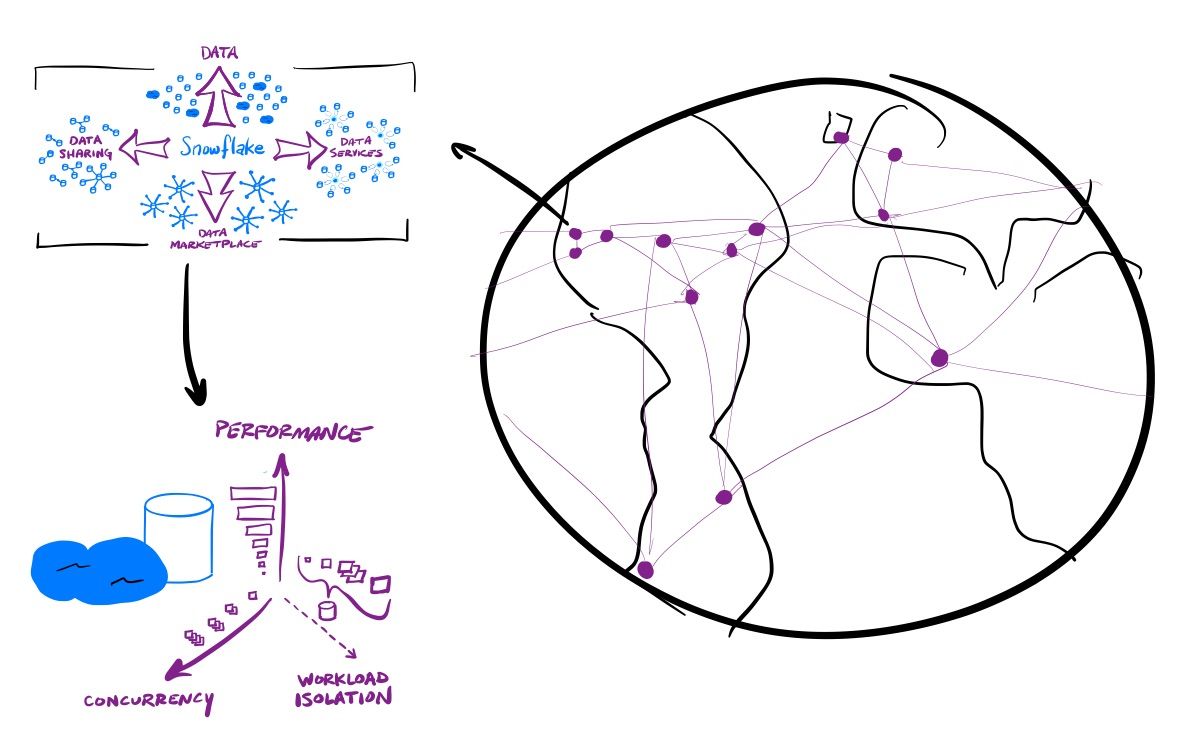
I'm not going to have any answers for valuation concerns with Snowflake. All I know is that this is an extraordinary company that has the ability to scale up its success on 3 intertwined levels, in multiple directions. I believe this means compounding scale, and, for the company and its investors, a growing hurricane of exponential success. Meanwhile, it feels like the primary competition is still catching up to the 1st scale (compute vs storage) in their architectures, and are focused solely on how a customer's data will ever grow (but one direction of the 2nd scale).

Add'l Reading
In A Snowflake deep dive from September 2020, I covered the history of data warehousing, then various usage possibilities & the extensive feature set within the Snowflake platform. I later spoke about it on the ARK Invest podcast in December 2020.
VentureBeat published an interview with S&P500 Global Market Intelligence, that gave interesting insight into what data brokers are looking for today in a cloud-native data platform - one that can provide interactive datasets to their globally dispersed customers.
Fivetran's 2020 Data Warehouse Benchmark proved the low cost for high performance that Snowflake promises. It's an interesting cross-view into the competition from major cloud vendors, plus Presto, which provides query layer over a network of existing databases.
I originally published this post in my Premium service two months ago, plus had additional coverage on Snowflake in June on the latest earnings and Investor Day as well as recent developments with Snowpark. There will be more coming from HHHYPERGROWTH on Snowflake later this summer, including a comparison of platforms between Snowflake and Databricks, a company likely to IPO this year. I also write extensively about Zero Trust, SASE Networks, observability, edge networks, and much more. Sign up!
- muji