
NVIDIA, NVIDIA, NVIDIA – it's on the lips of every tech investor. Since I covered the rise of Generative AI and LLMs in May-23, the stock has gone from ~389 to now over 950, a +145% gain. They report Q125 tonight.
It has nearly been a year since we saw the first signs of a massive inflection in the growth of their Data Center (DC) market. The numbers have been astounding over the past several quarters, entirely driven by their Hopper series that improved their AI-focused GPUs (Tensor Cores) for large language models (LLMs) & Generative AIs by directly embedding a transformer engine. Interest in Generative AI is surging, spreading from hyperscalers and AI leaders (Meta, Tesla) to broader enterprises. NVIDIA sells over half of its GPUs to cloud hyperscalers and new GPU-specialized clouds emerging (some from the ashes of the crypto miners). Major system manufacturers (like SuperMicro & Dell) are building AI servers & workstations for enterprises.
Before I take a look at their recent results and where it's all going, it's time for an NVIDIA tech primer.
I covered NVIDIA extensively through March in the Premium service. Beyond this primer, I walked through their FY24 results, the last year of innovations, and then the Blackwell & software (AIE & NIMs) announcements out of GTC'24. This week I wrote up Q125 expectations and the various factors converging over FY25.
Premium also covered hyperscaler results, GitLab's growth factors, the Rubrik IPO, looked at Microsoft Fabric and their security moves at Ignite, and the last results from CrowdStrike, Snowflake, and Samsara.
Join Premium for insights like this every week across AI & ML, Data & Analytics, Next-Gen Security, DevOps, and the hyperscalers.
My focus in NVIDIA is primarily on their Data Center (DC) market, but it's not the only side of the company doing well. Gaming is finally seeing a rebound from its post-COVID oversupply & the big bust in crypto, while industrial digitization, autonomous robotics, and autonomous auto markets are very early.
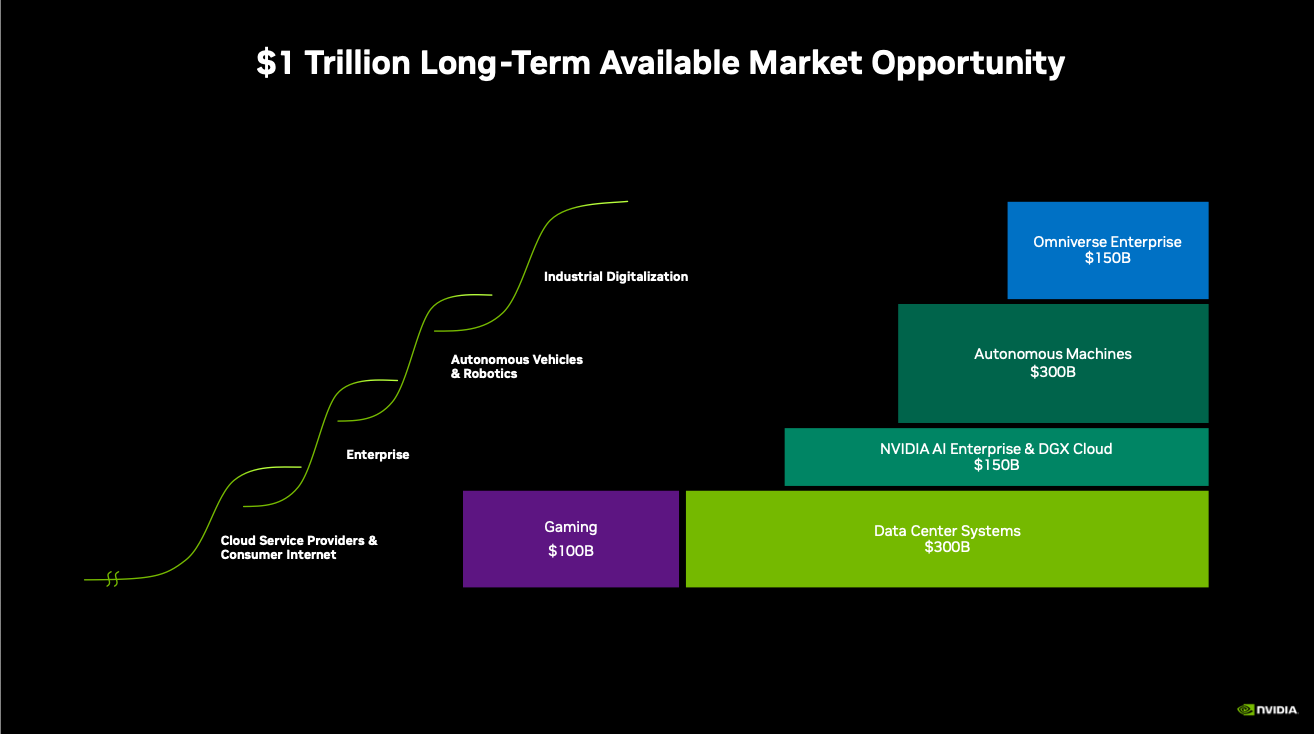
A walk through their products
To better understand the company, let's walk through its chip sets (GPUs, CPUs, DPUs), server & networking lines, and software.
Per Nvidia: Accelerated computing runs primarily on three foundational elements: CPUs that are used for serial processing and running hyperthreaded applications. GPUs that excel at parallel processing and are optimized for accelerating modern workloads. DPUs that are ideal for infrastructure computing tasks; used to offload, accelerate, and isolate data center networking, storage, security, and manageability workloads.
Essentially, GPUs are great for parallelization (visualizations, 3D rendering, scientific computing, simulations, data analytics, and AI/ML/DL), while CPUs are great for serial processing (running general computing needs like operating systems, app stacks, databases, VMs, and containers). These two chips work in tandem, leveraging CUDA to accelerate certain types of workloads by taking full advantage of the GPU's parallelized compute.
On the networking side, DPUs (Data Processing Units) are chips that offload software-defined networking needs away from the CPU. This allows running networking compute needs around traffic routing, storage, data processing, and security features like Zero Trust.
Across all of its chips, NVIDIA maintains high margins from being a fabless chip manufacturer, with TSMC being the primary supplier. NVIDIA then leans heavily on system manufacturer partners to build complete AI systems from their core chips.
GPUs
NVIDIA has long been the leader in GPUs for graphics rendering and accelerated computing (parallelization of workloads), making it the leader in AI/ML and High-Performance Computing (HPC) needs. The HPC industry is for creating giant supercomputers for research-oriented workloads in scientific computing. (As an example, every DOE lab within the US has a supercomputer for HPC scientific computing in energy research and then allocates compute time on it to the various research groups within their org for complex simulations & predictions.) With the rise of Generative AI and LLMs, the interest in AI supercomputers is broadening from governments/science and AI leaders to a much wider base of enterprises seeking to maximize productivity and efficiency or to create new AI-driven products & revenue lines.
NVIDIA GPUs compete with AMD, Intel, the custom AI accelerators being developed by hyperscalers (GCP TPUs, AWS Trainium/Inferentia, Azure Maia), and a number of AI chip startups (Cerebras, Groq, et al).
- Hopper 100 (H100) is the main driver behind their tidal wave of success in FY24, as their LLM-friendly chip with an embedded transformer engine. It was first announced at GTC'22 in Mar-22, and was in full production by GTC'23 in Mar-23. They also introduced dual interconnected H100s with shared memory (H100-NVL).
- Hopper 200 (H200) is their next-gen of the Hopper line, officially announced at SC23 in Nov-23, and expected to fully ramp by Q225. It utilizes HBM3e large-scale memory modules designed for memory-intensive AI operations. Mgmt notes it improves inference by 2x over H100, and by 4x when using their new LLM inference optimized library (TensorRT-LLM).
- Blackwell 100 (B100) is their coming next-generation LLM/AI chip after Hopper. Originally slated for 2025, it was moved up to 2024 in October. [This was launched later at GTC, see my paid Blackwell post.]
- They also introduced several new inference-focused GPU cards & systems at GTC'23, including L4 for video processing, and L40 for 3D rendering & Omniverse uses. L40S soon appeared as an upgrade to L40 that was better geared for AI training & inference – think of it as a lower-end H100-style chip well suited for video & 3D rendering use cases.
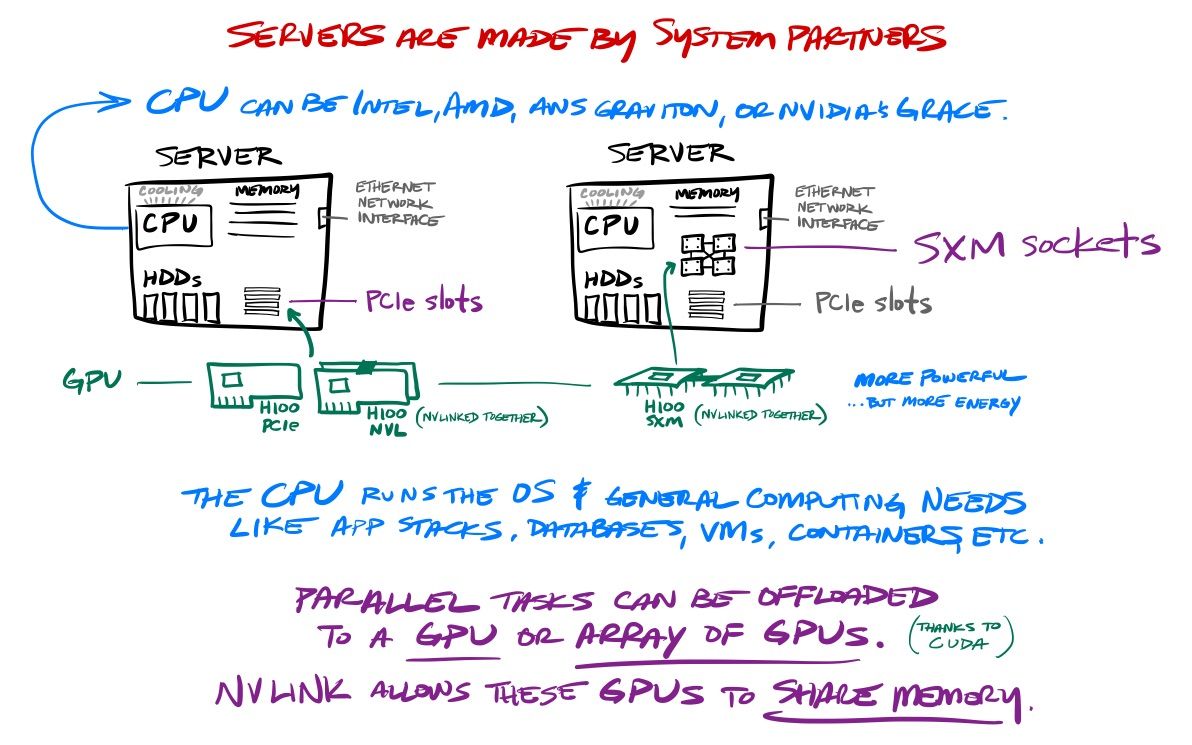
These Tensor Core GPUs come in SXM (socket) and PCIe (slot) varieties, and can then be built by system partners (like Dell, SuperMicro, HPE, Lenovo, and others) into a variety of system form factors from there.
- HGX are rack-ready standalone systems containing 4x or 8x enterprise-grade Tensor Cores, which also leverage BlueField-3 DPUs, NVLink interconnects, and NVIDIA networking.
- DGX is their line of rack-friendly systems for AI supercomputers, which includes modular servers with 8x H100s that can be assembled into an interconnected rack (pods) or row of racks (super pods).
- Other market-specific varieties include RTX for consumer-grade gaming & visualization workstations, EGX for edge computing in industrial digitization, AGX for autonomous automotive, robotics & medical devices, and OGX for 3D rendering & Omniverse.
- A new MGX reference architecture emerged in May-23 for system manufacturers to build standalone GPU+CPU+DPU systems over any modern CPU. This leaves out the interconnect and networking features used within HGX and DGX. This seems to be more geared for non-supercomputer uses, meaning more down market for broader enterprise use.

GPUs are now being clustered into one large AI supercomputer with unified memory, which has led to recent AI advancements in big LLMs and Generative AI models. In order to interconnect GPUs within these clusters:
- NVLink is their GPU interconnect between GPUs within a system, offloading the interconnect from the PCIe slot or SXM socket. It's now in its 4th-gen in the Hopper line, capable of 900GB/s.
- NVSwitch is their GPU interconnect between systems, allowing interconnecting up to 256 GPUs.
- NVLink-C2C is their CPU-to-GPU interconnect within the Grace Hopper (GH200) line, allowing the two chips to co-mingle memory and networking.
Networking
NVIDIA supports two primary networking types. InfiniBand is ideal for internal networking within an AI supercomputer, while the more pervasive Ethernet is more for external networking between systems across local, wide, cloud networks, and the Internet. Think of InfiniBand as a deep and narrow network, and Ethernet as a shallow and broad one.
- InfiniBand is their networking protocol ideal for AI supercomputers, from their Mellonox acquisition in Mar-20. It allows using a high-speed (400GB/s) interconnect as a networking fabric across clusters of nodes, enabling the disparate nodes to act as one big supercomputer and share a pool of unified memory across them. InfiniBand connects the AI systems, while NVLink connects the GPUs within and across those systems.
- Spectrum is their Ethernet line for generalized networking, which released its 4th gen at GTC'22 capable of InifiniBand-like speeds (400GB/s).
- Connect-X is their line of network interface cards (NICs) that support both Ethernet and InfiniBand protocols, now on its 7th gen.
- The next-gen of Spectrum is Spectrum-X Ethernet, announced in May-23, and became available from several system manufacturers in Nov-23. This is touted to give 1.7x better AI performance and power efficiency than regular Ethernet, as well as improved multi-tenancy isolation in cloud environs. It was built by using RoCE (encapsulating InfiniBand on Ethernet) via Spectrum-4 switches and BlueField-3 DPUs.

CPUs/DPUs
NVIDIA has branched into other chips beyond GPUs. They created a line of Data Processing Units (DPUs), which are used to offload software-defined networking workloads off the CPU (such as networking routing, data processing, and security). They are much newer to the CPU market, releasing an Arm-based CPU after first attempting to acquire Arm (announced Sep-20, terminated Feb-22 after a lot of regulatory pushback).
- BlueField-3, the 3rd gen of their DPU, was announced in production at GTC'23. This DPU is infused across their networking product lines, AI systems, and AI supercomputers to offload software-defined networking workloads off of the CPU. This is enabling a new class of network interface card (NIC) that bridges InfiniBand and Ethernet in Connect-X and now Spectrum-X, plus is an integral part of their new Grace Hopper superchip. The 4th gen is likely to appear soon.
- Grace is their customized Arm-based CPU, which competes with Intel and AMD chips, as well as custom Arm-based CPUs being developed by the clouds (AWS Graviton, Azure Cobalt). It was first announced at GTC'22.
- More than being a standalone competitor in the CPU market, Grace was designed around combining the CPU+GPU as an end-to-end AI system. Grace Hopper (GH100) was simultaneously announced as a superchip that combines a Grace CPU with an H100 GPU, with interconnected memory and networking (via NVLink-C2C) and a BlueField-3 DPU for offloading networking workloads off the CPU.
- The next-gen Grace Hopper (GH200) was first announced in May-23, and quickly updated in Aug-23 to use the new HBM3e large-scale memory modules designed for memory-intensive AI operations (also in the later announced H200). This includes the DGX GH200 rack supercomputer with 16 dual GH200 systems (dubbed 32NVL when AWS announced it).
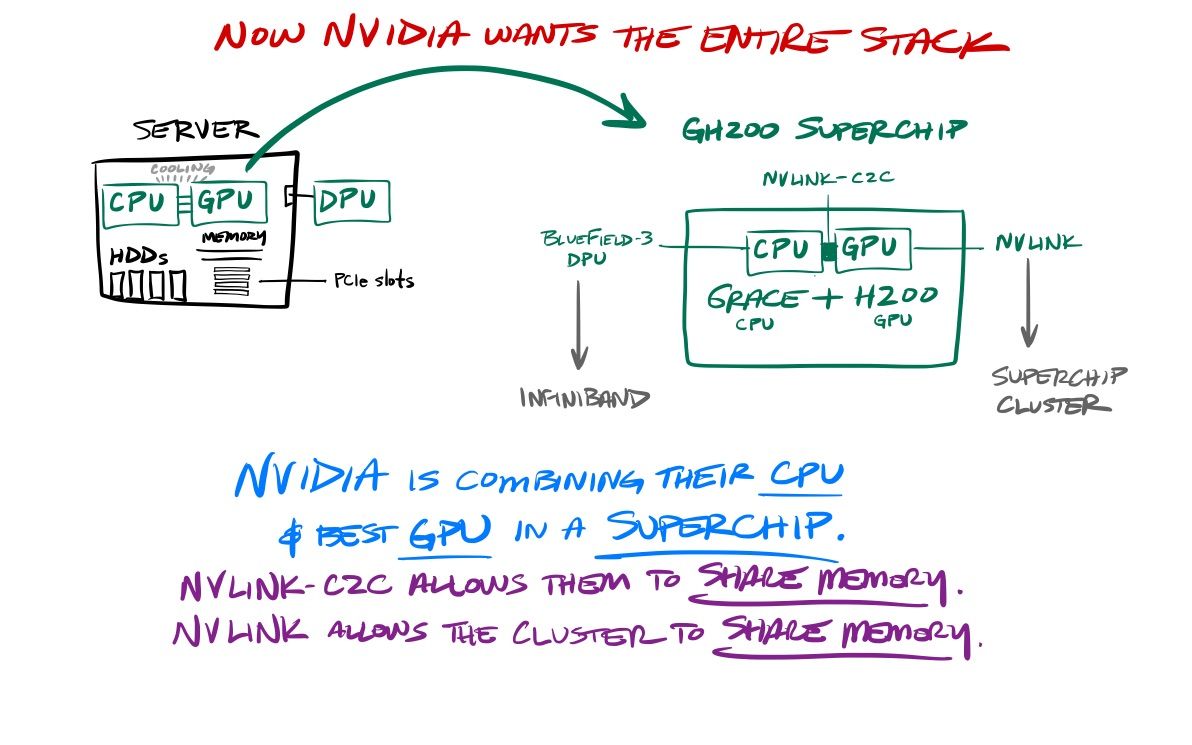
I don't believe NVIDIA created the Arm-based Grace CPU to try to fight against the dominant Intel or AMD in the standalone CPU market. They created this chip to create a combined CPU+GPU+DPU superchip and new class of AI supercomputer – which position NVIDIA to replace existing DC infrastructure with its own complete end-to-end AI system stack. The chips combine into a powerful yet highly cost/energy efficient complete compute system that is ideal for both generalized & AI-driven DC computing needs as well as a number of cross-chip use cases. One use case that mgmt stresses is recommendation systems, which rely heavily on real-time database & vector database lookups (via the CPU) alongside AI needs across LLM inference, vector embeddings, results ranking, etc (via the GPU).
Software
The CUDA stack sits below the GPU, providing a way for developers to turn CPU-driven workloads into GPU-accelerated ones – as a standard set of libraries that work across any NVIDIA GPU. The other softwares sit atop the GPU, providing a standard set of operational tools to utilize the GPU for AI workloads, again across any NVIDIA GPU. All of these softwares standardize access to the underlying GPU (abstracting it away), allowing for a relatively seamless way to change the type of GPU they are using in any environment (hybrid to cloud).
- CUDA (Compute Unified Device Architecture) is their general set of accelerated computing libraries, allowing developers to parallelize compute needs on any NVIDIA GPU. Essentially, this is a software layer that bridges from CPU to GPU by providing a foundation for accelerating a wide range of workloads across a number of scientific and data science needs.
- CUDA-X is their subset of CUDA libraries and tools specifically for AI & HPC workloads. One product line within it is RAPIDS, their suite of open-source libraries to accelerate common data processing & data science libraries such as Pandas and Spark.
- TensorRT is their optimized compiler for AI inference across any Tensor Core GPU. The new TensorRT-LLM library was released to open-source in Oct-23 as an LLM-optimized version, which improved inference on the H100 by 2x.
- Triton is their open-source inference-serving platform to standardize inference across any Tensor Core GPU, any modern CPU, as well as AWS Inferencia.
Don't confuse NVIDIA's Triton with the (exactly named and very adjacently focused) open-source Triton initiative from OpenAI, which hopes to standardize deep learning model development over NVIDIA GPUs and modern CPUs with a higher-level abstraction layer (in Python) over CUDA. They hope to eventually add in support for AMD GPUs and likely other specialized AI accelerators.
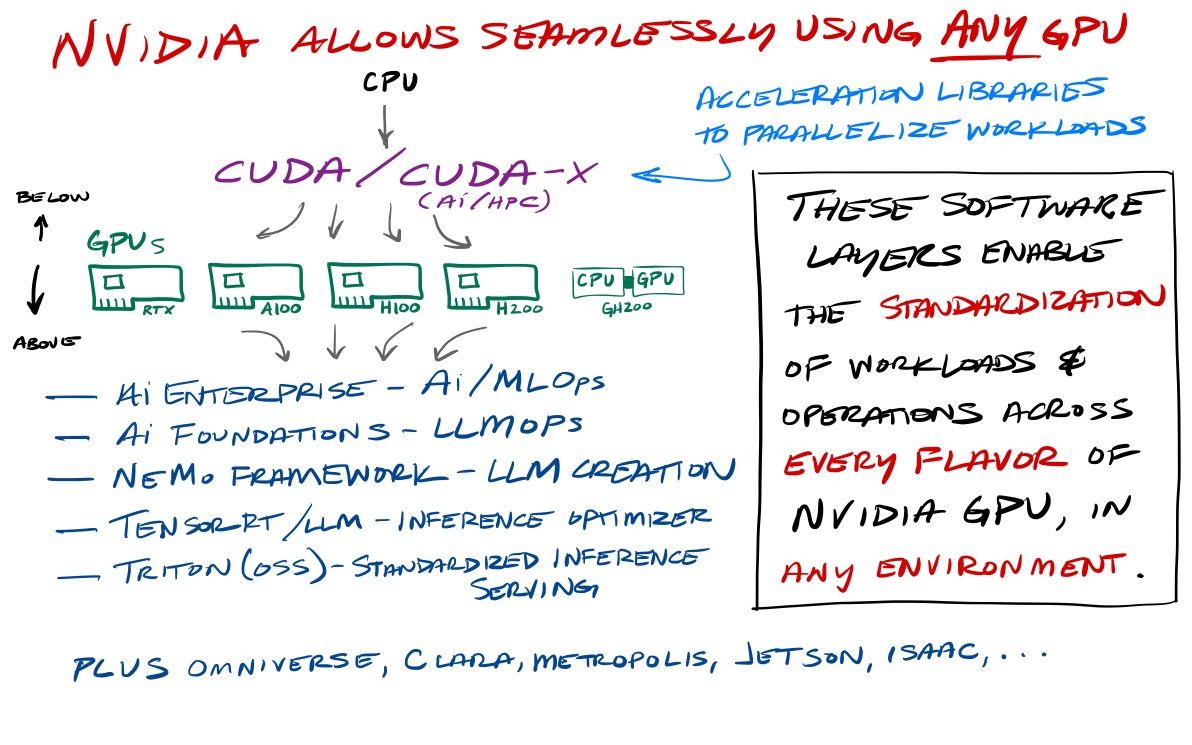
NVIDIA also has a number of cloud-based software platforms.
- AI Enterprise is their cloud-based suite of AI training and inference tools, that help customers standardize MLOps & LLMOps across GPU stacks. This gives customers flexibility on where to deploy AI solutions, across on-prem HGX/DGX systems to DGX Cloud instances.
- Base Camp is their cluster management software for NVIDIA AI supercomputers, across any DGX on-prem or cloud environ.
- AI Foundation is their LLMOps suite for customizing and using open-source LLM engines, including Meta's Llama 3, Stable Diffision, and Mistral, as well as NVIDIA's own Nemotron-3 and Google's new Gemma models. This also includes NeMo & Picasso, open-source LLMOps frameworks for the creation of LLM & Generative AI (text-to-image) models.
- DGX Cloud is their new cross-platform compute service first announced at GTC'23 in Mar-23. This gives NVIDIA the ability to rent entire supercomputer clusters/racks back from the major hyperscalers in order to rent them to NVIDIA customers on that cloud. Oracle, GCP, and Azure were all early supporters, and AWS recently announced it at re:Invent in Dec-23.
- AI Foundry is a new cloud-based service containing all of the above cloud services (including DGX Cloud), which debuted on Azure at Ignite in Nov-23.
Other industry-specific software platforms include Omniverse for 3D apps, Clara for healthcare, Jetson for robotic sensors, Issac for autonomous robots, Metropolis for IoT & smart cities, and DRIVE for autonomous vehicles & infotainment systems. These can include hardware components as well as dedicated GPU system form factors (see EGX, AGX, OGX above).
Add'l Reading
- See my past Layers of AI post for the layers and ramifications of Generative AI and LLMs, as well as the past Modern Data Stack on data ecosystem of tools emerging around data for BI and AI needs.
- As mentioned before, I covered NVIDIA extensively through March in the Premium service. Beyond this primer, I walked through their FY24 results, the last year of innovations, and the Blackwell & software (AIE & NIMs) announcements out of GTC'24. This week I wrote up Q125 expectations and the various factors converging over FY25.
- I looked at Google's TPU announcements at GCP Next last September [paid], and touched on Microsoft's AI announcements at Ignite [paid] in November.
- I highly recommend the chip-focused newsletters Semi Analysis (dense tech & supply chain coverage) and Fabricated Knowledge if you want to dive deeper into the chip market.
-muji