
I've been following Confluent since its IPO in Jun-21, as the streaming platform continues to press the importance of capturing value from "Data In Motion" – as data moves between databases, services, apps, and end users, across on-prem and cloud environments. Product-wise, there wasn't much news out of Confluent over 2022, but what has appeared on the horizon since its Current conference in Oct-22 has been quite interesting.
Since IPO, Confluent continues to erase many of my prior product/platform concerns [from the end of my paid deep dive]:
- Confluent needs to get users of open-source Kafka to pay for it, and I think they continue to have success here. They are seeing success from the on-demand pricing in their managed Confluent Cloud, and this year reduced the friction of onboarding for trials, and expanded cloud provider partnerships.
- They must lower the Ops burden of managing Kafka clusters, and again they continue to have success here. Cloud remains their biggest area of focus, as customers continue to transition from licensed to managed service, and Confluent Cloud has grown from 18% of revenue to now 37% since IPO. This shift allows them to provide more advanced features like data governance and cross-cloud clusters, and their managed service can be easily interlinked with on-prem clusters via advanced cluster linking. Most recently, they added a new data governance managed service and private cloud interlinks. I continue to want to see them move towards becoming a cross-cloud managed turnkey service (a Supercloud? [paid]) instead of managed infrastructure.
- One of my most important priorities was that they must continue to make it easier to build and manage data pipelines. Beyond managing the infrastructure, using Kafka remains a friction-filled chore for DevOps teams (having to embed SDKs/APIs inside custom applications to use it), which has long needed better tools to democratize access. Their newly announced no-code tool, Stream Designer, is a fantastic move, as it greatly lessens the friction in both building and managing pipelines.
- I had worries about competing data pipelines (Pulsar) and the success of other stream processing systems (Flink, Spark, etc). If you can't beat 'em, join 'em – they have just acquired a managed stream processing service at the start of the year, and will be folding this into a new capability in Confluent Cloud. This will embed the stream processing capabilities of the popular (and competing) Flink engine into their Cloud service.
- I also wanted to see Confluent create more self-contained managed services around data ingestion and specific data needs. In my deep dive, I said "Like with Streamsets for ETL and data processing, Confluent could bolt on a stream analytics service onto their platform that has an easier-to-use flowchart-based GUI." Confluent's recent moves now make that a reality. The no-code tool opens the door to them moving into managed turnkey services around common data needs, like cross-cloud data integration/ETL. The new acquisition of this managed stream processing service can now be embedded into the no-code tool to become an "open format" cross-cloud stream processing engine atop Confluent Cloud. This will open up customer choice as to which engine to use, but with no custom development needed or separate infrastructure to manage. Their wide variety of use cases can turn into specific recipes (ready-to-use templates) that users can easily deploy via no-code/low-code directly inside the data plumbing of Confluent Cloud.
The Bigger Shifts
Let's dive into the bigger GTM and product moves of the past year in their platform.
Expanding Cloud Partnerships & Interconnects
Over the past year, Confluent has extended multi-year partnerships with both AWS in Jan-22 and Microsoft Azure in Apr-22, adding more joint GTM efforts to co-sell in their respective marketplaces. Confluent then won Microsoft's Commercial Marketplace Partner of the Year a few months later in Jun-22. Mgmt claims a lot of success from these new co-sell efforts – as I highlighted from the Q322 earnings call in Nov-22:
CFO in Q&A: "Well, we don't break those out specifically, but what I can tell you is, we saw tremendous growth from all the three main cloud service providers through the marketplaces. We saw like the best growth that we've seen in a long time from all three. So, when we look at the overall mix of business, primarily where we sell direct to our customers and oftentimes we fulfill through the channel. But the marketplace business that we do with the three cloud service providers is definitely an accelerant and it's been a bright spot for us specifically this past quarter."
CEO later in Q&A: "I think it's a tailwind. So the way the marketplace has come into play, it's a little bit of a lead gen thing, but the bigger aspect is that companies have significant committed spend with the cloud providers and it's possible to buy products through that through your marketplace agreement. And so you could think of that committed spend as kind of a shadow budget that's flexible across different things that you could purchase. ... It also provides a great mechanism for cooperation with the cloud providers, right? What motivates them is both that marketplace consumption as well as the flow of data into all of their other services, which kind of helps drive utilization and consumption in their cloud. And so both of those are the things that are going to activate their kind of go-to-market teams to help. And so we think these are great programs. We've leaned heavily into them and been quite successful."
These comments by the CEO really highlight how these co-sell partnerships are a win-win for both them and the cloud provider, as partnering with Confluent helps bring more data into their data & analytics services across data warehouses, data lakes, analytical engines, and ML services. Despite AWS's many competing services (like Managed Streaming for Kafka [MSK] and Kinesis), Confluent is a highly valued partner – so much so that they participated in an ISV fireside chat in the Partner keynote at AWS's re:Invent conference in early Dec-22, with Confluent being noted as one of the leading infrastructural ISVs that AWS partners with.

Confluent continues to expand its private networking features across the cloud providers, and you can now use Confluent Cloud to move data across private networks to all 3 major hyperscalers. Their Q3 release in Jul-22 mentioned Confluent Cloud supporting private network connectivity to AWS and Azure, and in Oct-22, they added GCP. This again feeds the customer demand for hyperscaler services like AWS & Azure PrivateLink.
Free trials
Confluent Cloud's on-demand pricing, ease of onboarding, and new co-sell partnerships across cloud marketplaces had been greatly boosting the growth of paying customers, adding +1000 net new customers over Q421-Q122. Confluent then adopted a more friction-free onboarding process in Q2 [as previously discussed in paid] to allow customers to sign up for trials of Confluent Cloud without a credit card. While this has greatly impacted the growth trend of paying customers (flattening it for last 2Q), it is surely going to get more eyes on their Cloud product. Unfortunately, we can no longer see the success of trials in reported KPIs.
Stream Designer
Stream Designer was the biggest announcement out of their Current conference in Oct-22. It provides a no-code/low-code visual interface for creating, testing, and deploying data pipelines and inline stream processing, and then gives users an end-to-end view to manage and observe their running pipelines. Stream Designer is only available in Confluent Cloud, which shows how Confluent can start leveraging its managed cloud service to provide new tools.
Stream Designer allows users to tie together all of the various components across Kafka (data pipelines), Kakfa Connect (integrations to 70+ external services like databases and object storage), Kafka Streams (stream processing in Java/Scala), and KSQL (SQL-driven engine over stream processing) in one easy-to-use flowchart-based UI, and comes with templates for common use cases. This moves them into competition with no-code pipeline services and tools like Striim, Streamsets, and Apache Nifi.
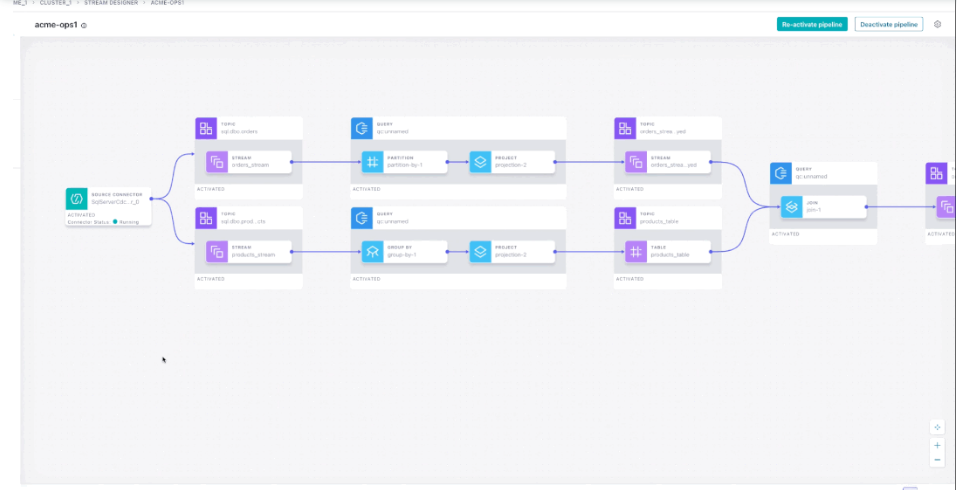
The primary issue I had with their platform (as a former user of Kafka and customer of Confluent) was the difficulty in creating and managing pipelines – this product goes a long way towards alleviating that friction. Stream Designer is long overdue in that it removes these DevOps-facing frictions. You no longer need to use command line tools for connecting integrations, and, of course, this no-code tool continues to work alongside custom apps & services you build that directly embed Kafka capabilities (as the producers/consumers of data). After building the pipeline, the same interface is then used to then monitor the pipelines as they run.
Immerok acquisition
The big surprise early this year was their announced acquisition of Immerok on January 6th. Immerok has some of the founders and leading contributors to the open-source Apache Flink project, a popular data processing engine that combines batch and streaming processing over files & data streams within a single engine. Flink provides real-time query capabilities over data pipelines (in Kafka, Pulsar, GCP PubSub, and AWS Kinesis) and can then write data back into streams or databases.
Think of stream processing as a compute layer that sits over data pipelines (the data plumbing) to allow for advanced capabilities like real-time analytics over time windows or complex data enrichment or manipulation. Apache Flink appears to have won the battle against the other open-source stream processing engines like Apache Samza, Storm, and Heron. As noted before, Flink also competes with Kafka Streams and Confluent's KSQL (SQL engine), as well as Apache Spark Streaming, and, like those, can be used by data engineers and data scientists coding in Java, Scala, Python, and SQL to manipulate or analyze real-time data streams.
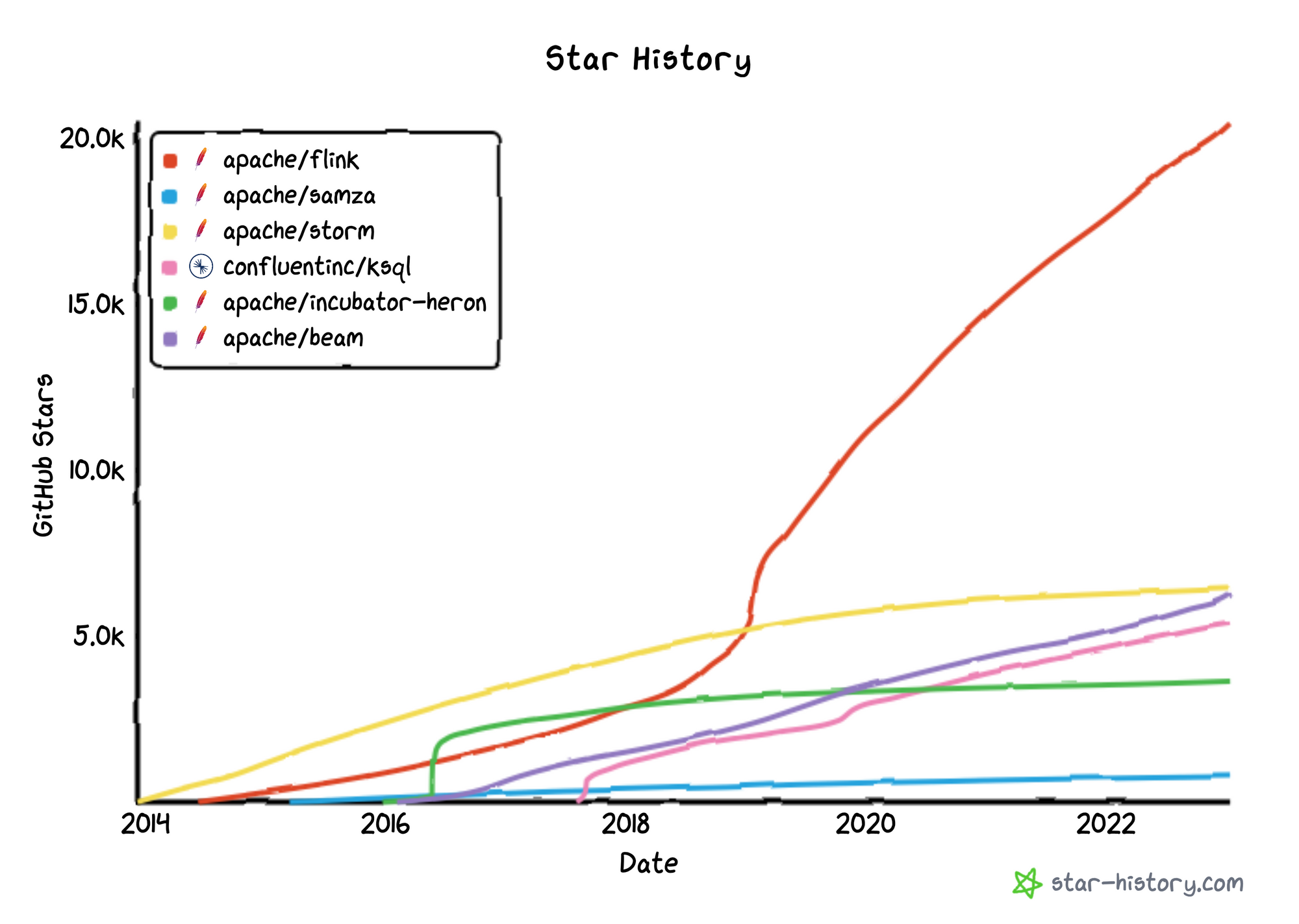
As a brief history, the founders of Apache Flink created German startup "data Artisans" in 2014, which was later acquired by Alibaba in Jan-19 and (thankfully) renamed to Ververica. A number of those founding team members left in early 2022 to found a new German stealth startup. What emerged was Immerok (which per a blog post means "always-ok", aka data always flowing), a new cloud-native managed Flink service for doing stream processing over data pipelines. It exited stealth in Aug-22, and released its new serverless cloud-native Flink service for AWS to closed preview in Oct-22. Dubbed Immerok Cloud, it allowed for deploying scalable on-demand Flink compute instances via cli and web UI for handling use cases like data pipelines, user-facing analytics, real-time ML/AI, and transaction processing. It ties into Confluent Cloud, and after seeing it, Confluent decided to snatch it up.
This cloud-native managed Flink service directly competes with the hyperscaler's own managed Flink services (like AWS Kinesis Data Analytics and GCP Dataflow), as well as their more customizable big data engines (like AWS EMR and GCP Dataproc, both of which can run Flink or Spark). It also competes with dedicated stream processing platforms (Ververica, Decodable, Striim) as well as streaming capabilities within Databricks's Spark engine (Spark Streaming) and Confluent's Confluent Cloud (Kafka Streams & KSQL). This is a very interesting move by Confluent, who at first blush seemed to be taking the "if you can't beat them, join (acquire) them" stance.
Commentary from a tweet (translated): "And with this friends we come to the end of the battle for streaming processing that started 10+ years ago with S4, Storm, Kestrel, etc. Kafka and Flink were the best at what they did, they were forced to get together... even though for a long time they have tried to gain ground on the other."
But this goes way beyond "Flink won the battle", and Confluent has already committed to continuing to invest in the native stream processing capabilities within Kafka (Kafka Streams & KSQL). A blog post by CEO Kreps went into the details:
"In short: we believe that Flink is the future of stream processing. We see this already in the direction of open source adoption, the number of commercial product offerings, and in what we hear from our customers. In the same way that Kafka is the clear de facto standard for reading, writing, and sharing streams across an organization, Flink is on a trajectory to be the clear de facto standard for building applications that process, react, and respond to those streams.
... In terms of our product plans, we plan to launch the first version of our Flink offering in Confluent Cloud later this year, starting with SQL support and extending over time to the full platform. We want to follow the same key principles we’ve brought to our Kafka offering: building a service that is truly cloud native (not just hosting open source on cloud instances), is a complete and fully integrated offering, and is available everywhere across all the major clouds. Beyond this we think the huge opportunity is to build something that is 10x simpler, more secure, and more scalable than doing it yourself. We think we can make Kafka and Flink work seamlessly together, like the query and storage layer of a database, so that you don’t have to worry about all the fiddly bits to manage, secure, monitor, and operate these layers as independent systems. You can just focus on what really matters—building the cool real-time apps that are the real value."
I believe this acquisition enhances Confluent in a number of ways. Product-wise, this is about adding Flink support to Confluent Cloud, a good choice given its popularity. More than being an admission that Flink beat out Kafka Streams, I believe this positions Confluent Cloud more towards supporting "open frameworks for stream processing", to not just limit themselves to Kafka's own in-house version (Kafka Streams). This opens up the tool ecosystem that can be used by its cloud customers, who can now use either Kafka Streams, KSQL, or Flink, plus allows Confluent to integrate a stream processing engine supported by Apache Beam, an open-ended framework for stream processing that is cross-compatible with Spark and Flink (including AWS & GCP's managed Flink). [Beam does not support Kafka Streams, so Confluent has been left out of Beam support until now.] If Confluent is moving into directly supporting open frameworks, then I wonder if Spark Streaming might be added next!
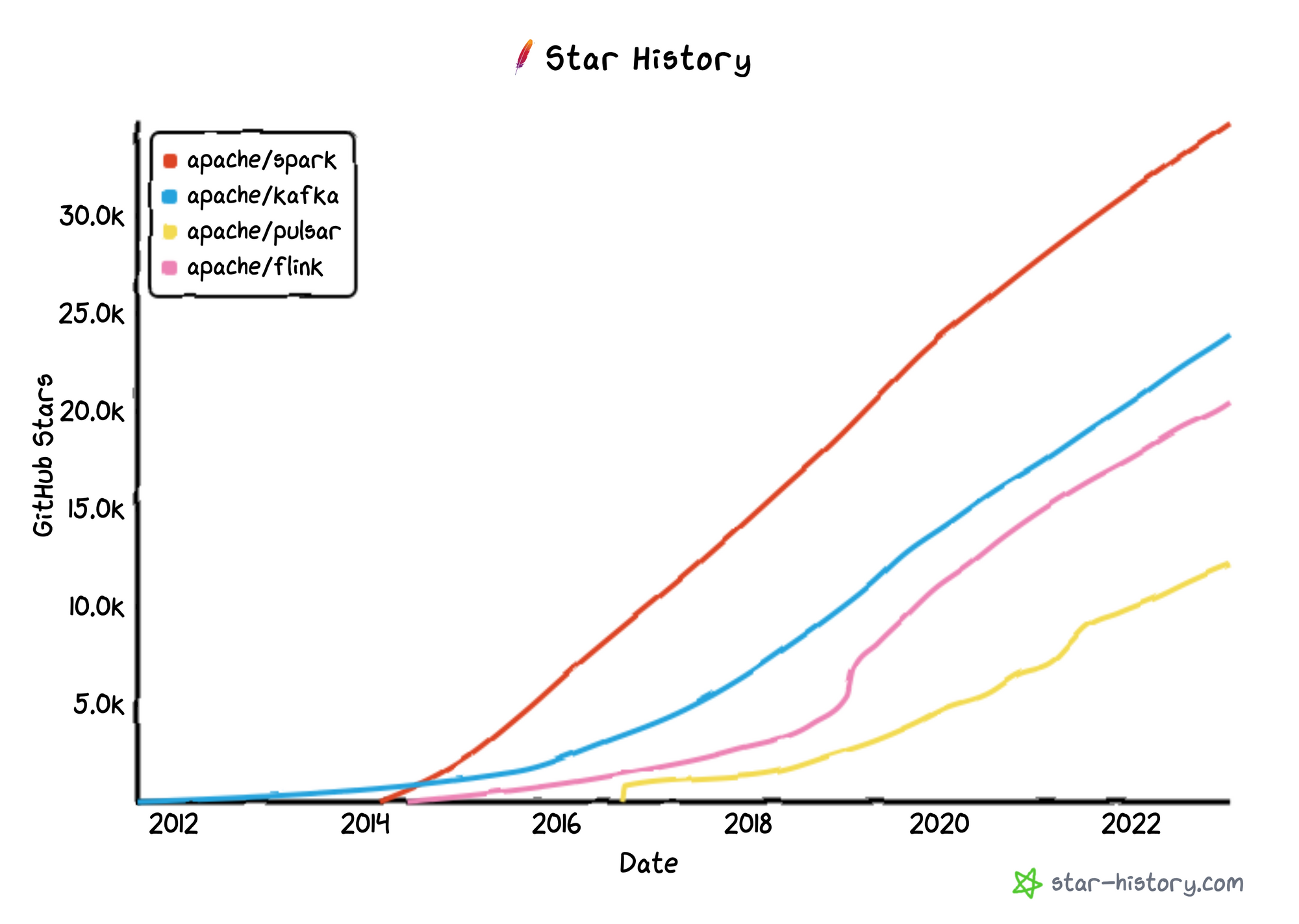
They are instantly becoming a major contributor to the open-source Apache Flink project, but adding another open-source package to their roster is not much of a burden, as Confluent is already the main steward for the Apache Kafka project. More important is the deep expertise they are gaining by adding the founders of Flink to the team. The CEO stated they are adding the Flink SQL-driven capabilities first, then will be adding in the Java, Scala, and Python libraries.
But look at those comments from the CEO about where it can go from here, towards "10x simpler" capabilities. Confluent clearly plans on embedding Flink stream processing into its new no-code/low-code Stream Designer. Overlay my criticisms of how hard it is to use Kafka versus how many use cases there are for Kafka across an organization. To stress how important this move is into no-code/low-code tools over both data pipelines and stream processing (and now open engines), Confluent is turning these use cases into "recipes" (ready-to-use templates) in Stream Designer, so that customer teams can easily adopt these uses cases instead of having to develop each of them themselves. This greatly helps "democratize" the use of Kafka, so that non-technical users can start to leverage the value of Data in Motion, to adopt even advanced stream processing use cases easily. I think both of these moves combine nicely to better allow Confluent to bring stream processing to the masses in a cross-cloud turnkey data streaming platform, via whatever open engine the user wants.

Databricks is getting more serious about stream processing as well, with their "Project Lightspeed" announcement in Jul-22 showing how they are planning to majorly revamp their Spark Streaming capabilities. [Spark Streaming works differently than other stream processing engines, as it does mini-batches instead of true real-time streaming (as discussed here).] I expect Spark Streaming to majorly improve from here, with mgmt saying new features should emerge at the start of 2023. I also expect Databricks to combine these Streaming improvements into the no-code tool in their acquisition of 8080 Labs in Oct-21. It is now a race between Confluent, Databricks, and a number of other data streaming startups (like Materialize, Rockset, and Striim) to create a cross-cloud no-code/low-code platform that allows customers to more easily harness the power of real-time data processing.
Add'l Reading
- See past coverage on Kafka, the open-source streaming platform from Confluent.
- The other major product announcement out of their Current conference in Oct-22 was Stream Governance Advanced. This is a new managed service in Confluent Cloud that wraps up all of their Kafka governance capabilities (schema registry, data catalog, data quality, and data lineage) over Kafka.
- Datadog introduced a new Data Stream Monitoring product at Dash [paid], which is a capability Confluent already provided to some degree (health monitoring) but is now improved by embedding it into the visual interface in Stream Designer. This went GA at the end of April.
- Snowflake is also bolstering its streaming pipeline [paid] capabilities lately, which should open up more once it ties in Snowpark over it (which would allow native and connected apps over it). This is a more limited use case for processing data as it moves into Snowflake.
- See Software Stack Investing's take on Confluent's latest Q.
Join Premium to read more!
-muji