
The world is awash in data, and it ever grows.
Companies have to measure and track everything: data from sales, data from marketing campaigns, data from the supply chain, data from customers, data from partners, data from finance, data from infrastructure, data from software teams, and data from every SaaS application & service that their business is built upon. These tend to be collected in separate data silos, where each team within an organization is keeping and accessing the data that pertains to them.
Siloing makes it impossible to see across the entirety of the organization, so enterprises must ultimately create a centralized data store to contain all this disparate operational data, and to make it available to every team within the organization that needs it. But in order to tame this vast and growing ocean of data, companies need the right tools to help them make sense of things, in hopes of extracting insights. Gaining these insights are crucial to the success of an organization, to see if their team is meeting its goals, to help management determine future strategy, and to help the company get a leg up on the competition -- which in turn leads to ever more data as they expand and grow. Companies always have more and more data to add to the pile. Even if the number of data points being collected stays the same, data grows simply due to time marching onward; they will need to collect the same data points next month, and the month after that, and onward and onward. Data is a prized possession. Enterprises can keep all their data to themselves, or data can be bought and sold.
Snowflake is a tool that helps companies manage their data and help to extract insights. They have just released their amended S-1 and are expected to go public this coming week. I have been awaiting this for well over a year now, and with this S-1, we finally get our first direct view into their execution. So let's look deeper into the company and what makes their platform so successful.
We have only had a few glimpses at how well they were growing before now. Okta's annual Business at Work report from January 2020 had Snowflake as the #1 fastest growing SaaS service (as seen by Okta's integration network) over 2019, having an outrageous +273% uptick in usage over the year. (See my prior report on it.) It was clear the company was executing fantastically ... but we can now see it with our own eyes, and soon can finally own a piece.

Overview
The vast majority of investment research I've seen thus far the company has labelled Snowflake as a "Data Warehouse-as-a-Service" (DWaaS). That may be what they called themselves originally (and is still around in older marketing), but they go way beyond that. Today, Snowflake is a data cloud.
In a nutshell, Snowflake wants to be the engine that drives all analytics – both business intelligence (BI) and data science (ML/AI) -- over the entire enterprise. They are a database-as-a-service (DBaaS) provider that is available across the 3 major cloud infrastructure-as-a-service (IaaS) environments of Amazon AWS, Microsoft Azure, & Google Cloud Platform (GCP). They provide a turnkey cloud-native, scalable database platform with a heavy focus on enterprise concerns of security, governance & compliance, while having a rich ecosystem of integrations to ingest, BI and analytical tools, & SaaS partners.
It is important to understand up front that Snowflake's architecture separates the storage of the data from the compute intensive actions performed over it. The platform leverages the native storage & compute methods within each cloud provider. While storage and compute are separated, they are then co-located together, so that the native compute is handling all the needed ingest, querying and analytics performed over the native data stores it resides directly next to in underlying cloud infrastructure. Those separated storage and compute tiers within their platform's clusters are set up to be separately scalable per customer, which allows each customer to tune it to their needs. This allows each customer to factor in the amount of data they wish to hold, versus the performance and responsiveness and concurrency they desire, versus the price they want to pay. Customers can scale up costs for improved performance and more concurrent actions, or can scale down costs for less concurrency, queued up processes, and longer wait times. This scalable internal architecture makes Snowflake a cloud-within-a-cloud.
They operate platform clusters that are created across regions & availability zones within the 3 cloud providers, which are then shared across customers. This cloud-native design means that their platform can be distributed across multiple clusters in each region, making it both resilient & scalable. The ability to scale their own platform is critical, as they can dynamically size their platform as needed, scaling up or down as necessary. When a new customer joins with a petabytes of storage needs, or when an existing customer's compute needs sharply rise, the platform can instantly adjust its overall capacity to handle it. This distributed architecture, coupled with the separately scalable compute engines per customer, gives it a massive cost & performance improvement in compute-heavy tasks like querying & analytics. Insights can be discovered in seconds and minutes, not hours and days. And there is no limit to the amount of data that can be processed - the platform can scale to handle 100s of petabytes if the customer demands it.
But having an architecture built around having shared platform clusters comes with risk -- data can never intermingle between customers. I find that Snowflake has an extremely high focus on security & goverance of data. All access to the data is tightly controlled by the platform's service layer. Data is encrypted, both in transit and at rest (the underlying compressed files stored within S3, Azure Blob, or Google Cloud Storage). User authentication and access rights are at the core of their system, with wide flexibility of how to interface with the platform, including typical modern security features (single sign on, and multi-factor authentication), but also the ability to have your enterprise network direct-connect into their platform (circumventing the public internet). The platform has received all kinds of data security certifications, with the stricter regulatory ones being in higher pricing tiers: HIPAA, PCI-DSS, FedRAMP Moderate, ISO 27001, SOC 2 Type II, SOC 1 Type II.
Data access is easily controlled by data owners via role-based access control (RBAC), and can be extremely granular. And because their platform acts as a centralized data store over its customers, a huge benefit it unlocks is the ease at which it can share or exchange data between customers and outside users. The service layer is controlling all access, so it can easily share whatever (highly-controlled) portions of your data you wish to share with others.
Combined with Snowflake's distributed & scalable architecture, these factors ultimately give its platform a lot of flexibility and optionality, from which, multiple use cases (each with a different set of audiences) have emerged: it can be a data warehouse, a data lake, an enterprise-wide search or analytical engine, a cloud-native database to develop data-driven applications on top of, a collective pool of shared data across a partnership, and a marketplace for monetized data access.
The platform provides tooling and plug-ins around the lifecycle of data, at the points of ingest, querying and analytics. The platform has an ecosystem of integration partners, that it can leverage for those actions, and help its customers interconnect the tooling they already utilize within their enterprise. This allows for a wide variety of tools for streaming or batch importing of data, and BI and data science analytical tooling over the data.
"We believe in a data connected world where organizations have seamless access to explore, share, and unlock the value of data. To realize this vision, we are pioneering the Data Cloud, an ecosystem where Snowflake customers, partners, and data providers can break down data silos and derive value from rapidly growing data sets in secure, governed, and compliant ways." - Snowflake S-1
Raw Numbers
The S-1 shows absolutely stellar numbers in the most recent quarter. [I'm just going to glance at them, see the links at the bottom for better number crunching by others.]
Revenue $133M +121%
TTM Revenue $403B +137%
RPO $688M +211%
Gross Margins 62% +1300bps
$NER 158%
Custs 3117 +101%
- Custs >1M 56 +155%
- 500M avg daily queries +100%
- 7 of Fortune 10 provides 4% of rev; 146 of Fortune 500 provides 26% or rev
I see a massive influx of new customers (+101% YOY), existing customers spending more and more ($NER 158%), and the largest customers getting larger (+155%). All that lead to top-tier revenue growth (+121%) and an RPO growing even more (+211%). A look at the growth over last two years:
| Period | Revenue | QoQ | YoY |
|---|---|---|---|
| Q221 | 133 | +22% | +122% |
| Q121 | 109 | +24% | +148% |
| Q420 | 88 | +21% | +138% |
| Q320 | 73 | +22% | +152% |
| Q220 | 60 | +36% | |
| Q120 | 44 | +19% | |
| Q419 | 37 | +28% | |
| Q319 | 29 |
TAM is estimated to be $137B, and growing -- $81B for data cloud, plus $56B for analytic platform. Industry trends see this rising significantly over the next few years, as data continues to grow and as this new age of analytics gets embraced more and more.
Margins are low for a SaaS company, which is heavily influenced by the fact they must pay the cloud providers for all the storage & compute resources used. But the fact it is rising significantly (+13 percentage points YoY) is a great sign. Snowflake is in an interesting conundrum of the modern age of the cloud -- their platform is built upon the IaaS providers who happen to be their biggest competition.
"In addition, our platform currently operates on public cloud infrastructure provided by Amazon Web Services (AWS), Microsoft Azure (Azure), and Google Cloud Platform (GCP), and our costs and gross margins are significantly influenced by the prices we are able to negotiate with these public cloud providers, which in certain cases are also our competitors." - S-1
History
Founded in 2012 by ex-Oracle data architects, it operated in stealth for a few years until CEO Bob Muglia (formerly of Microsoft) joined in June 2014. A few months later, the Snowflake platform was finally opened to the public, with its original focus of being a "Data Warehouse-as-a-Service". Snowflake first ran only on AWS, then ultimately added Azure in mid-2018 and Google Cloud Platform (GCP) in mid-2019.
Along the way, the BOD decided it wanted a "power CEO" with expertise in taking the company public, so changed up the CEO role quickly in mid-2017. Out was Bob Muglia and in was Frank Slootman, enticed out of retirement after his 6 years as CEO of ServiceNow ($NOW). Over his 6 year tenure (2011-2017), he not only took them public, but also grew their run rate from $75M to $1.5B. Before that, he was CEO of Data Domain, a data storage company ultimately acquired by EMC (now part of Dell).
The BOD is full of industry-aware high-level folks from ServiceNow, VMWare/Dell/EMC, BMC Software, Adobe, & Symantec. It also has some direct competitors on the board, between the CFO of Cisco and the CEO of Arista. [The BOD social gatherings must be fun.]
What They Set Out to Solve (aka More About Data Warehouses Than You Wanted to Know)
To understand all the benefits and the use cases, I feel it necessary to dive in a bit deeper about why Snowflake was built. So let's talk about why analytical databases exist and their major types of workloads. It's time to learn some terms! (Oh boy!)
- Transactional Database = What you typically think of as a database (from Oracle, SQL Server, Postgres, or MySQL) is one honed for online transactional processing (OLTP) workloads. This kind of database is highly tuned for relationships between data sets and for handling complex transactions between them. [An example of a database transaction is a bank transaction, such as transferring cash from your checking account to your mortgage as payment. The system must assure it either all gets processed (across multiple records and tables), or is all rolled back if something goes wrong.] This kind of database is built around create/read/update/delete (CRUD) actions on individual records, and for interlinking related records between data tables while querying (joins). The primary users are the developers of APIs or apps that are accessing it, or business users for monitoring & reporting on operations.
- Structured Query Language (SQL) = Special purpose programming language used to craft data queries and database manipulation commands. It is the defacto standard for querying relational databases. [It is pronounced "sequel", not "S-Q-L", and don't let anyone tell you different. And since I'm being controversial, it's "day-tuh", not "daa-tuh", which more akin to a sound a sheep would make.]
- Data Warehouse = Data Warehouse databases, on the other hand, are honed for online analytical processing (OLAP) workloads, in order to have vision into the entire enterprise's operations. This is a structured data store that is filled with pre-processed (refined) data, to be used for analyzing the business. Primary users are business analysts (with operational knowledge) that are tracking performance of business metrics and doing related actions around it, like forecasting, planning, budgeting, & financial reporting. Unlike transactional databases, this kind of database is not geared for working with individual records, but is instead optimized around isolating and grouping like data (e.g. analyzing sales totals per region, or per sales agent, or per product category, or per product).
- Data Mart = Smaller data warehouses specially made-to-purpose for a specific team's use. If a Data Warehouse is the grocery store for your data, Data Marts are the corner markets. Companies might create separate mini-warehouses for sales, marketing, finance, HR, operations, or development teams -- whoever needed it. This could help offload the compute needed for all the queries being made, so that each team's needs were isolated from the other teams, and so could be spread across multiple database systems.
- Data Refinement = To make best use of a data warehouse, the raw data from transactional databases and other sources is processed in advance around pre-defined business objectives, and is then imported into the data warehouse and analyzed from there, typically with BI tooling (like Tableau, PowerBI, or Qlik) for visualizations, dashboards, or interactive (ad-hoc) querying. The refining process would typically involve taking the raw data from multiple sources, merging it into a single dataset (blending), then cleaning, enriching, filtering, sorting, removing personal info (scrubbing), and/or de-duplicating it further. This data processing is typically done in a separate staging area (likely a separate database), then imported into the Data Warehouse once refinement is complete.
- Business Intelligence (BI) = The process of analyzing operational data in order to extract actionable information, and help business users (typically executives and managers) measure operational performance, to make informed decisions and forecasts.
Data warehouses are specifically honed for BI analysis. The users are primarily data analysts and business users with specific business objectives that they wish to gain vision into & extract insights from.
There are 2 primary methodologies on how to architect your data warehouse and workflows. In one (the Inmon method), you could throw all your refined data into a centralized data warehouse, and optionally create data marts for specific teams to use. In the other (the Kimball method), you would create the more tightly-honed data marts first, then pool them all into a centralized store for looking at the entire business. Either way, you ended up with a valuable, centralized pool of refined data, where management could get complete visibility into the business and use it as the source for tracking operational metrics.
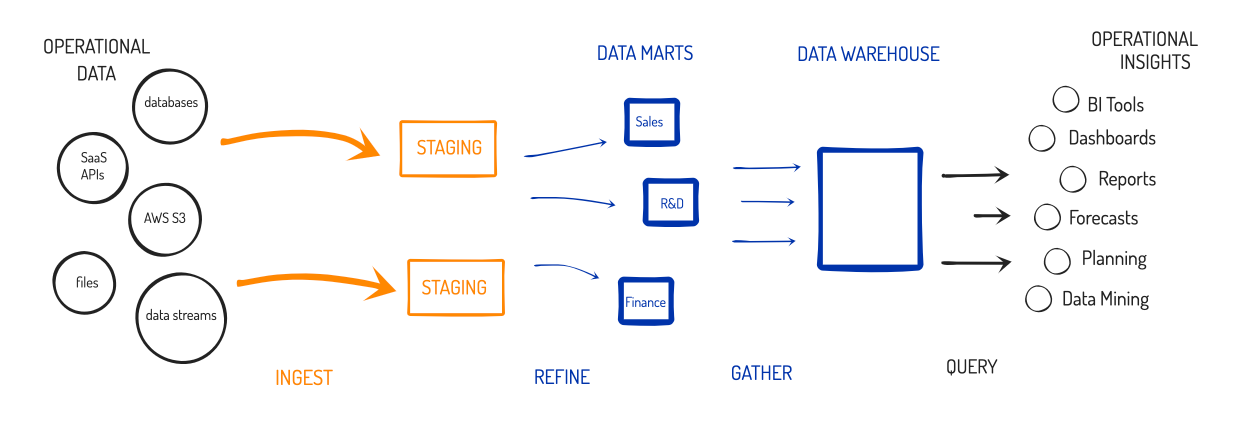
While upper management loved the visibility it gained, Data Warehouses had some major negatives for all other parties involved. It turns out that analyzing vast quantities of data takes a huge amount of resources, so users found themselves very constrained. Before the cloud era, data warehouses were built on-premise and had to run on a single system that had to be incredibly powerful (lots of cores, memory and storage). Because the total resources of the hardware were fixed, users had to play lots of tricks to do more [analysis] with less [compute & memory].
Why is it so hard to work with data warehouses? Let's dive a little deeper, just to understand the difficulties that users faced.
- Dimension = A specific factor within the data that a business analyst wants to analyze, and use as a grouping to aggregate (roll up) data. Dimensions in data analysis can be thought of as dimensions on a graph (x-axis, y-axis, z-axis, ...). For example, in analyzing sales data, managers may wish to count & sum up $ of sales by region, by state, by sales person, or by product – those are each a separate dimension. Start adding in other data sources, like supply chain, logistics and inventory data, it can greatly magnify the number of dimensions. As the data queries become more and more multi-dimensional (e.g. aggregating sales data by product, then by region, then by sales person), it makes the data harder and harder to analyze, which in turn requires more and more resources (compute and memory) to accomplish.
- Ingest Process = Getting the data out of the original silos and loading it into the data warehouse.
- Extract, Transform, & Load (ETL) = The typical ingest process for exporting data out of data systems, manipulating it to refine it for analytical querying, then importing into the database. This is a difficult process for data warehouses, as it requires refining the dataset down around specific objectives. The dataset ultimately ends up in a final format that contains every dimension the business analysts want to then query, report & analyze around.
- OLAP Cubes = The process of further refining a data warehouse's dataset down, to pre-aggregate the data across every combination of multi-dimensional analysis desired. By creating an OLAP Cube, the analyst is doing the compute up-front, helping to reduce the amount of compute needed during final analysis. If you are familiar with Excel, it is basically creating a series of giant pivot tables – an array of them, each filled with arrays upon arrays of data aggregations, across each combination of the multiple dimensions within the data.
During the initial ETL stage, analysts had to refine the raw data into a specialized format that restructures the data, in order to make it more ideal for extracting insights in the dimensions (business objectives) they cared about. The severe downsides to this was that it forced analysts to have to make a lot of upfront assumptions, which in turn made the entire process extremely inflexible. If those assumptions were wrong ("oh wait, the VP of Sales wants to see this data summed up by region, not by state"), they would have to start all over. Once the dataset was in the data warehouse, they would have to further refine the data to create highly-honed OLAP Cubes, which allowed them to do deeper multi-dimensional analysis. Again, these tricks were all employed due to the constraints of having the database be on hardware with capped resources. I cannot stress enough what a royal pain in the ass this whole process was!
This workflow had 2 primary roles:
- Data Engineer = The role responsible for cataloging and extracting data out of original sources and into the data warehouse, including the pre-processing (refinement) of data, and then helping move data through the Warehouse and Marts.
- Data Analyst = The role responsible for extracting insights from the data. They focus solely on the specific business objections provided by business users, like upper management and managers. They work with the Data Engineers to refine the data for initial ingest, and then further refinement again into OLAP Cubes – as it all requires operational knowledge of the data, such as what dimensions & values are needed.
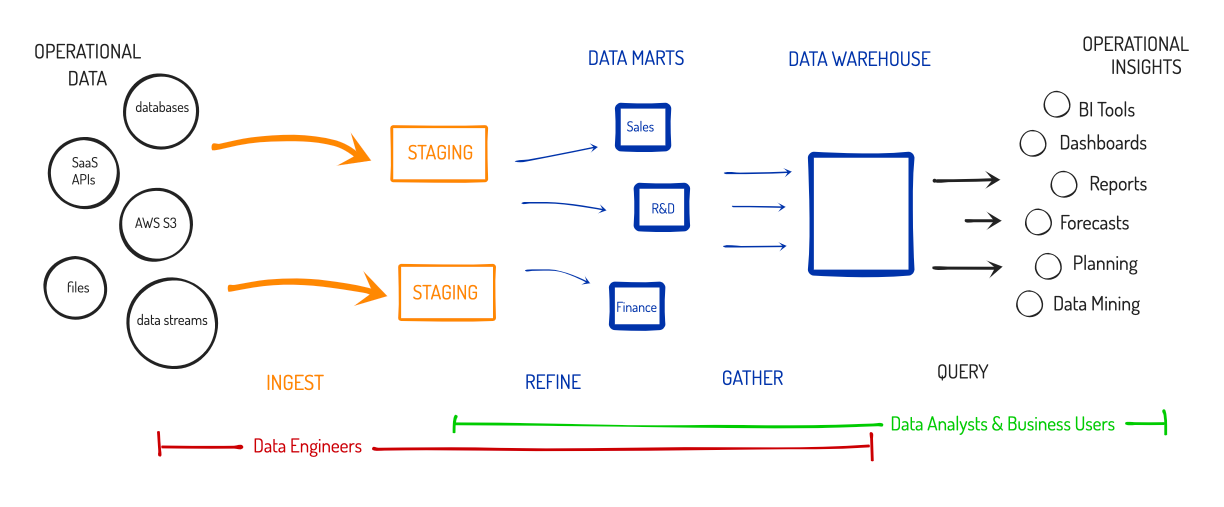
Ultimately, data warehouse systems became clustered, which started to allow data analysts to be able to do these actions more on-the-fly instead of making a lot of up-front assumptions. But clustered systems magnified the costs and the headaches – you still had to manage multiple systems to run the cluster upon, and since the software architecture was difficult to work with, the maintenance was a nightmare. These systems became a huge headache for IT to administer, and for the data engineers & analysts as management demanded more and more insights (adding new datasets, adding new dimensions).
Send in the Cloud
As it is wont to do... the cloud ... changed ... everything. Running it on the cloud, you can stand up infrastructure and scale it as needed. Gone are the days of having resources so constrained! The next wave brought better tooling built on top of that cloud infrastructure, and cloud-native managed data warehouse SaaS services started to spring up. You no longer had to deal with any of the complexities of maintaining all this infrastructure!
But the near limitless scale of the cloud drastically changed what could be accomplished. A lot of the processes around Data Warehouses, like OLAP Cubes, were built around those original on-premise needs, when users were highly constrained by the amount of compute & storage resources available. The scale & elasticity of the cloud allowed for the architecture of analytical databases to evolve, and a new paradigm emerged.
- Data Lake = Using a centralized database as a vast pool for holding all of an enterprise's raw data. It can contain structured (relational data) as well as semi-structured (NoSQL) data, and allows for a common query interface over it. This allows users to further refine the data to import into a Data Warehouse from there for BI. But better yet, the database could be running analytics directly over the raw data. The benefits of a Data Lake are that it enables data scientists to extract new insights from raw data collected from across the entire enterprise (analytics that are not just around specific pre-determined business objectives), and enables centralized data sharing across the entire enterprise (data could be viewed across all regions, segments, departments, or teams).
- Extract, Load & Transform (ELT) = Changing the ETL process to eliminate needing a staging area. The load ("L") is done before the transform ("T"), meaning all of the raw data is now directly loaded into the Data Lake, which can then serve as the staging area to further refine the data from there, using SQL-based tooling.
- Data Scientist = Analytical & statistical expert that tries to find trends and insights from vast quantities of structured and semi-structured raw data, in order to make predictions based on past patterns. This is different than data analysts, who are more focused on extracting metrics around specific business objectives.
The primary benefit of a Data Lake is obvious - it becomes a centralized store for all your data. This eliminates silos, but also serves as the launching pad for anything else you want to do with that data, especially data analytics. And it is not a static thing -- the goal of the Data Lake is to automatically pull in data continually going forward. The near limitless scale of the cloud enables the near limitless scale of the Data Lake – it can just grow and grow as more data flows in. Older data can be kept, or can be archived as it no longer becomes useful.
A Data Lake does not replace a Data Warehouse (as a Data Scientist does not replace a Data Analyst). The need for BI – viewing data through the lens of pre-determined business objectives – has not gone away! A Data Lake has its own purposes, but also it works in harmony with a Data Warehouse. Having a Data Lake and a Data Warehouse greatly simplifies the data engineer's tasks from above. During data extraction (the E of ETL), instead of gathering it from separate data silos, they can be pulling all raw data from the centralized data lake. In data transformation (the T of ETL), it altogether eliminates the need for a staging area, by greatly simplifying how they can refine data. They can instead use standard SQL queries to refine data and write it into new datasets, all directly within the Data Lake. In fact, now the data analysts can be doing this work directly, and the data engineers can solely focus on the data movement (extract and load).
Age of Analytics
Being a huge vast pool of operational data, Data Lakes have become the platform of choice for data science, especially machine learning (ML). Open-source distributed analytical platforms like Apache Hadoop were being utilized, which had better practices around separation of concerns (splitting up the storage engine from the compute engine, but distributing them side-by-side). Hadoop enabled companies to have a data lake (distributed storage) that enabled querying and analyzing directly over that data (distributed compute). Most flocked to a Hadoop module called Hive, which allowed using a common SQL query interface over any data stored within Hadoop. But Hadoop once again required running extremely complicated software clusters - and again, became a royal headache for IT and data scientists to administer & use. Using Hadoop & Hive were certainly faster than earlier data science tooling (which required days and days of data refinement ahead of time), but still felt slow – insights could take hours or days to extract out of the vast (and growing) quantities of data being stored in it.
It could only be made more performant and efficient from there. Analytical tools in Hadoop evolved further, and a module called Apache Spark eventually emerged out of that ecosystem as an independent analytical platform. It is an open-source distributed analytical software that made the compute side of Hadoop much, much faster. Data is first loaded into memory across the distributed nodes in the cluster, so then all analytical tasks performed on it from there could be done entirely in-memory, instead of working over a storage layer. This can make certain operations ~100x faster over Hadoop/Hive, and suddenly answers could come in seconds or minutes instead of hours or days. The company Databricks was created around the open-source Spark engine, in order to enhance and support it.
Apache Spark has become one of the primary data science & machine learning tools in use today. But beyond that, data scientists still use raw statistical tools like MATLAB, or will write scripts using programming languages like Python, R, Java, or C++, utilizing a wide host of analytical libraries & frameworks available (TensorFlow, Pandas, Numpy, Pytorch, Scikit-learn).
And if they aren't coding it themselves or using Spark, they are likely using the many analytical platforms that have emerged, like Alteryx, Qubulo, or RapidMiner, or one of the many analtyical services from the cloud providers, like AWS Sagemaker, Azure ML, or Google Cloud AI.
Ok, enough about data and analytical engines. What makes Snowflake so special?
Platform Architecture
Do not think of Snowflake as "just a cloud data warehouse". It is best of both worlds; it is highly optimized to be both a Data Lake and a Data Warehouse. It's a Data Lakehouse - a new paradigm that combines the best features of the two workloads with different user bases and use cases.
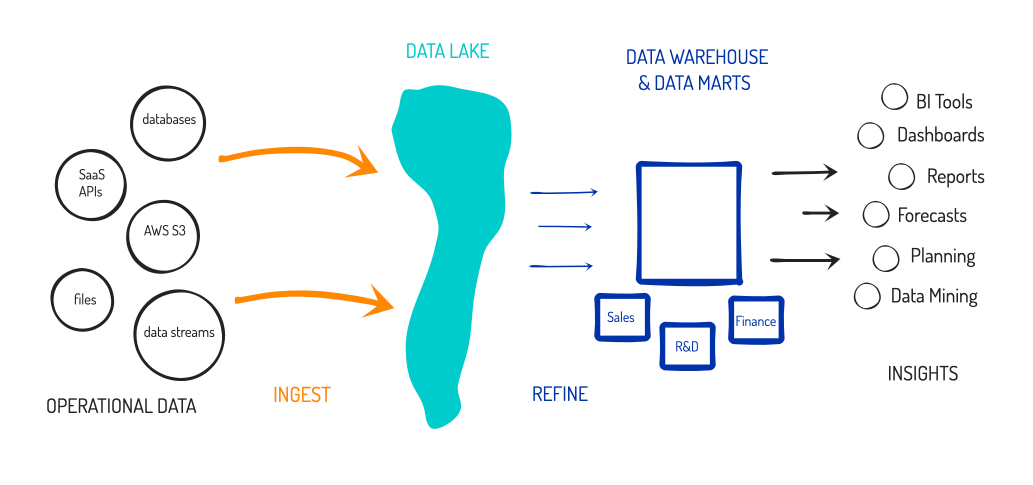
A data lake not only enables users to directly query over any part of the enterprise-wide pool of raw data, but also allows them to further refine any of that raw data into new forms, honed around whatever format they need for their analytical tooling. This means raw data can be manipulated directly into refined tables that live inside the same database. (No more staging area, or separate analytical databases.) Data analysts no longer have to make a lot of assumptions early in the process, and they are no longer restrained at query time to just the dimensions they had set up in advance. They can figure out what they need from the pool of raw data, and create new refined datasets from that data, as needed - all sitting side by side in the same database.
SQL Interface
Snowflake was named after the "snowflake schema" (combined with the founders' love of skiing), which was a data warehouse methodology that combined the traditional mart-warehouse (Kimball) layout with relational SQL databases for dimensional lookups. This perfectly sums up the platform's dual purpose – it is an analytical database that has SQL querying capabilities over the entire Data Lake. SQL is the defacto database querying language, which serves as the primary method that data engineers, data analysts and data scientists can all use to administer & query databases.
What this means is that you can throw ANY data at it. It allows for SQL querying over both structured (relational) and semi-structured (NoSQL) data. Under the hood, it is all columnar data stores within the cloud provider's native object storage. This means that every field in the data set is split up and stored separately as individual (encrypted & compressed) files in the native cloud storage. The fact it all breaks down into this columnar format allows for an interminging of data formats over a common query mechanism. The platform accepts a wide variety of data formats beyond traditional (relational) data – it can also directly utilize JSON, XML, Avro, Parquet and ORC data formats (the 2 primary data formats, plus other file formats popular within the Hadoop ecosystem).
Analytical Data Cloud
The limitless scale of the cloud has enabled a new breed of cloud-native platform that combines all the features above - an analytical database (acting as both a data lake and a data warehouse) that has also embedded the ability to run analytical tooling within the platform. Snowflake is not only a data cloud-within-a-cloud, but it also acts akin to a Hadoop-as-a-service, where you can be running analytical tools directly within their distributed compute. To be clear, Hadoop is not directly part of its stack, but it is in reference to how the architectures are very similarly designed around distributed compute nodes running over distributed storage nodes, and how they allow for analytical tasks to be run within those compute nodes. For instance, you can run distributed Spark jobs directly inside Snowflake's distributed compute, exactly as you could do in Hadoop.
Snowflake gives you all of these things in one single package. Having all the data in one place, then being able to run analytics over it all, brings an immense amount of value over the very constrained days of ole. However, all of the cloud providers are moving into this same direction, and now have data lake AND data warehouse AND analytical capabilities, AND have the near limitless scale of the cloud. But this is just the start of Snowflake's architecture. The platform has an incredible number of benefits it can leverage from here, that I believe are huge advantages over the other "all-in-one" data platforms that the individual cloud providers (who I consider are Snowflake's primary competitors) are creating.
Cloud-Neutral Vendor (Multi-cloud)
The primary benefit of Snowflake over cloud providers' native solutions it that it can be run in EVERY cloud provider. This ultimately enables their customers to adopt a multi-cloud strategy, so to not be locked-in to a single cloud provider. This in turn gives large enterprises a huge amount of leverage over the IaaS cloud providers that they never had before! Customers are now able to utilize the best cloud provider for their specific needs, likely decided around cost and convenience (nearness to other cloud infrastructure services they use). [I bring this up first because I want to highlight how powerful this benefit is - it is the primary advantage they have over the native solutions that cloud providers are creating.]
Leveraging the Native Features
But the benefit goes way beyond giving the customer a huge amount of leverage -- the Snowflake platform leverages the native infrastructure & tooling within each cloud provider in order to be as performant as possible. They have tightly designed their platform's architecture onto each cloud provider's native services: they use the native storage capabilities within each provider, plus the compute resources that live as near to it as possible.
- In AWS, is using EC2 compute over S3 storage, acting somewhat akin to (aka competes against) AWS Athena or the MongoDB Atlas Data Lake service.
- In Azure, it utilizes Azure Compute over Azure Blob Storage. They also recently added support for the new Azure Data Lake Storage format (ADLS Gen2).
- On Google Cloud, it uses Google Compute Engine (GCE) over Google Cloud Storage (GCS).
Across all 3 cloud providers, they maintain their own set of distributed platform clusters, under which is shared storage & cloud services tiers, while every customer gets their own separate compute nodes. This makes the multiple platform clusters (running under each cloud provider, across many regions and availability zones) as efficient as possible -- the compute engine is located in the same data center the storage layer it is working on is in.
Flexible Simplicity
Snowflake is a multi-cloud turnkey SaaS provider - there is no infrastructure to maintain, and no system integrations are needed to being using it. They tout this heavily, and have intentially lessened the amount of configuration and tweaking that can be done within the platform. They designed it to be incredibly easy to adopt and utilize, and from a users' point of view, looks and feels just like a relational database.
But simplicity does not prevent it from being feature rich, and they have been adding many other native features around the core Data Lakehouse. And beyond the platform's own capabilities, there are also many ways to externally exhance the platform, as they have a ecosystem of integration partners that can provide tooling around ingest, BI, and analytics. This allows companies to utilize whatever tooling they prefer at these points, to either extend the data platform with capabilities provided by external partners, or do it all themselves (scripting it).
Optionality
So let's sum up the architectural benefits thus far.... they are a cloud-native data platform that acts as a cloud-within-a-cloud, utilizing the native features within each cloud provider for storage and compute, and so are capable of near limitless scale. This makes them vendor-neutral, which allows customers to adopt a multi-cloud strategy and have a lot more flexibility with the infrastructure and tooling they want to use. They have built multiple platform clusters across regions & zones within the 3 cloud providers, which act as a distributed platform to make them highly resilient & performant. They utilize usage-based pricing, and separate the customer's storage and compute layers in order to allow customers to scale either as desired. Under the hood they are a columnar store, which allows them to support diverse data types & formats (both relational and semi-structured data). They are easy to use, and take away all the hassles of maintaining your own on-prem or cloud infrastructure for data, plus have an extreme focus on security and governance over that data. And finally, they expose inline analytical capabilities to customers akin to Hadoop-as-a-service, by allowing it to run directly within the platform's distributed compute engine.
Whew! This all sounds pretty amazing thus far. And it's just the start.... as there is also all the platform benefits:
- The wide number of use cases and audiences that Snowflake appeals to.
- Seamless and secure data sharing, which enables many of those use cases.
- Creating a data marketplace, to enable monetization of enterprise data by data brokers.
- Acting as a managed database service for software developers of data- or analytic-focused applications & services.
- Plus their broad ecosystem, with a wide variety of partners and tools for ingest, BI and analytics.
These are all incredibly potent in their own right, but the combination of them makes Snowflake's platform greatly appealing to a huge number of enterprises, for its scale, cost, performance, flexibility, and compatibility with existing tools. And, most importantly to the investment case, these strengths combine to give it a huge amount of optionality.
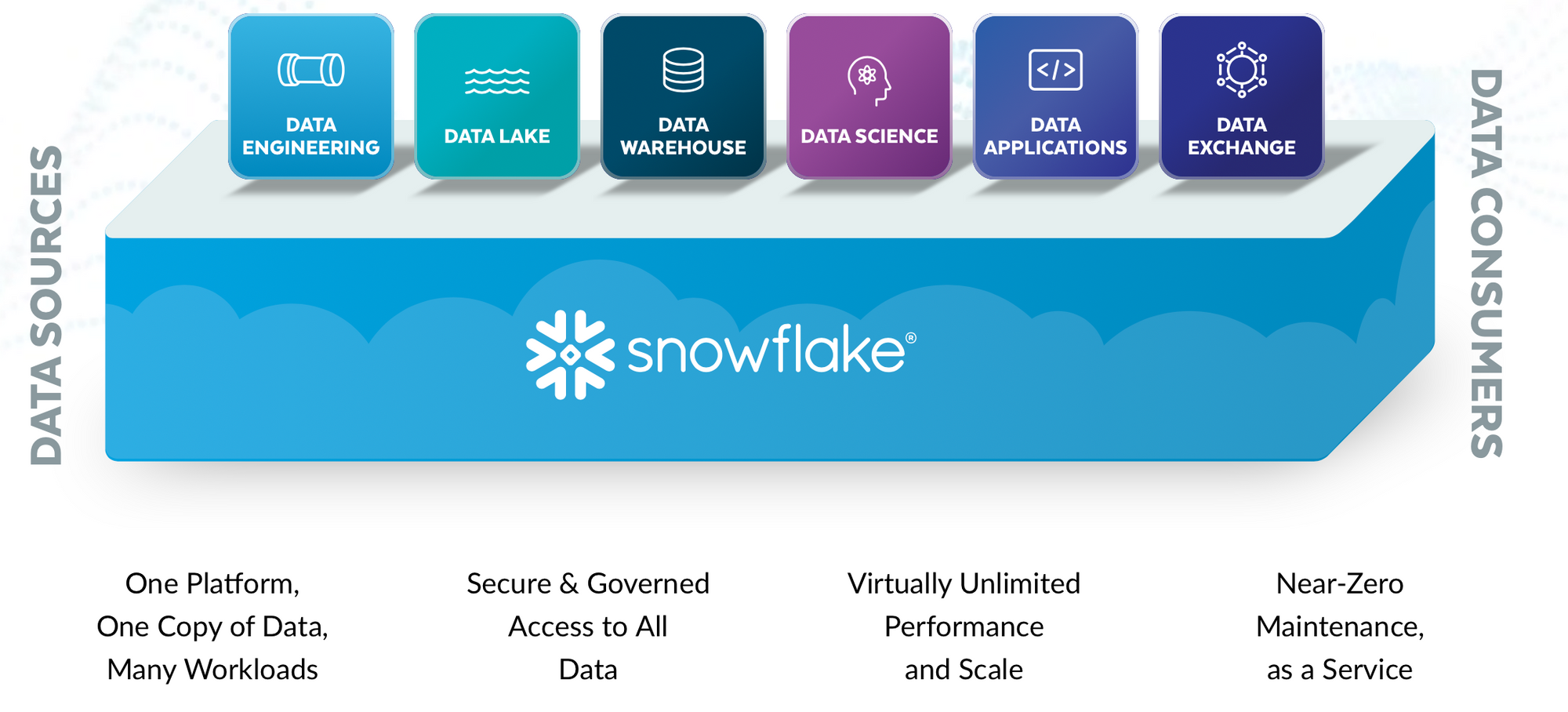
Wide Number of Use Cases
Having a scalable analytical database over a scalable compute layer has allowed the platform to be tuned to support a wide variety of workload use cases.
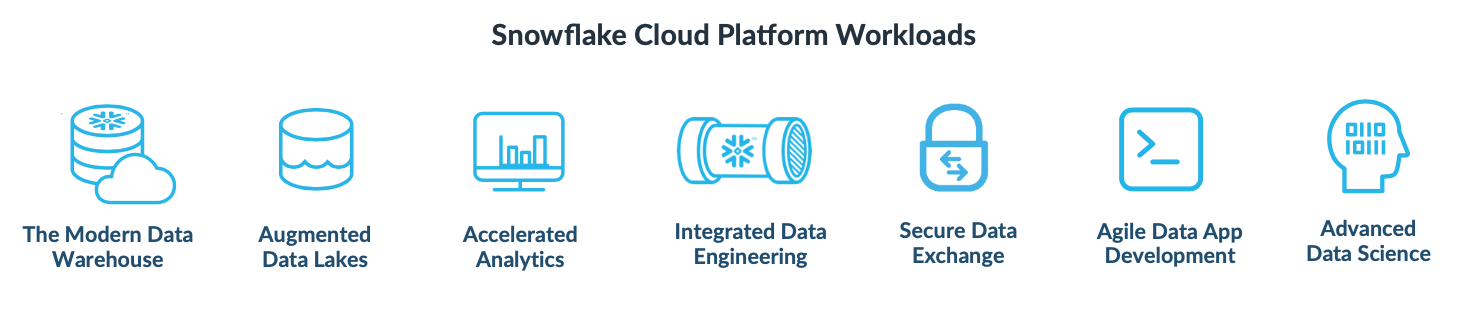
- An enterprise-wide data lake, enabling analytics and organizational sharing.
- An enterprise-wide data warehouse, enabling business intelligence.
- A data science hub, enabling distributed analytics across the entire enterprise.
- A centralized ingest hub for all data flows & pipelines.
- A data exchange hub, allowing data pooling & collaboration between a group of partners.
- A cloud-native managed database service, acting as the core storage for data-driven applications or services.
- A marketplace for interactive (queryable) published or monetized data sets.
... all powered by data contained within that centralized Data Lakehouse, and at the near limitless scale of the cloud. So now the "Data Warehouse-as-a-Service" platform suddenly looks like this:
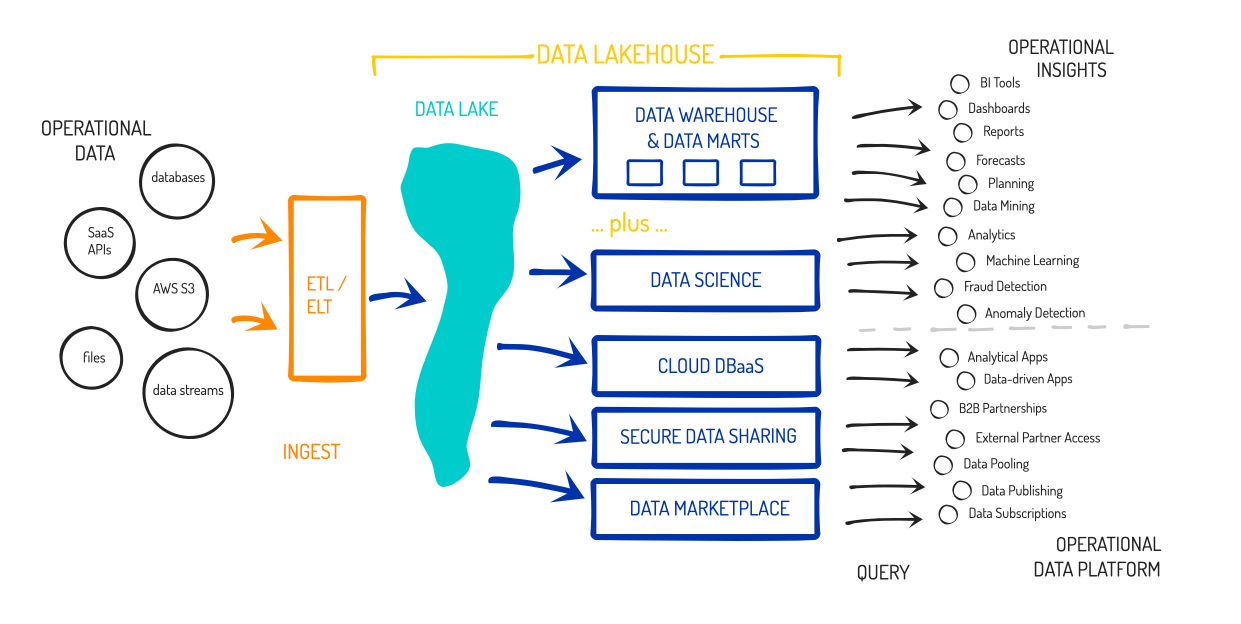
Wide Number of Enterprise Users
That wide number of use cases then leads to a wide number of potential users of the platform within a given enterprise:
- Data Engineers (Ingest), for importing & managing the data, or pulling in datasets from others
- Business/Data Analysts (BI), tracking operational metrics for Mgmt, Sales, Marketing, Finance teams
- Data Scientists (Analytics), using ML to extract further insights
- Citizen data scientists (BI & Analytics), merging the business analysts with the data scientists
- Developers (DBaaS), using it as the data store of their app/service
- Data Brokers (Data Marketplace), as publishers of data
- Operational users, like sales & marketing (Data Marketplace), to manage subscribers to published or monetized datasets
And it enables users beyond own's own enterprise:
- Partnering Businesses (Data Exchange), to cross-collaborate over shared databases for B2B partnerships or joint ventures
- Subscribing Businesses (Data Marketplace), as subscribers & consumers of shared or published datasets
I see the user types overlaying the solutions like so:
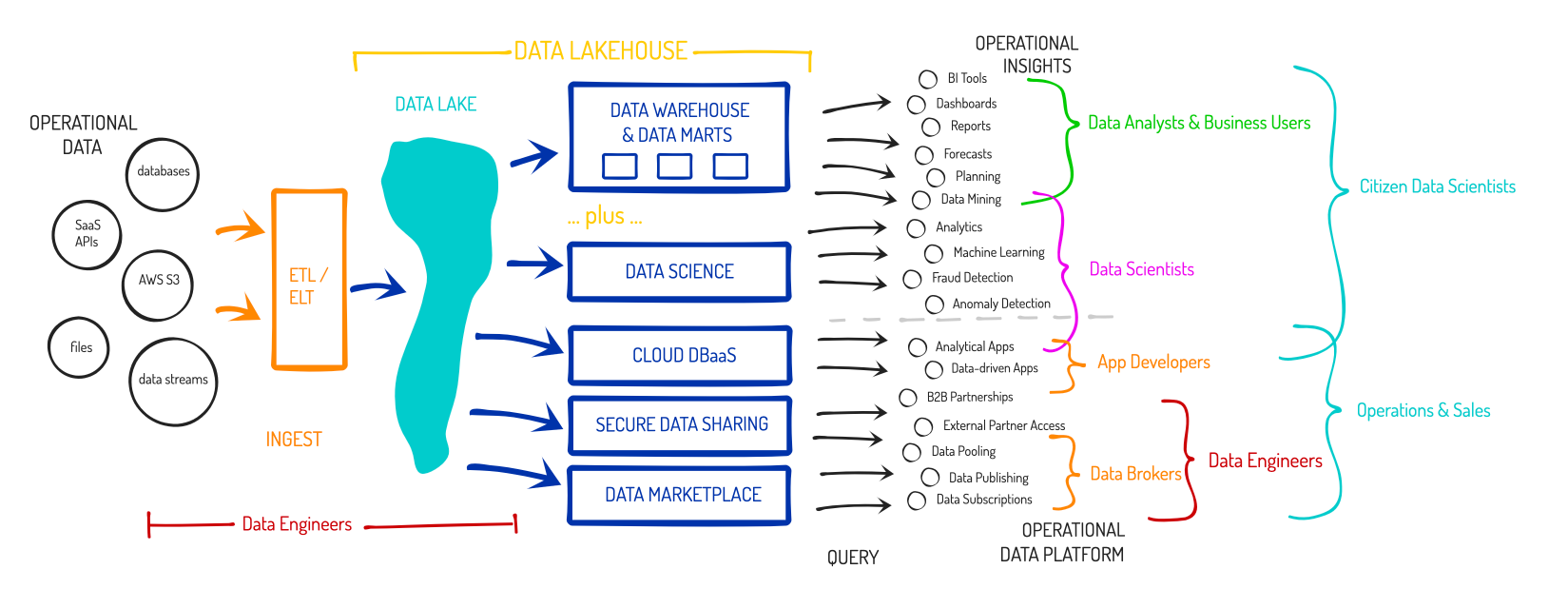
Cloud-within-a-cloud
The Snowflake platform is highly available (HA), as they utilize multiple platform clusters across each cloud provider and then spread them across multiple cloud regions & availability zones for data redundancy (resilience & business continuity), assuring their platform is always available and distributing it across the globe. But this also improves performance (as the workload running on it is distributed), plus gives the platform elasticity (new platform clusters can be spun up or down as demand dictates).
Within any platform cluster, a customer can spin up a "virtual warehouse" (private virtual cluster) to handle their specific compute needs. When you spin up a virtual warehouse, you specify the cloud provider and region you would like to utilize, and select a size (from XS to 4XL) of compute cluster you would like - which internally controls the number of distributed compute nodes within that cluster (the parallelism of the compute). This is what I meant by "cloud-within-a-cloud" -- Snowflake is managing and scaling its own platform's infrastructure on IaaS providers, but is also then managing and scaling customer instances that run within it.
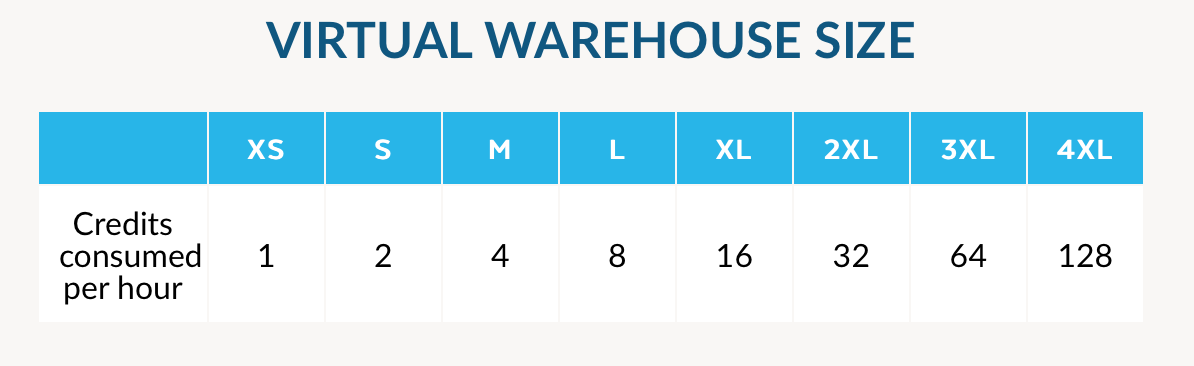
Customers can start at a specific level they desire, based on the amount of ingest and querying they will be doing. But they can adjust the size at any time (scale up or down), to lower or increase the size (the number of compute nodes) in their virtual warehouse. And if it needs to go idle for any reason, the user can pause their virtual warehouse, which in turn pauses the billing. This all combines to allow the customers a HUGE amount of flexibility and scale. If they know they have a lot of new data to ingest, or have a huge query they need to process quickly, they can temporarily increase their cluster. And the flip side – if they know data ingest is slowing down, or query performance is no longer as critical, they can decrease the size of their virtual warehouse. The costs directly scale with the needs.
The majority of customers are creating a single private virtual cluster for themselves within the shared platform infrastructure, and let the platform handle the rest. But higher level customers can go farther, creating "multi-cluster virtual warehouses" that can spin up 2-10 separate virtual clusters that all act as one large contiguous database. This allows larger customers to take more advantage of redundancy features, assure higher availability for their own data services accessing it, and to enable even more flexibility in how their Data Lakehouse operates – such as geo-locational dispersement of their data, to isolate certain workloads from others, or to have frequently used "hot" data in a separate virtual cluster from the infrequently used "cold" archival data (with differently sized compute layers over each).
The best part about multi-cluster virtual warehouses is that it can allow for auto-scaling, where customers can set parameters about the minimum and maximum number of clusters to use in their multi-cluster warehouse, and the platform can automatically adjust it based on the current demand. Customers ultimately improve concurrency by up-scaling their cluster count, allowing for usage to be more distributed. When a customer wants more performance of a query or ingest action, they would instead upsize the size (the number of compute nodes) of a particular virtual warehouse. So while there aren't many knobs to tweak in Snowflake, the enterprise customers (especially the largest ones) are given a huge amount of flexibility into how well their cluster performs, versus how much it costs them.
At the highest pricing tier, customers that are especially sensitive to data security can run Snowflake on isolated multi-cluster virtual warehouses that run on dedicated platform clusters, so that their usage is not on any shared portions of the platform (storage and service layers). This isolated tier is not something available in cloud providers' solutions, and I imagine it greatly appeals to financial and healthcare enterprises with extremely sensitive data.
Single Copy of Data
One huge benefit of a Data Lakehouse is that all the raw data can be utilized further, directly within the database. An analyst can be saving queries into new refined datasets for BI tools to take advantage of. A data broker can be directly isolating datasets to share or publish or monetize. The benefit of Snowflake is that the data all exists in one single centralized storage location, which can enable any of those other access modes across the platform. They tout it in marketing as "One Copy of Data, Many Workloads".
As you create refined datasets for BI purposes (what the traditional Data Warehouse was for), the underlying data is not actually copied into separate places. A single source of the data exists in the storage layer – and that is it. Access to that data, and manipulations of that data (including the full history of changes to that data) are all managed and trackable from there. And a step further - by having those inline analytical capabilities (that Hadoop-as-a-service I mentioned), all the analytics can occur directly over that same core of data. All the data science is taking place in the same place as all the BI querying & reporting, and all the data sharing and publishing. All of those features are derived from the same common underlying raw data within the Data Lakehouse. You aren't making copies for every purpose, nor have to transfer data out into other tools for those uses.
Even better than creating separate refined datasets for BI is to use Materialized Views. This is a relational database concept that creates a snapshot of a query result, tracking the results as of the point-in-time that the view was created. This feature can greatly assist the process of refining raw data, by using a refinement query in SQL. Instead of creating separate new data tables for Data Warehouse purposes (for existing BI tools, dashboards, or legacy workflows), it is instead using the materialized view set up for that purpose. The benefit of this is that materialized view can be simply re-run at new points-in-time, which means you are not having to redo the entire refinement process anew each time. In fact, Snowflake can be set to automatically refresh materialized views any time the underlying data changes. This is an massive time saver on data prep for BI analysis. (These materialized view features are only available in the Enterprise pricing tier and higher.)
Data Sharing
Their service layer controls all data access within their shared platform clusters. This in turn enables customers to easily share and publish data. It is not making clones or copies of the data – it is all handled through access rights, and uses pointers to jump to where the segments of data to be shared are located. As just mentioned, it's all out of the single copy of data in the Data Lakehouse. This is a huge differentiator in the Snowflake platform versus the competition - outside access can be done on other platforms, but each customer has to figure it out for themselves, by building in security features and managing access rights within their cloud infrastructure. All of this is out of the box (turnkey) with Snowflake.
"Our platform solves the decades-old problem of data silos and data governance. Leveraging the elasticity and performance of the public cloud, our platform enables customers to unify and query data to support a wide variety of use cases. It also provides frictionless and governed data access so users can securely share data inside and outside of their organizations, generally without copying or moving the underlying data. As a result, customers can blend existing data with new data for broader context, augment data science efforts, or create new monetization streams. Delivered as a service, our platform requires near-zero maintenance, enabling customers to focus on deriving value from their data rather than managing infrastructure." - Snowflake S-1
Snowflake not only wants to be the core for enterprise data analytics & BI, but they also want their DBaaS platform serve as a highly sharable repository for data. There are 3 ways customers can leverage this: they can directly share read-only subsets of their data with outside users (Data Sharing), they can create collaborative shared databases between partners (Data Exchange), and they can expose, publish and monetize datasets (Data Marketplace).
Data Sharing allows taking any portion of your data – any dataset (or a segment of rows within) – and easily be shared with external partners in a read-only way. This is not sharing of files – this is sharing of an interactive, queryable database! Any compute from querying done on the shared data is covered by the owner of the data. And again, it is only one copy of the data in the Data Lakehouse, all access is handled by the services layer that knows what specific portion of that data was shared with what external user. This allows for seamless and secure sharing of any part of your data with external partners.
Extending that further, customers can build partnerships with Data Exchange, in order to share data between multiple contributing partners. This allows new organizations to arise around "pooled data". I see this being of high value for B2B partnerships that exist to expose data to their members. Beyond that, joint ventures could be created (solely existing on Snowflake) in order to combine and monetize efforts around a shared pool of data. If all parties are separate Snowflake customers, they would each share in the storage and compute costs in this use case.
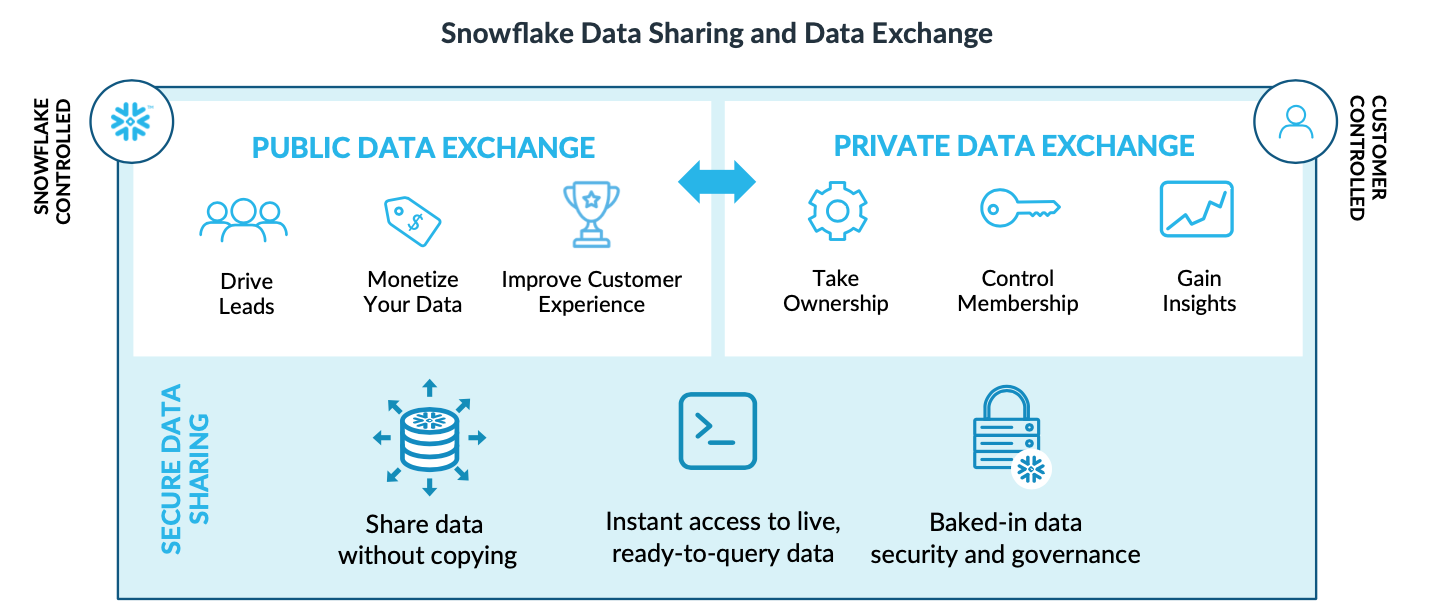
But the most innovative sharing feature is the Data Marketplace. Since Snowflake allows you to easily expose data sets to others, this opens the platform up to an entirely new type of businesses that are created around "published data". Datasets can be public to all (eg like COVID-19 data and dashboards of late), or can be exposed as monetized datasets that users can subscribe to. Again, this is not a set of published files – this exposes the data as an interactive dataset that consumers can make direct queries against! The customer who publishes the dataset covers all compute costs on queries made against it.
"The Snowflake Data Marketplace is a disruptive new technology that will redefine how companies acquire, leverage and monetize data to power their businesses." - Mark Gibbas, CEO of Weather Source
This enables 2 new use cases for customers. Existing companies can start monetizing their data through the platform, from data already in the Data Lakehouse -- it is just a matter of access rights to that data. Companies like Trade Desk ($TTD) and Zillow ($Z) are allowing subscribers access to anonymized data sets from their respective platforms. And Lime, a bike sharing provider, is exposing ridership & route data to cities in order to help promote Smart Mobility and bike safety initiatives.
But beyond sharing aggregated or anonymized enterprise data, a whole new type of customer is empowered by this platform. New companies can be built that solely exist on Snowflake Data Marketplace, that focus solely on being a provider of published data sets to be used for data enrichment. This enables the rise of the Data Broker. Companies like FactSet and Weather Source can build their entire business around the Snowflake Data Marketplace. Again, this is not exposing static files – customers that subscribe to their datasets can make interactive queries against the dataset. Best of all is when you are already a Snowflake customer – using any public or subscribed-to dataset is simply a matter of directly querying it via the SQL interfaces you already use. Have to enrich your customer data with demographics data? Have to overlay weather data over logistics data? It's as easy as a "JOIN" command in your SQL query – no export and import needed.
Distributed Compute
It is easier to extract value from a centralized data lake instead of siloed datasets, so Snowflake clearly simplifies analytics. Data prep can be 80% of work that data scientists perform! As mentioned, a customer's compute layer is ultimately scalable by that customer, with part of it used by the ingest engine, part of it by the query engine – but the most exciting part is the analytical engine.
Certainly, being a Data Lakehouse with a SQL engine, they are easily hooked up into most traditional BI tools for visualizations, dashboarding and ad-hoc querying, such as Tableau, Qlik, Power BI, Sigma, ThoughtSpot, Looker (acquired by Google) and AWS QuickSight. Outside analytical platforms can leverage the SQL querying capabilities too, like Qubole, Alteryx, Zepl, or Dataiku. But those are all using the SQL query engine. Going beyond that, Snowflake allows for embedding data science tooling directly into the distributed compute layer. [Why I say Snowflake is akin to Hadoop-as-a-service.] What is unique is that this is all inline for Snowflake. For other platforms, you need to engage outside tooling for analytics (typically by hooking it up to the native Spark and ML engines in the cloud platforms, like AWS SageMaker or Azure ML).
The virtual warehouse (each customer's private cluster of compute nodes) can be directly running analytical processes, so ML models can be running in a highly-efficient distributed manner, performed right alongside the data storage. You can embed data science scripts into the compute engine, providing a very cost-effective way to perform bulk analytical operations over the data, as opposed to exporting the data into a separate package for analysis. With the scale of being a cloud-native distributed database, directly embedding analytical capabilities allows for a huge increase in performance, compared to having to pull your data out of Snowflake and in to external analytical packages. Snowflake enables a nimbleness to data science. All the data is already in one place - why have data scientists continue to waste a huge amount of time extracting and prepping data? All that can be done in real-time now, directly in the data queries over the raw or refined data tables.
Data scientists can embed Apache Spark jobs directly into the compute engine, as well as custom scripts in languages (like Python, R, C++, or Java) using analytical libraries (like TensorFlow, Pandas, PyTorch, scikit-learn and others). Data scientists can also utilize notebook-based ML tools (like Jupyter and Zeppelin). Beyond custom code and Spark, the platform has partnerships with a significant number of Machine Learning SaaS providers & toolkits. You can directly hook in Databricks (Spark-as-a-service), DataRobot, H20.ai, AWS SageMaker, and others, directly into your Snowflake compute layer, and begin extracting insights immediately. [Sadly, Alteryx is not a partner here. More on that later.]
Data Ingest
The platform has a rich data pipeline capability that can import from batch or real-time data. Snowflake can handle a continuous firehose of data, as it can continually scale. Just as they have integrations with partners and tooling on the query/analytical side, they also have ingest tools within the platform, plus a huge number of integrations to outside tools around data pipelining. They can work with a wide variety of ETL and data streaming services in order to get data into the Data Lake. Alteryx is a partner around data prep, as is Datameer, Streamsets, Talend, AWS Glue, IBM DataStage, Informatica, Fivetran, and others.
But even those data ingest techniques might not be needed. One benefit to having a Data Lakehouse is ability to get away from ETL and instead do ELT, which is putting the transform stage (data prep) after the data is loaded into the database. Snowflake is ideal for this shift in how data prep is performed – you can now load the raw files into Snowflake using simple COPY commands, and then start refining it from there into new datasets, manipulating it (enriching, cleaning, filtering, sorting) in stages as desired. This makes it so much easier for data engineers to corral the vast pool of data! Plus there are other native capabilities to ingest data; you can automate feeds that directly copy in data from cloud provider storage (S3 or Azure Blog) using their Snowpipe tool.
Ultimately it comes down to flexibility. Snowflake can ingest data in simple ways (that then require data engineeer to refine/improve the dataset from there) or can use the more complicated ingest tooling from a wide variety of partners to import the refined data. That flexibility is especially helpful if those tools are already in use at your enterprise. Already an Alteryx customer and have existing data prep pipelines? Hook them right up!
Developer Tool
So far the use cases are around enterprise data, with the ease of sharing out of that and having a marketplace over published data. However, Snowflake is also well positioned to be a development tool providing managed data storage.
Snowflake platform does support ACID-compliant transactions, but let's be clear - it is not a "normal" database and is not going to replace the many use cases for relational or NoSQL databases. If an app is needing to do lookups and updates on lots of individual records, this is NOT the database of choice. But if the app or service is analytical in nature (doing rolled up aggregations of individual fields, or analyzing over vast quantities of data), Snowflake is a fantastic choice as a cloud-native database provider... and one that can be scaled as needed.
For instance, MongoDB ($MDB) is great for many non-analytical uses, but certainly a large subset of their customers are utilizing it as an analytical store for capturing and analyzing semi-structured data. MongoDB markets itself as an analytical data store and has several products around this focus, including Atlas Data Lake and how Atlas users can utilize isolated analytical nodes. Snowflake's primary purpose tackles exactly that use case quite well – and not just over semi-structured data, but also over structured (relational) data as well.
So I do see the potential for certain types of workloads to move off of other cloud-native managed data stores and on to Snowflake, whether NoSQL (MongoDB Atlas, AWS DocumentDB, Azure Cosmos DB, Google Cloud Datastore) or relational (AWS RDS, Azure SQL Database, Google Cloud SQL, Google Cloud Spanner). These types of managed data services are especially appealing to dev teams using serverless platforms. Since they aren't maintaining their own infrastructure for their code deployment, they assuredly do not want to manage any underlying database as well! Development teams are starting to be cloud-native in the serverless paradigm, and Snowflake fits in very nicely there, as a building block that software companies can use as the foundation for their apps and services. I could see developers preferring the flexibility of being able to intermingle relational and NoSQL data in Snowflake as a major point in its favor in some head-to-head evaluations, so I foresee Snowflake being a platform powering many apps and services from here, especially ones that cull insights from incredibly large amounts of data. For example, an IoT monitoring service could be pulling in device data from around the globe and performing analytics over it. All of that can be achieved within Snowflake.
So that sums up their platform's use cases, which all combine to look something like this:
Unique Database Features
As a database developer, I find these features to be pretty unique for a database platform, which are enabled by them being cloud-native.
External Functions
Snowflake embeds the ability to call remote services from within the Snowflake platform. It can call any HTTP-based service, including serverless functions on AWS Lambda and the like (so can be written in any language). If you are familiar with database terminology, these behave like User Defined Functions (UDFs) that you can embed within SQL data queries. What it all boils down to it that customers can embed custom logic and data manipulation functions into their databases and/or their SQL queries. This greatly increases the flexibility of the database features; you can do most anything to your data inside Snowflake.
Data Masking
Snowflake allows data owners to dynamically control who can see what field, via a feature called Dynamic Data Masking. This allows setting up different rules per field, based on security roles, to allow for hiding (masking) part of the data. An example is allowing certain users to only see the final digits of a social security number or credit card number, instead of the full number. The underlying data is all there, but since the service layer is controlling security, it is also controlling what the data looks like when giving back query results. It seems a fantastic feature to have inline in the platform – this normally has to be handled in the client applications accessing the data, through complicated internal database functions, or by data engineers manually during the ETL process in Data Warehouses.
Data Recovery
Snowflake has a feature called Time Travel that tracks all changes or deletions of data within a set time frame (based on the pricing tier). It acts as a historical audit trail that allows customers to step backwards over time (akin to Time Machine backups on MacOS), so they can recover lost data or revert incorrect changes to data or the database structure (schema). It is directly accessible right inside the SQL query engine, by using a "BEFORE" keyword to specify the point in time to query. This is NOT a common feature in other platforms, and, as a database developer, I find it quite powerful.
Most database engines only have snapshot capabilities for full database recovery, but that is more to capture the entire database's state and to be able to recover it if needed. Snowflake also does snapshotting, but as automated feature called Fail Safe, which creates and keeps snapshots over the 7 days prior to the Time Travel limit of the customer. But this feature is mostly hidden from customers, and is only to be used in critical data recovery efforts. [So they are pushing using Time Travel first, and Fail Safe as a last measure.]
Platform Tiers
The platform is comprised of 3 layers - storage, compute, and services. Let's walk through the technologies quickly, from the inside out, plus a few of the other ancillary features, to look at what drives the internals of the platform.
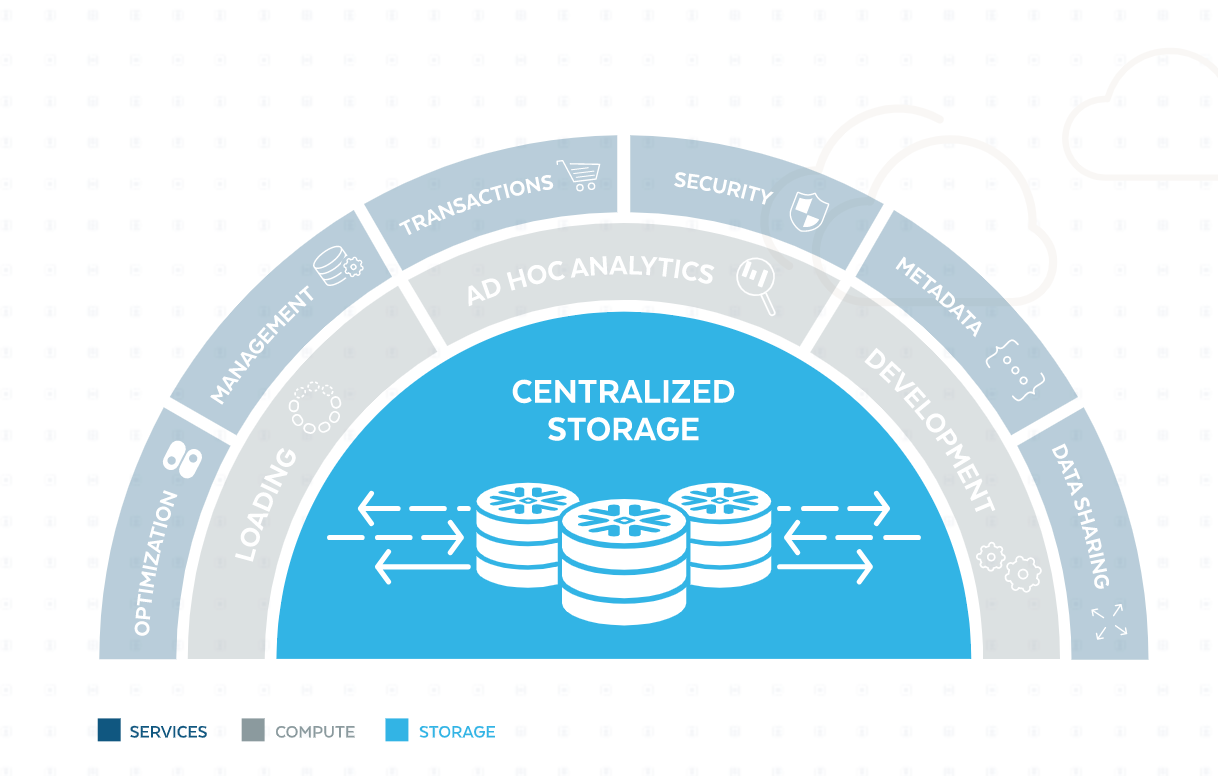
Centralized Storage
The core of Snowflake is a data engine over the native blob storage capabilities of each cloud provider. This means it uses AWS S3, Azure Blob, or Google Cloud Storage (GCS) depending on the cloud provider the customer chooses to utilize. The underlying raw data is in columnar stores, which are compressed and encrypted. Customers are not given access to the raw files in shared storage - all access is managed by services layer and performed by the compute layer.
The raw data of a dataset is automatically divided up into segments (called "micro-partitions") <500MB in size. This is a common architectural paradigm in clustered data engines, as it allows the engine to easily replicate segments, which then allows for distributing the data (and compute over it) evenly across the platform cluster. This partitioning allows the the Snowflake platform can handle datasets of ANY size. If the customer is throwing in petabytes of data, internally that is broken up into bite-sized segments that the platform cluster can store, replicate, query and analyze in a distributed way.
Compute
Compute is comprised of clusters of compute nodes for ingest, querying, and analytics. Unlike the storage and services layers, there is nothing shared in thie tier – each customer has their own dedicated compute cluster(s) called virtual warehouses.
The compute layer takes advantage of the native compute engines in each cloud provider, in order to be physically located as close as possible to the storage it covers. Just as the platform breaks up all the data storage into micro-partitions, it is also creating and scaling separate compute nodes per customer over that storage (the "virtual warehouses" discussed above). This architecture is called massively parallel processing (MPP), where the compute cluster is breaking up queries into separate sub-queries across the individual compute nodes, each handling a portion of the distributed data (those micro-paritions) it is querying. This allows it to be able to process huge amounts of data quickly, and can scale to work over incredibly large (> petabyte-sized) datasets. This is ultimately is what makes the inline analytical capabilities so exciting, in that customers can also directly get access to the performance benefits of MPP and data locality, in order run analytics over immense amounts of data.
Customers are able to specify the exact compute capacity they wish to pay for, and that controls the limit of how many compute actions can occur simultaneously. If the compute gets too many requests, it will queue up until it is able to handle the overflow. Customers can scale up the compute capacity as needed, entirely separate from the storage costs.
Services
Services modules are the brains on top of the brawn (compute). They provide an API for management of the data, security roles, data sharing, transactions, and metadata (data fields and how they are partitioned). All queries run through Services (which analyzes the metadata to determine which micro-partitioned columns to process in the query), and is where security and data sharing capabilities are deeply embedded. It formulates what the query needs to do, then passes it on to the compute engine to perform. It takes the answers and gives them back to the requesting user, performing any final tasks like data masking.

The services layer also exposes some serverless features that are billed separately from compute:
- Snowpipe = Automates ingesting data from S3 or Azure Blob files.
- Database Replication = Replicates your data across regions & cloud platforms.
- Materialized Views Maintenance = Re-generates materialized views when underlying data changes.
- Automatic Clustering = Maintains optimal cluster state in how data is distributed internally.
- Search Optimization = Indexing service that speeds up lookup queries into massive tables (allowing customers to lower the compute size to lower costs).
Data Sharing
Data sharing features are also controlled by the Service layer, with highly granular access control over the original datasets being shared, and what users have access. There is minimal cost to share data in this way, as the data is not moved or copied.
Data Exchange allows for creating specialized databases that are sharable between partners for collaboration and data exchange. The Data Exchange uses its own virtual warehouse (scaled compute), with costs shared by its members. Data Marketplace is where customers can publish datasets. This will enable all new monetization efforts in enterprises wishing to leverage their data, as well as allows for publishing data and for enabling subscriptions to it.
Integrations
Besides exposing scripting capabilities around ingest and performing analytics – it also has an ecosystem around those points, to directly integrate with a wide variety of SaaS providers. This enables customers to continue to utilize the tools they already have invested in for data pipelines or analytics, or to utilize outside platforms for features that are unavailable in Snowflake.
A sampling of the many partners & tools available:
- Ingest/Refine Tooling: Alteryx, Datameer, Streamsets, Talend, AWS Glue, IBM DataStage, Informatica, Fivetran, Rivery.io, Snowplow, Matillion, Segment, dbt.
- BI Tooling: Tableau, Azure PowerBI, Qlik, Sigma, ThoughtSpot, Looker (Google), AWS QuickSight
- Data Science Tooling: Qubole, Alteryx, Zepl, Dataiku, Databricks (Spark-as-a-service), DataRobot, Sisense, Domo, H20.ai, RapidMiner, BigSquid, AWS SageMaker
- Data Science Libraries (Inline in Compute): Apache Spark, TensorFlow, Pandas, PyTorch, scikit-learn, Jupyter, Zeppelin
Snowsight
Snowflake released a new analytics UI in June 2020 called Snowsight, from the acquisition of Numeracy over a year prior. It provides an interactive SQL editor with embeddable charts, so business analysts can create custom dashboards to monitor data and provide insights.
- Ad-hoc querying
- SQL editor with auto-complete
- Modern dashboards & charts
- Interactive results
- Sharable charts with private links
It is not going to replace more complex BI & analytical tools, but does let power users do ad-hoc data exploration, simple analytics and dashboarding, akin to Elastic Kibana, MongoDB Charts, or Grafana custom dashboards. This starts to show you where Snowflake can go from here; it can start providing more native tooling at the points in the platform that it allows integrations (ingest, BI querying and analytics).
Pricing
Each customer determines the storage and compute size that they wish to engage, based on the responsiveness and performance they want. The customer only pays for what they use between storage and compute. Separation of compute and storage planes means you can scale either side independently, based on need.
Storage is ultimately inexpensive, the true cost of use is in compute for the ingest, querying, and analytics performed. Pricing is in arrears, but they provide discounts for pre-paying compute in advance (via what they call "Snowflake credits"), as it helps them in capacity planning within their platform clusters. Compute clusters are only billed for active compute cycles (idle time is ignored).
The customer is billed for:
- A fee per terabyte of compressed data stored, averaged per month, billed in arrears.
- Virtual warehouse (the scaled compute layer each customer spins up for ingest and querying) is billed by the compute-second, with a one-minute minimum. Customers can deactivate it when not utilizing it.
- Cloud Services (the services layer that provides data management, coordination, security, and ancillary services) can also be billed. Typical utilization of the standard services is free, but heavy users will see incremental charges above the norm. A few ancillary serverless functions exist that cost by second of usage for the exact compute time used.
- Data transfer fees, to recoup cloud provider fees if transferring data between cloud regions or out of a cloud provider.
There are different billing methods. From their pricing guide:
- On-Demand Billing is charged a fixed rate for services used, billed monthly in arrears. It is the priciest option.
- Pre-purchased Capacity Billing has customers paying a specific dollar commitment to Snowflake, paid in advance for a set term. This ultimately lowers the price (as it allows Snowflake to pre-plan capacity), and customer pays via Snowflake Credits.
- Snowflake Credits are pre-paid credits used to pay for usage of compute resources: when the virtual warehouse is running, the cloud services layer is performing heavy work, or serverless services are used.
Pricing Tiers
There are several pricing tiers (called "editions") based on a customer's needs and security requirements.
Standard
Full unlimited access to all Snowflake features from a single virtual warehouse.
- Single compute cluster
- Secure data sharing across regions/clouds
- 24x7x365 support
- 1 day of Time Travel (data history tracking)
- Encryption in transit and rest
- Database replication
- External functions
- Snowsight
- Data Exchange (shared data spaces w/ partners)
- Data Marketplace access (published datasets & subscription mgmt)
Enterprise (Standard +)
More support for large-scale enterprises and orgs, especially around enhanced security. Larger capacity, enhanced inline security features, and longer history tracking.
- Multi-cluster compute (very useful for having hot/cold data, improving HA, having geo-located copies of data)
- 90 days of Time Travel
- Annual re-key of encrypted data
- Materialized views (pre-computed data snapshots of a point in time)
- Search optimization (managed indexes over large datasets)
- Dynamic data masking (hide fields based on user's role)
- Inline data encryption at rest (only customer can unlock especially sensitive data)
Business Critical (Enterprise +)
Enterprise version particularly for strict regulatory requirements like HIPAA & financial sector. Expands on data recovery features for resiliency & business continuity.
- HIPAA support
- PCI compliance
- Extreme focus on security
- Data encryption everywhere (only customer can unlock)
- Database failover and failback
- AWS & Azure Private Link support (directly connecting your enterprise network to the cloud, to avoid going over public internet)
Virtual Private Snowflake [VPS] (Business Critical +)
Completely isolated version of Snowflake, for the most stringent orgs requiring the highest security and no intermingling of infrastructure. VPS is isolated onto a completely separate cloud environment with no shared resources.
Customers
Customers include Capital One, Square, S&P Global, Bankrate, Sony, Adobe, Akamai, Square, Blackboard, Lime, Instacart, Sainsbury's, Neiman Marcus, Boden, Cemex, Paccar, Micron, Hubspot, Coupa, Talend, Overstock, Office Depot, A&E, EA, LionsGate, McKesson, Logitech, Doordash, Penguin Random House, RueLala, Rent the Runway, Univ of Notre Dame, Oregon State, ... and a crap ton of startups and apps and data brokers that have been built on top of their data cloud or Data Marketplace. Largest customer is Capital One, at 11% of revenue and shrinking – it is lowering because Snowflake is growing so fast, even as Capital One nearly doubled its spend YoY!!
Capital One spent $29 million with Snowflake in 2019 and in 2018, it spent ~ $16 million.
— Ryan Reeves (@investing_city) August 25, 2020
Yet, as a customer, it shrank as a percentage of revenue from 17% to 11%.
That means, excluding Capital One, Snowflake's business grew 200% last year. 😱
Customer reviews on Gartner Peer Insights (under Data Warehouse and Cloud Data Platform categories) and G2 tend to rate it highly. Some of the few negatives center around the UI – but they are clearly starting to address that with the new Snowsight product. Customers seem to choose it for a variety of reasons, but typically cost, performance, scalability, ease of use, secure sharing, and flexibility all show up amongst the primary reasons given.
The CEO of Okta ($OKTA) recently tweeted a list of what they focused on in choosing Snowflake.
Interesting that we moved to @snowflake for 3 reasons. 1> it was cheaper 2> easy to burst capacity (thank you @aws cloud) 3> easier to get data in and out and share data internally between groups
— Todd McKinnon (@toddmckinnon) September 9, 2020
What other customers have to say:
"Sainsbury’s Argos marketing query times have plunged from six hours to three seconds." - Helen Hunter, Chief Data & Analytics Officer, Sainbury's
"No one has even seen anything this agile that allows you to get to your business that quickly with reporting and data science elements until Snowflake arrived on the scene." - Kelly Mungary, Director of Enterprise Data & Analytics, Lionsgate
"We are an early adopter of Virtual Private Snowflake because it gives us the ability to process data at lightning fast speed and deliver automated, intelligent solutions to our customers in real time." - Linda Apsley, VP of Data Engineering, Capital One
Competitors
There is intense competition in the primary use cases of data warehouse and data lake, primarily from the cloud providers themselves (who Snowflake has to rely upon for all its infrastructure).
Data Warehouse (OLAP)
For just the data warehouse and BI capabilities, Snowflake competes against a number of deep-pocketed stalwarts – the cloud providers themselves, as well as the legacy analytic database players like IBM, Oracle, Teradata, and SAP, who are all playing catch-up with the cloud. These are all massive leaders in the database industry, yet Snowflake continues to weave through them as it eats up customers and executes at hypergrowth.
- AWS Redshift
- Google BigQuery
- Azure SQL Data Lake
- Yellowbrick Data Warehouse (pure SaaS)
- Panoply Data Warehouse (pure SaaS)
- Oracle Autonomous Data Warehouse
- IBM Db2 Data Warehouse
- IBM Cloud Pak for Data System (part of which used to be Netezza)
- SAP Business Warehouse over HANA
- Teradata Vantage Data Warehouse
- Vertica
Beyond those solutions, companies could it DIYing it with OLAP-friendly databases like:
- Presto (open-source distributed SQL engine)
- Apache Pinot (open-source distributed OLAP database)
- Apache Druid (open-source distributed columnar analytical database)
- ClickHouse (open-source distributed columnar analytical database)
- MongoDB Atlas for data analytics
G2 has ranked them consistently as Top Performing Leader in Data Warehouses the past 2 years. They are clearly a Category Leader, with the cloud providers right behind (well... at least AWS and Google).
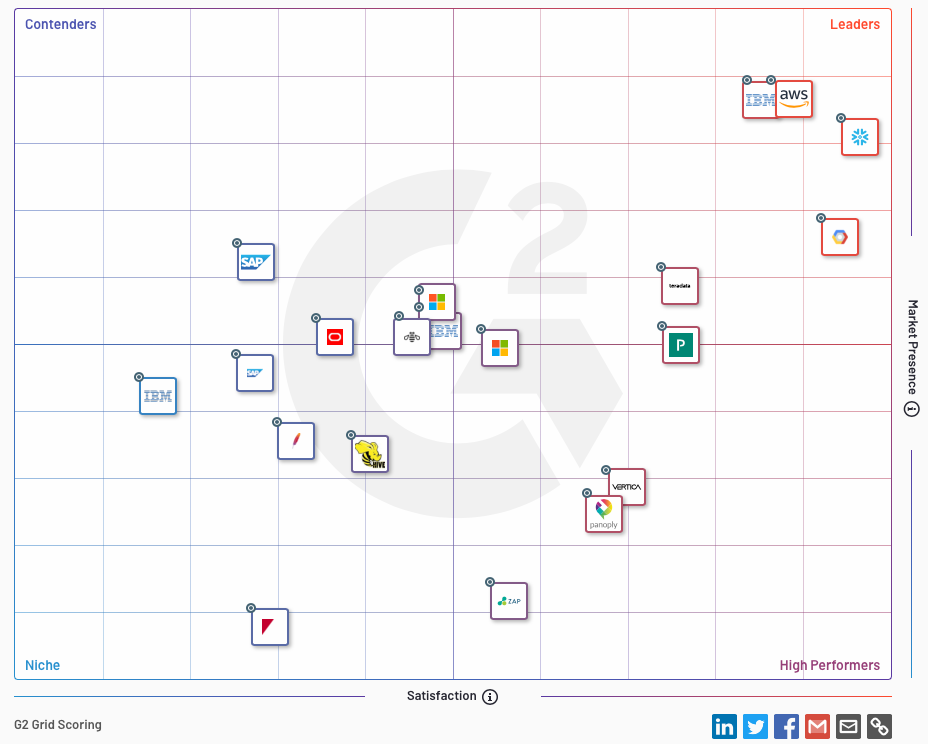
Of those legacy players, IBM has 3 separate entries on the G2 chart, and SAP has 2. Does this seem like focused competitors, or more like behemoths desperate to keep existing customers (who are migrating off their legacy on-prem solutions and on to the cloud)?
Data Lake w/ Analytical capabilities
Competition here is primarily the cloud IaaS providers putting together their own solutions, those legacy database players again (trying to stay relevant in the cloud-era), and Databricks and MongoDB to some degree.
- AWS Lake Formation (AWS Redshift + AWS Athena + AWS EMR for Spark + AWS SageMaker for ML)
- ... or AWS + Databricks (the above, but w/ Databricks for Spark)
- Azure Synapse (Azure SQL Data Lake + Power BI + Azure ML + Azure HDInsight for Spark)
- ... or Azure + Databricks (the above, but w/ Databricks for Spark)
- Google Cloud (BigQuery + Cloud Dataproc for Spark + Cloud ML)
- MongoDB Atlas Data Lake [AWS only]
- Qubole Data Lake (pure SaaS)
- SAP HANA Cloud Data Lake
- Oracle Big Data Service
- IBM Cloud Data Lake (IBM Cloud Warehouse + IBM Db2 Big SQL + IBM Watson Studio for ML)
Customers could also being doing it DIY by using a wide variety of open-source platforms for data lake storage – including Apache Hadoop (if they are masochists), or using Databricks Delta Lake, an open-source service layer to make data lakes over cloud native storage. They could then build analytical capabilities over that data lake via open-source Apache Spark or custom Python/R programming using open-source analytical libraries, or could offload that work by hiring Databricks or other analytics providers to handle that part.
Snowflake shines because it simplifies all these choices. Customers can get a turnkey data cloud (which can be both a Data Lake & a Data Warehouse) that drives all of the analytics (BI and data science) being done across the company – and so much more (shared data pools, published data marketplace, DBaaS underlying an application).
Partnerships
Snowflake's platform provides a high level of flexbility at the edges of the platform (ingest, query, and analytics), which enables customers to either create and run these processes themselves (using custom ingest or analytic scripts), or allows them to leverage the rich ecosystem of cloud-based tools out there. Snowflake wants to enable customers to have maximum flexibility, and to be able to use the tooling they already have invested resources into.
And the tooling that these integration points expose keep getting better and better. New SaaS solutions are emerging that are now made possible by these modern cloud data architectures – many of which got their start because of the challenges remaining in these workflows, and the fact that legacy tools were not adequate.
- Dbt was built to manage the lifecycle of data refinement through the use of materialized views. This is allowing data analysts to drive the refinement process, not data engineers.
- Rivery.io, Snowplow, Segment, Matillion, and Fivetran are all SaaS startups that serve as an integration provider for data ingest, creating centralized & easily managed pipelines for exporting data out of SaaS applications and into cloud databases. These are greatly simplifying how data movement is handled by data engineers.
- But Segment, in particular, goes way beyond ingest. They serve as a data pipeline on both sides of the database, with a specific focus on customer data. Besides data ingest, they allow for creating pipelines to extract analytical insights out of the data warehouse, loading it back into sales & marketing tools. This enables business users to gain enormous insights into customer/shopper/user behaviors, to help with product innovation and marketing efforts. It also provides software development tooling in order to integrate with and extract insights from mobile app and website users – which seems similar to Datadog's Real User Monitoring (RUM) product.
- Sigma, Sisense and Domo are SaaS providers providing modern BI analytic and dashboarding tools that can sit over external cloud data warehouses, and help extract insights. This is letting business users do more, minimizing the need to work with a data analysts. And it is also eliminating the need to make additional copies of the data, as they directly sit over & integrate with cloud databases.
Snowflake could ultimately decide to build (or bolt-on) more native tooling in its platform around these customer needs. It has begun to do so, with its new Snowsight tool for BI dashboarding (which arose from its first acquisition).
Analytical Tools
However, on the analytical side, the lines get get blurry in a hurry with partners in this space. For example, they partnered with Qubole in 2018 to allow customers to use that SaaS provider to run Spark – but, Qubole is also a direct competitor, being a cloud-native data lake platform. The fuzziest partnership is with Databricks, the enterprise company around open-source Apache Spark. They are a Spark-as-a-service provider who have simplied Spark's use (allowing users to develop ML via a no-code UI, instead of scripting). They have been able to interject their cloud service into AWS and Azure as a vendor-neutral tool to help businesses manage and run analytics. They also have a partnership with Snowflake, who highlights them as a ingest pipeline (Spark for data processing), and analytical platform (Spark for ML). Snowflake for all the data handling and security and performance and compute, and Databricks for extracting all the insights from it.

But Databricks didn't stop moving. They created an open-source engine called Delta Lake (a service layer over cloud storage, to make it a queryable data lake), and is also integrating with BI tooling directly (Tableau, Qlik, Looker). This is eliminating Snowflake in that chart above! And Databricks also has one of Snowflake biggest advantages - being vendor-neutral, and enabling multi-cloud strategies.
I'm not concerned about the dual role these partner-competitor relationships have (as Snowflake has with cloud providers in general), but I do recommend closely watching where the analytical relationships go from here. Data & Analytics is a huge market right now, so I cannot help but wonder if this is a potential area that Snowflake might start to develop its platform capabilities further. It could make the use of Spark easier to use (exposing it via a no-code UI), or start adding more ML creation or automation capabilities directly in the platform. Snowflake could also expand its data pipeline capabilities on the ingest side, via acquisition or developing its own pipeline solutions. If it starting going any of these directions, that would be moving in towards Databricks's slice of the market (just as they are doing to Snowflake).
For now, Snowflake is content to enable customers to do it themselves, by exposing these integration points within their compute layer. They will keep adding more and more ingest, BI & analytical partners to exploit making data pipelining & analytics easier.
Citizen Scientists
That brings us to Alteryx ($AYX). Any future moves by Snowflake and Databricks into data pipelines and model automation would compete with their platform. Snowflake first announced a partnership with Alteryx back in Nov 2017, and they are featured on Snowflake’s sales deck as an ingest partner. The platform fully supports using Alteryx to do data prep and manipulation, to then save the data into Snowflake’s database. This is a major use of the Alteryx platform -- all the data pipelining steps you must do before the analysis. But this is starting to be disrupted, however, by all the plug-in ingest integration providers that are now sprouting up (like Snowplow and Fivetran mentioned above), as well as the shift occuring in the refinement process that has been enabled by Data Lakehouses. Data engineering workflows are moving from ETL to ELT, where the data processing & transformations can be done directly within the database. Alteryx is not as valuable to the ingest process if users are directly doing refinement & transformations within the database.
But what about the analytical side? Snowflake ultimately allows data scientists to run analytical code inline in their compute nodes, but Alteryx is not currently supported on this capability. Alteryx can obviously still run analytics over Snowflake data as a SQL client – which does get processed in Snowflake’s compute. But it cannot not run the subsequent analytics inline within Snowflake’s distributed compute nodes, so it cannot harness the speed & locational benefits of running side-by-side with the data. And that process is having export the data out of Snowflake, and into the Alteryx platform (thereby making a separate copy of the data), in order to run models. Same with any other analytical tool that isn't a direct partner of Snowflake – any SQL-based analytics tool can maintain their own separate copy of the data by querying it out Snowflake.
I think there is a serious benefit, however, to running the analytics directly in the compute nodes, taking full advantage of the platform's multi-parallel processing architecture. Insights can now come in near-real-time, right from the raw data, not hours or days later. New startups will emerge that are able to run the analtyics directly over the cloud database, and that can take advantage of the parallelism of compute & the efficiencies of cloud-native storage built into Snowflake's platform, and so do not need to maintain separate copies of the data.
We know that Alteryx is now making stronger moves into cloud compute under their new APA platform (see my prior writeup), and getting heavily into automation of ML, which involves using ML to determine the best model for a situation (feature engineering). Going forward, I would love to see Alteryx more tightly partner with Snowflake, in order to run their models directly within the distributed compute nodes. That would be a really powerful combination, given Alteryx's initiatives around “citizen data scientists”, which focuses on increasing the skillsets & tooling of data analysts and business users, so they can do machine learning too. I believe the inevitable rise of the "citizen data scientists" will GREATLY benefit Snowflake, as it would greatly empower a wider and wider user base using Snowflake for analytics – which would further blur the line beween Data Lake and Data Warehouse. It feels like we have only just begun to scratch the surface with what is possible with analytics, ML and AI. And because Snowflake serves as the ever-growing data hub for enterprises, I feel that every advancement in analytics from here will only make the platform more and more appealing – regardless if Snowflake tries to help improve the analytical workflow process, or lets integration partners do so.
Conclusion
Snowflake is a turnkey data cloud that can drive all analytics over an entire enterprise, helping customers solve a wide variety of use cases. It is simple to use, yet remains highly flexible for power users, who can directly integrate with an ecosystem of ingest and analytical tooling. They have a large TAM that is likely to rapidly rise over the next few years, as more and more large enterprises & SMBs realize the potential of cloud-driven data & analytics, and the value it can unlock within their data.
Platform Strengths
- Cloud data & analytics platform-as-a-service
- Elasticity of being cloud-native; capable of near limitless scale
- Vendor-neutral, operating across all 3 major cloud providers (AWS, Azure, GCP)
- Enables customers to adopt a multi-cloud strategy, giving them leverage over cloud providers
- Distributed platform architecture, improving performance & resiliency
- Performant as possible, being closely tied to each cloud providers' native storage & compute layers
- Easy to use; no maintenance (and very little management) needed by customers
- Usage-based pricing; pay for on-demand monthly use, or pre-pay for set usage over a term (lower cost)
- Scalable compute layer and multi-cluster capabilities (a cloud-within-a-cloud) allow each customer to hone their usage around performance, concurrency, and cost level desired
- Extreme focus on enterprise-level security, governance, and compliance
- Diverse data types & formats supported (both relational and semi-structured data)
- Exposes inline analytical capabilities to customers, that run within the platform's distributed compute engine (akin to Hadoop-as-a-service)
- Wide number of use cases with different user bases
- One copy of the data can serve multiple workloads
- Seamless & secure data sharing capabilities
- Data Exchange feature for pooling data between partners
- Data Marketplace for publishing and monetizing data
- Managed database service for data-driven apps & services
- Broad ecosystem, with a wide variety of partners and tools for ingest, BI querying and analytics
All in all, this makes for a really interesting company -- one that happens to be executing at the highest levels in the rising Cloud Data & Analytics industry.
Don't everyone go rush to buy it next week. [I get first dibs.]
Add'l Reading
Public Comps posted a teardown of S-1 and financials, which I think serves as a great companion piece to this one. In particular, I love the SaaS industry comparibles that they provide. I don't get into the numbers much above because they already did, so thanks to @jonbma and others across Twitter that I link above.
If you cannot get enough to read about Snowflake, there is also this long-form post that appeared earlier today by group of analysts in The Generalist's S-1 Club (a new tech investment blog spun out of a VC firm). I got more value from the (much more compressed) Public Comps post above, but if you want to look deeper at Snowflake from lens of a VC (such as getting into the details of the financing rounds), read this. They are also going to have a virtual roundtable on Snowflake on the evening of 9/12/20.
Snowflake's white paper on the Data Science capabilities of its platform. This is clearly a major focus of theirs (and should be), and I expect further enhancements and integrations in this area.
Snowflake commissioned a study by Forrester of the total economic impact of the many benefits and use cases of their data cloud. It all adds up, but most of all, the speed it lets enterprises move at makes such a huge impact.
CNBC had an interview with CEO Frank Slootman in Dec 2019 that I found interesting (with a super foggy Bay Bridge traffic jam in the background):
-muji