
Before we get into the busy customer conference & product announcement season for the rest of the year, I wanted to take a step back to look at the broader ecosystem that is being built in Data & Analytics, to explain where these data stacks have come, and where they are going. [That's right, it's time for some drawings!]
Today's cloud-driven modern enterprises need a modern data stack. The concept of a data warehouse's purpose has been steadily evolving over the past few years, leaving behind the traditional view of solely being a reactionary analytical database for generating reports and dashboards to now become the proactive driver of an enterprise's operations. Data warehouses have gone from being key for business intelligence (BI) to becoming the critical center of business operational data. The Modern Data Stack is enabling new forms of app services across its ecosystem, such as Customer Data Platforms (CDPs), reverse ETL, and headless BI. The major data warehouses are enabling and fostering partnerships across this ecosystem, which continue their explosive growth by creating incredibly sticky platforms for both partners and customers to leverage in new ways. And from here, Snowflake seems to be carving some unique paths to increase that stickiness.
Let's walk through the various capabilities within the Modern Data Stack (as well as new ones emerging), with examples of platforms and tools available across each. Buckle up – it's a long journey. Investors in Snowflake will recognize many names from its industry clouds (explored before), partner programs (detailed recently), and venture investments (see wiki) [all paid links], as will investors in the countless other companies around analytical databases, data pipelines, BI tools, product & customer analytics, and ML/AI tools. There are plenty of exciting private and startup companies mentioned here that may eventually IPO or be acquired, and this ecosystem is a high area of focus for VCs like Redpoint and Altimeter. This post can serve as a guide as you come across these features, companies, and tools in your own research. [It is especially of interest if you are building a modern data stack in your own organization!]
This post covers:
- a look at the needs solved by cloud-native data warehouse and data lakes, which are enhanced and simplified when combined into the data lakehouse
- how the Modern Data Stack's growing ecosystem has led it to become the center of operations
- not only is it the operational center, but the evolving ecosystem has enabled organizations to make data actionable and monetizable – shifting the Modern Data Stack from reactive to proactive
- a walk through the various part of the ecosystem, including ingest, engine, enterprise tooling, BI analytics, and ML/AI analytics, as well as newer and evolving capabilities like CDP, reverse ETL, headless BI, and headless MLOps
- explanations of all these capabilities within the ecosystem, and examples of SaaS platforms, cloud provider services, and open-source tools in each (including callouts for Snowflake investments and partners, including those taking advantage of Snowpark and Native Apps)
- new abstraction layers and deployment models that partner platforms can leverage going forward, and where Snowflake is unique
[Beyond Snowflake, Databricks, and the major cloud vendors, it also includes some brief mentions of public companies in my sphere, like Datadog, Amplitude, Confluent, Alteryx, Monday.com, and Twilio/Segment.]
Legacy to Modern
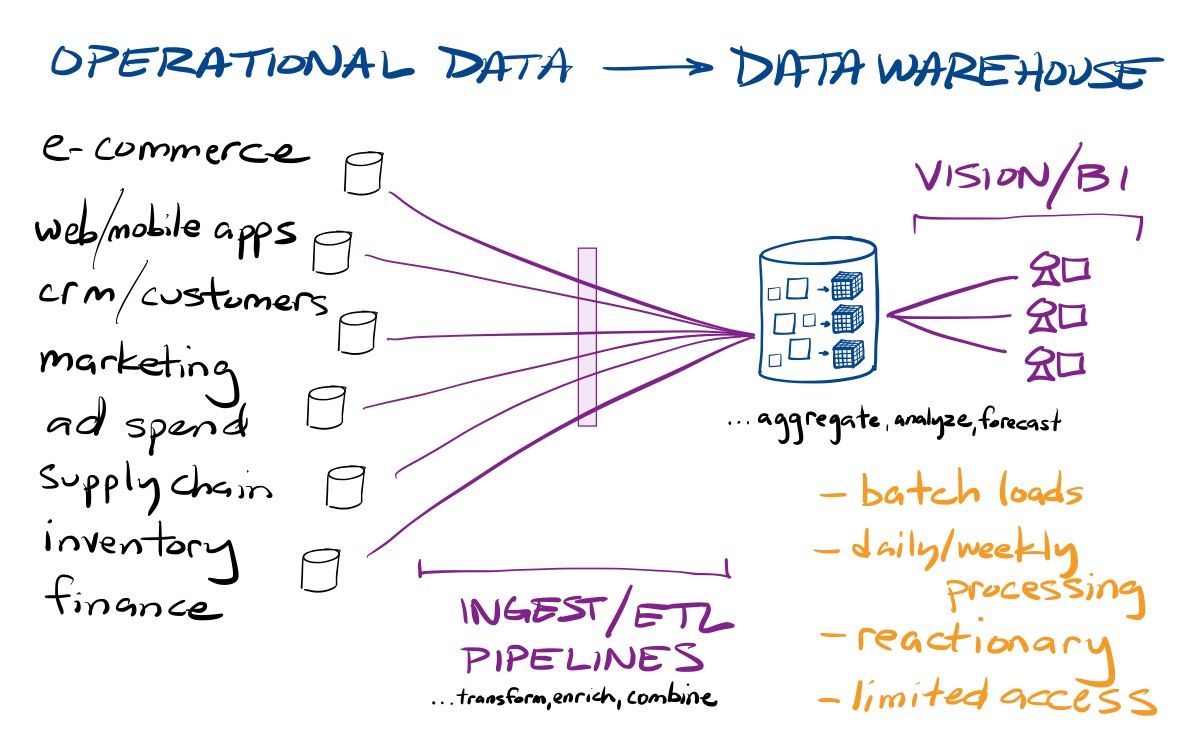
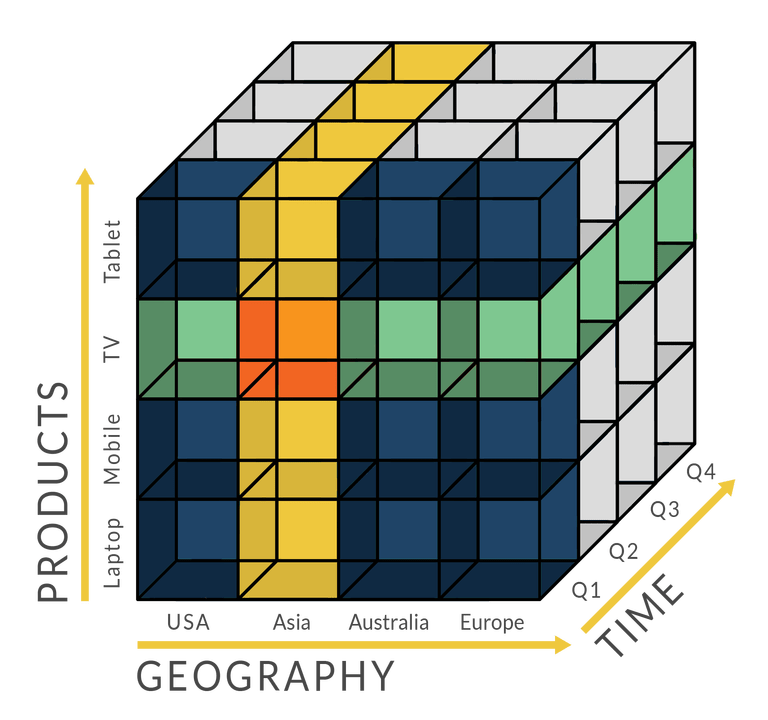
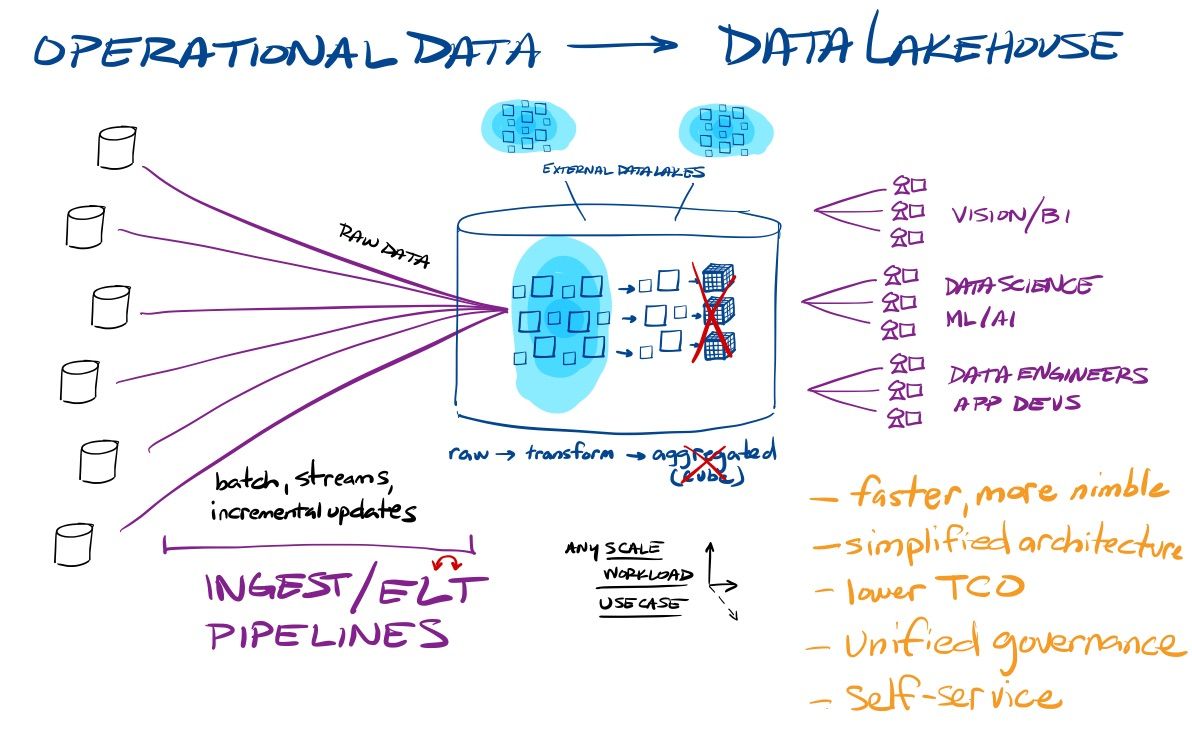
With on-premise data warehouses (OLAP databases), data engineers would pull data from a variety of operational sources, manipulate and enrich that data, and load it into a data warehouse – what is collectively known as the Extract, Transform, and Load (ETL) process. Processing raw data took several data engineering steps, including transformation/enrichment in the data pipeline and then modeling the imported data around business objectives & ways of looking at their business. Due to the compute limits of on-premise hardware, data analysts then had to pre-aggregate that data around those pre-defined business metrics and dimensions (by time, product, salesperson, region), into what are known as OLAP Cubes. Business analysts would then import the final aggregated data into BI tools in order to analyze and visualize the state of business operations in reports and dashboards.
OLAP Cubes are pre-aggregated operational metrics around that enterprise's internal dimensions into time frames (by quarter, month, day). They typically took days/weeks to assemble, though could be incrementally updated from there.
Hadoop eventually arose as a way to handle data analysis at scale over a pool of "big data", by using an array of commoditized hardware as one giant "supercomputer" to process huge quantities of data in chunks and then aggregate the totals. But while Hadoop might have changed query times from days/weeks to hours/days, it was not enough. The complexities of running Hadoop (especially in installing and managing a vast quantity of fickle hardware and software) ultimately turned into success for the next wave of analytical data solutions. Next-gen cloud-native data warehouses (for BI at scale) and data lakes (for ML/AI at scale) started from Hadoop's key architecture decision to separate storage from compute, but leveraged the unlimited scale of the cloud to create abstraction layers that greatly simplified the complexities of managing and analyzing data at scale. [If you want more on Hadoop and the history of data warehousing, see my original Snowflake dive from its IPO.]
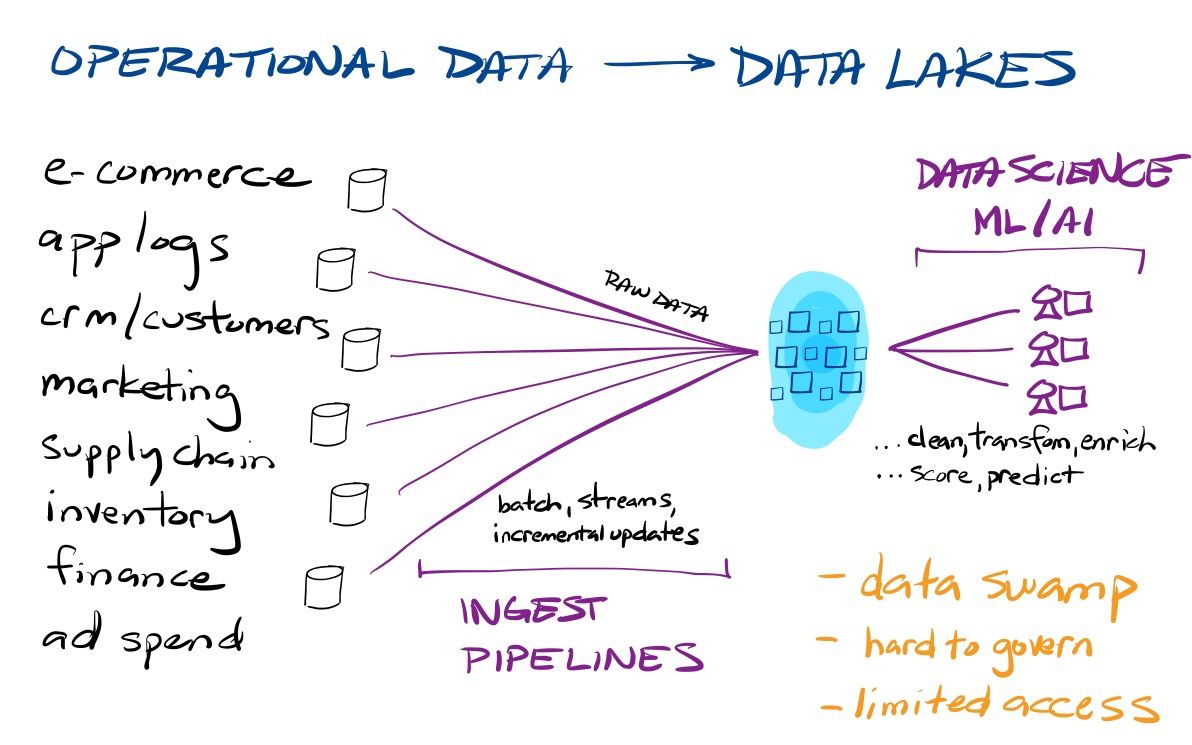
Beyond being a growing pool of raw data for data science and analytics, data lakes can also be used for data archival (warm data) and backup (cold data) from data warehouses. You can keep the "hot" operational data (say, the past 2 years) active in your data warehouse, but can offload more infrequently accessed older data to cheaper data lakes, to access as needed. But beyond that, orgs can now store vast amounts of historical app stack & security logs in a data lake, to use as an on-demand observability or security data lake.
Cloud data warehouses and data lakes are now starting to combine, to allow an enterprise to leverage the same analytical engine to harness raw data (needed in ML/AI) and transform it into business-ready data (needed in BI). One benefit is in how data engineers are able to simplify their data ingest process. By flipping the transform (T) and load (L) stages, orgs turned ETL into ELT, by loading raw data into the data lakehouse then using automated transformation capabilities to morph the data into business-ready formats for BI analysts. This greatly simplifies the data pipelines needed to be created and managed by data engineers, and allowed them to directly ingest data streams from tools like Kafka. The simplification of the stack continued from there. The scale of the cloud meant that data analysts no longer needed to "front-load" their work by pre-aggregating the data (often taking days or weeks), instead leveraging the unlimited compute and storage of the cloud to enable more nimble BI workflows to provide answers in minutes.
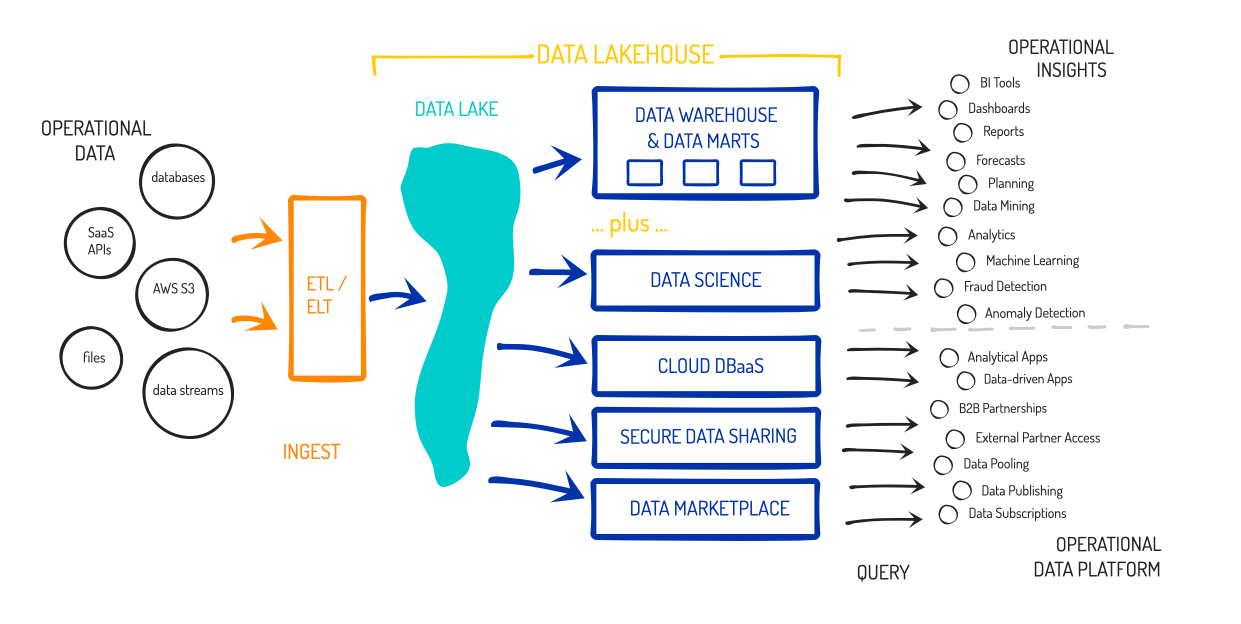
The complicated processes of the past have evolved and combined in the data lakehouse, which allows an enterprise to provide self-service analytics to both business analysts and data scientists from the same data stack. This new paradigm and ecosystem around it has been dubbed the "Modern Data Stack", which positions the data lakehouse at the center of an enterprise's operations. Data warehouses have always needed ingest, orchestration, transformation, and streaming tools (to the left of the data warehouse), as well as a wide range of BI analytical tools (to the right of the data warehouse). However, data no longer needs to sit siloed between these tools or be pushed from platform to platform, as it can be leveraged in place by analytical platforms that sit over the data store. And regardless of whether data is in the central lakehouse or in external data lakes, the Modern Data Stack is becoming the center of analytical compute over it. New tools and partner platforms have emerged for every enterprise need around operational analytics and data management.
With this combination, the modern data stack has now become the nervous system of the enterprise instead of separate systems for the eyes and ears (BI) and brain (ML/AI). And it now moves beyond that, with data sharing, data marketplace, programmability, and connected/native apps emerging as ways to keep this growing pool of operational data as the center of gravity for an enterprise's operations. New toolsets are emerging around this centralized pool of data – we now have product analytics, reverse ETL, and headless BI tools that help make data actionable and monetizable, stream processing tools to make it more real-time, and DataOps tools to help an enterprise maintain control over its growing pool of data in order to monitor data flows & quality, and maintain privacy and governance over it all.
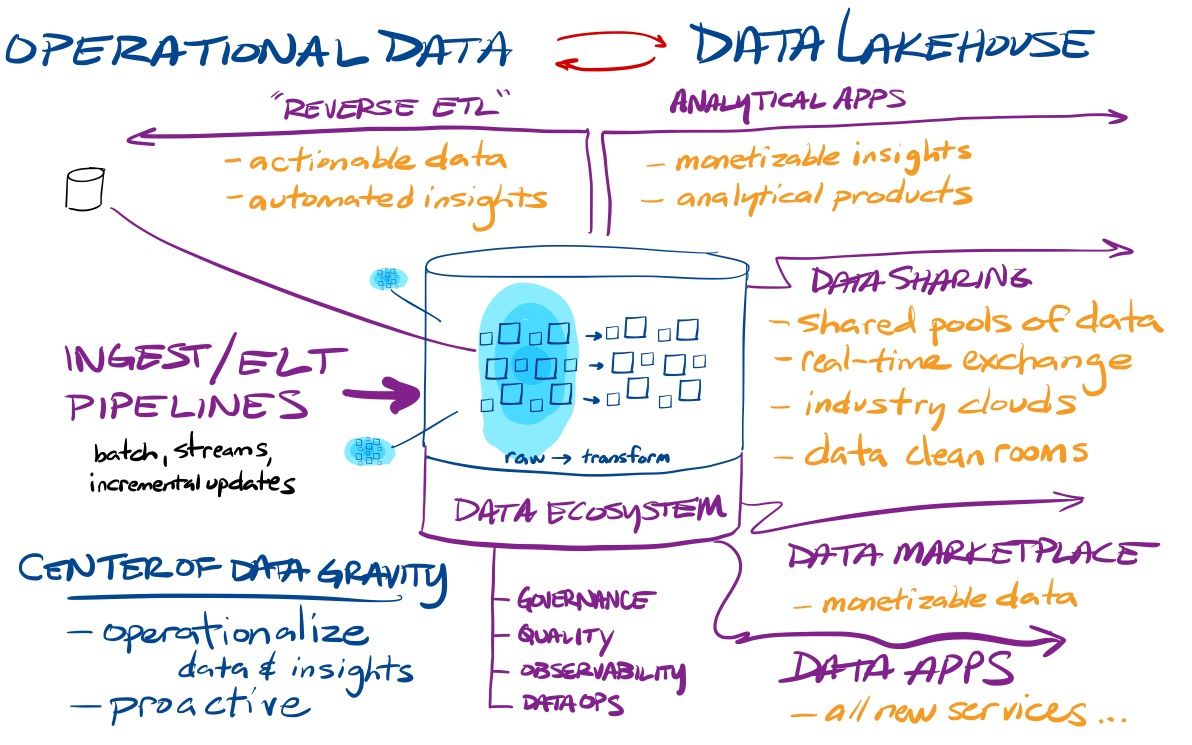
These features mean the Modern Data Stack is no longer just a reactionary toolset for viewing and forecasting business operations – it has morphed into a proactive tool that sits at the center of the enterprise. The enterprise nervous system is becoming the beating heart of the enterprise, as all operational data is automated to flow into it, and derived insights are being turned into action. Product and customer analytical systems are driving insights back into software products and sales & marketing tools. Data, analytics, and insights are being monetized. And all new possibilities are emerging in connected/native app models (enhanced further by data sharing and marketplace).
Let's walk through the various areas within the Modern Data Stack and where a few of these directions continue to advance forward. I provide examples of SaaS services, cloud provider products (from AWS, Azure, and GCP), and open-source tools for DIY solutions. The list of example companies in each space is by no means exhaustive. [Feel free to let me know about other companies doing interesting things in these areas!]
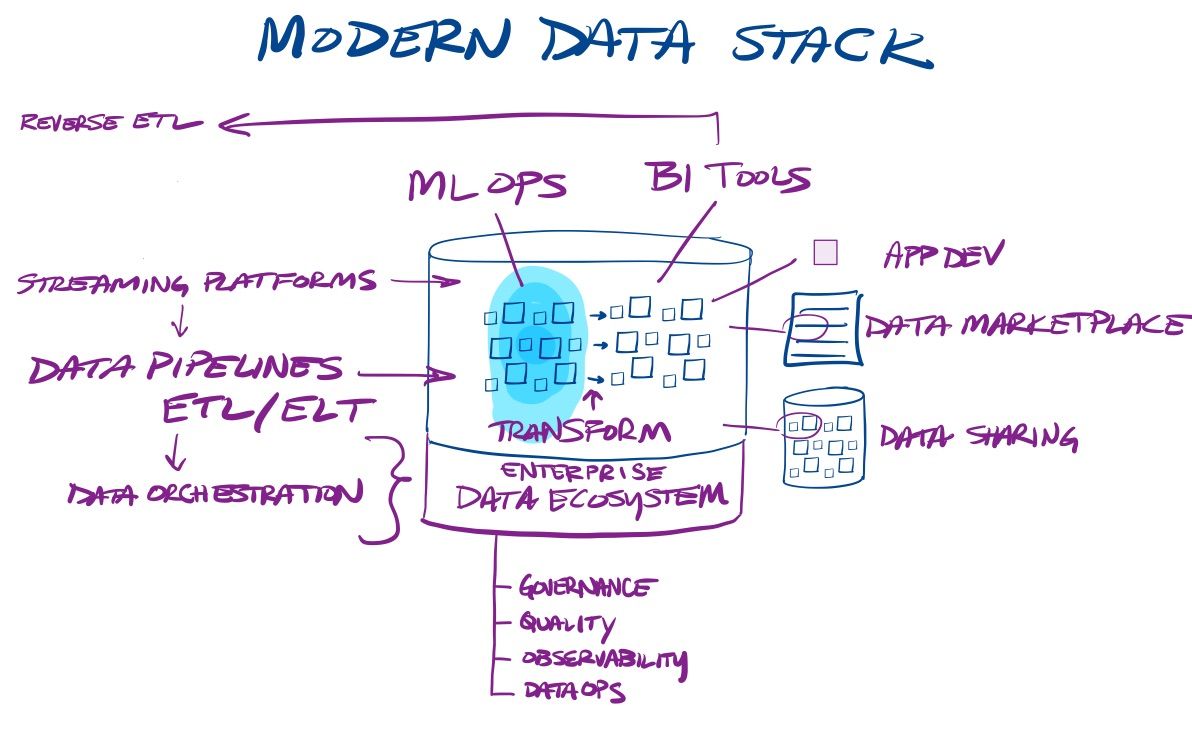
Ingest Ecosystem
These tools are generally considered data engineering tools, in order to pull data into the data lakehouse.
Ingest Pipelines (ETL)
These are services to ingest data from operational databases and SaaS services into a data warehouse or lake, performing the various stages within the ETL process, or what is known as "data wrangling". These also have capabilities to automate and monitor data flows into the data warehouse, and may have incremental update capabilities from production databases (known as CDC, for Change Data Capture). Essentially, these are all automated services to create data pipelines into the data stack, typically via low-/no-code UIs. [Several do data pipelines out of the data stack as well, see Reverse ETL below.]
- SaaS services: Fivetran, Matillion, Hevo Data, Gathr, Talend/Stitch, Alteryx/Trifacta, Striim, Dataddo, Estuary, Arcion [CDC]
- cloud services: AWS Data Pipeline, AWS Glue (code) & Glue DataBrew (no-code), Azure Data Factory, GCP Data Fusion, GCP Dataform (acquired)
- open-source: Airbyte+, StreamSets+, Apache Nifi, Apache Spark+ (Databricks), Debezium [CDC]
Snowflake has invested in Matillion, and partners with Fivetran, Hevo, Airbyte, Talend, Alteryx, Striim, StreamSets, and Arcion. Matillion, Talend, Trifacta, and Streamsets are all embedding deeper with Snowpark – with Matillion even building a native app.
Data Orchestration
Above and beyond ingest pipelines are data orchestration tools, which typically provide a more enterprise-focused platform for tracking & automating over all of an enterprise's data flows between tools and SaaS services. Some provide a programming environment to harness data flows via code, while others are no-code. Some of these also have wider ambitions beyond the Modern Data Stack, to be a fuller Integration Platform as a Service (iPaaS) to interconnect data between SaaS platforms (an area that Asana and Monday.com [paid] compete in, as well as Workato and Zapier).
Ingest pipelines (the data plumbing) and orchestration tools (management) are all blending together, and are adding in more enterprise-focused features like data governance, data cataloging & lineage, and data quality, as well as ML/AI-focused capabilities. [More on all that in a bit.]
- SaaS services: Talend, Boomi, Informatica, TIBCO, Rivery, MozartData, DataKitchen, Keboola, Tengu, Precisely, Nexla, Qlik Cloud, DataOps.live
- open-source: Apache Airflow+ (Astronomer), Prefect+, Dagster+, Pachyderm+, Luigi
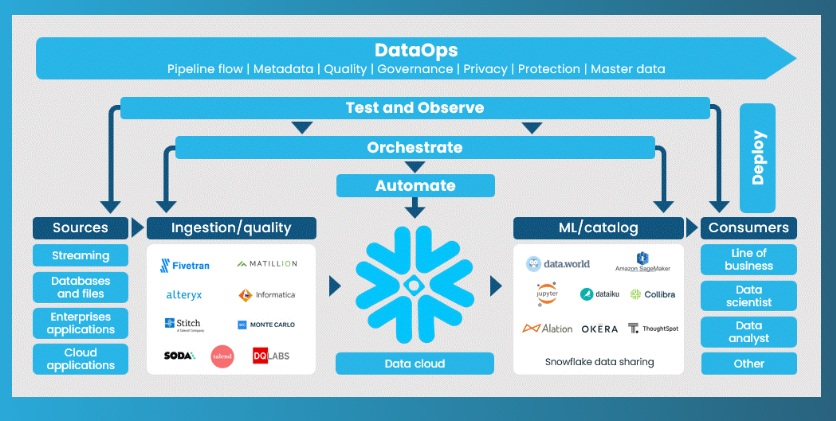
Some of these orchestration tools are starting to rebrand as DataOps tools, taking cues from DevOps to allow for more repeatable, programmable workflows around data (allowing code commit & collaboration and data workflow pipelines via CI/CD).
Snowflake has invested in DataOps.live, and partners with Talend, Boomi, Informatica, TIBCO, Rivery, MozartData, DataKitchen, Kaboola, Precisely, Nexla, Qlik, and Prefect. MozartData and DataOps.live are both built atop Snowflake, and MozartData leverages data sharing with its customers. Talend, Informatica, TIBCO, Precisely, Rivery, and MozartData are all embedding deeper with Snowpark.
Stream Processing
Heavily related to ingest tools are streaming platforms that are used to carry data between services and environments, and to (optionally) perform real-time processing while in transit. I feel that this category is a more nebulous part of the stack (and many leave it out) – the pipeline capabilities can be used to directly ingest data into the centralized data lakehouse (especially with raw data transformation being done in the lakehouse in ELT), however, any real-time streaming analytics done on those pipelines is being done outside of the modern data stack, not over it.
- stream processing: Confluent (Kafka), Ververica, StreamNative (Pulsar), Datastax Astra (Pulsar), Pandio, Databricks (Spark)
- cloud services: AWS Kinesis Data Firehose & Analytics, Azure Stream Analytics, GCP Dataflow, GCP Datastream (acquired Alooma)
- open-source: Apache Kafka+, Apache Pulsar+, Apache Spark Streaming+, Apache Flink, Apache Heron, Apache Samza, Apache Beam
There are also serverless platforms for data engineering that are emerging to blend data orchestration and stream processing into data lakehouses, including Meroxa and Decodable.
The challenge with standalone pipeline tools running stream processing "within the data plumbing" is that it cannot then blend those real-time analytics (within the data stream) with historical data (within the data warehouse or data lake). One generally needs a separate analytical database to bridge that gap, such as Druid or ClickHouse [more on those below]. However, hyperscaler solutions have allowed their stream processing products to blend in data from their native data warehouse and data lakes, as does Databricks (Delta Lake can be a source within Spark Streaming). Snowflake lags here, but has been taking steps lately to blend in stream processing features as data is ingested into the warehouse. [See the materialized table discussion from my paid Summit take.]
Core Data Engine
Analytical Engines
A number of analytical database engines exist for data warehouse (BI) and data lake (ML/AI) use cases. There are a number of cloud and next-gen solutions here for data warehouses and data lakes, and the cloud providers all provide ways to query across them (using the data warehouse as a query engine over data lakes).
- next-gen cloud-native lakehouses: Snowflake, Databricks (Delta Lake & SQL), Dremio, Firebolt, Onehouse (Hudi), Vertica Eon
- legacy warehouses adapted to cloud: Teradata, IBM, Oracle, SAP
- cloud ware/lakehouses: AWS Redshift, Azure Synapse, GCP BigQuery, GCP BigLake
- ... ML features via SQL: AWS Redshift ML, GCP BigQuery ML
- ... storage for data lakes: AWS S3, Azure Data Lake Storage (ADLS) Gen2, GCP Storage
- ... query engines for data lakes: AWS Athena, AWS Redshift Spectrum, Azure Serverless SQL Pool, GCP BigQuery Omni
- open-source data lake formats: Apache Iceberg, Apache Hudi+, Databricks Delta Lake+
- ... federated SQL engines (across all data sources): PrestoDB, Trino+ (Starburst), Apache Drill
- ... analytical columnar stores: ClickHouse+, Apache Druid+ (Imply), Apache Pinot+ (StarTree)
There are a number of analytical columnar stores to allow for real-time OLAP by blending streaming and historical data, including ClickHouse and Druid, as well as emerging serverless real-time database platforms like Materialize and Rockset. I consider these all as competition to data lakehouses.
Federated query engines are another form of competition. Open-source frameworks like PrestoDB and Trino are an abstraction layer that serves as an umbrella to access & query over all of an enterprise's operational databases, allowing for unique features like cross-database joins (something that could normally not happen until all the data is later combined in the data warehouse). These services can take the place of Hadoop and data lakes, and even data warehouses. While certainly convenient, I have not yet been that impressed with this technology, given the inherent networking latency between data silos across different environments (on-prem, hybrid, managed cloud & SaaS services, etc) and how cross-database queries are ultimately affected by the least common denominator in the mix (dragged down by the slowest database being called).
My focus is primarily on the data lakehouses that sit between BI and ML/AI needs, which are emerging as the center of data gravity in the Modern Data Stack. In particular, the ones that are best leveraging the cloud (separated storage and compute) and provide turnkey serverless capabilities (not managed infrastructure). In particular, Snowflake, Databricks, and GCP BigQuery are the ones to watch. Snowflake differentiated early with data sharing and marketplace, but the others are beginning to catch up. [This will be covered in much greater depth in a follow-up piece or two.]
Native Transform
The ingest/orchestration platforms above can all do data transformation as a stage within data pipelines for ingest (the T in ETL). However, running the transformation within the data lakehouse (turning ETL into ELT) allows for simpler, faster, and more flexible data pipelines & workflows. After loading raw data into the data lakehouse, ELT tools can perform any needed transformation to create business-ready analytical datasets for non-technical business users to use in BI tools – which is then leveraging the compute/storage of the data warehouse for these actions, instead of an outside pipeline service.
The popular tool dbt (for Data Build Tool) has greatly advanced the notion of automated data transformation inside the database. Of course, you could always use SQL for native transformations – but that is cumbersome and difficult to manage, collaborate upon, and deploy. dbt allows for doing transformations in a centralized, managed, collaborative, automated, and consistent way, with a code-driven workflow (via programmable SQL) to run transformations from incoming raw data as needed, including handling incremental updates.
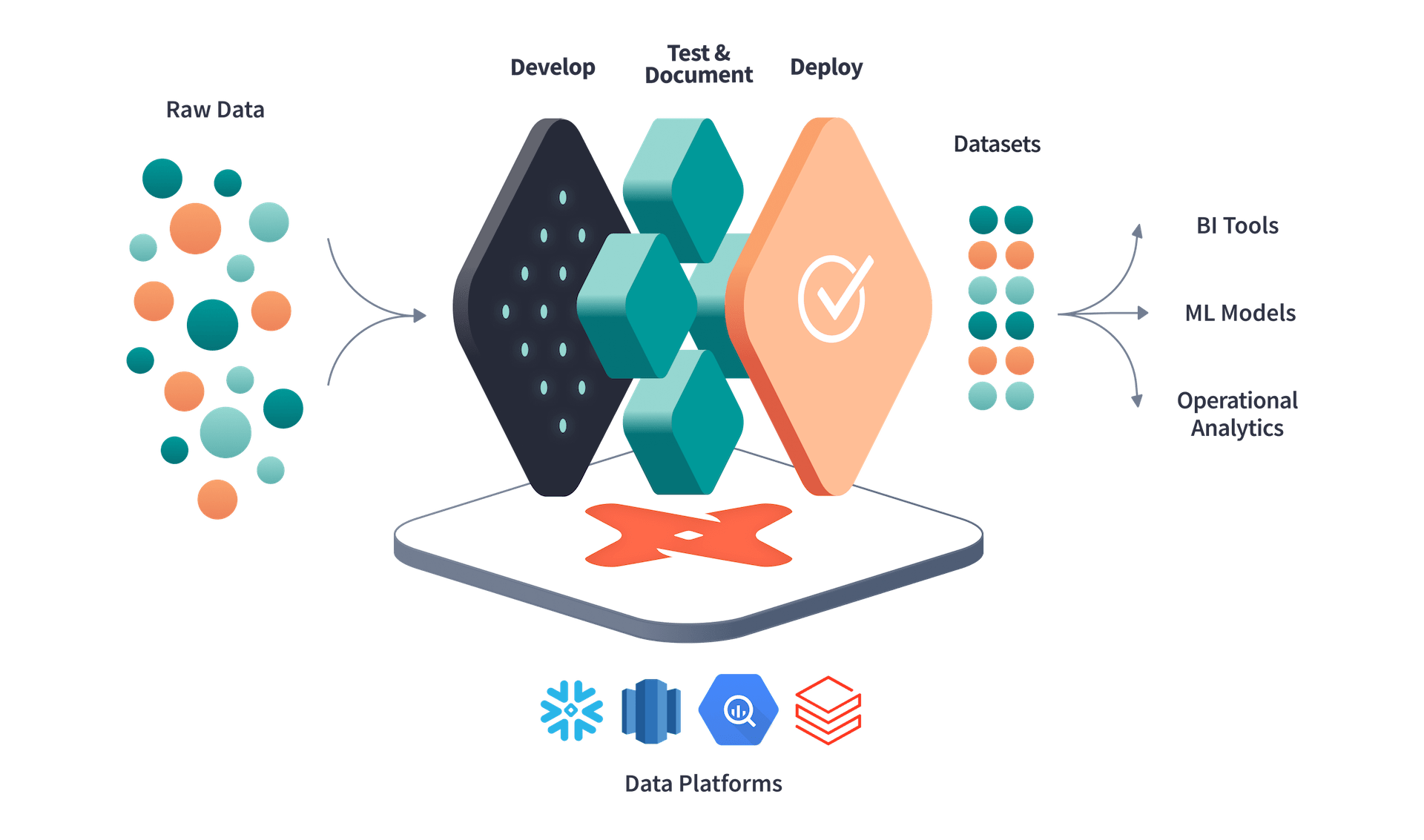
dbt's goal is to help combine data engineering and data analyst roles into what it calls analytics engineers, who then hand off the final analytical datasets directly to business users for self-service analytics. Akin to an app development pipeline in DevOps, dbt allows creating repeatable code-driven data workflows for DataOps (via CI/CD pipelines across development, testing, and production stages) to transform raw data into analytics-ready datasets.
"Analytics engineers deliver well-defined, transformed, tested, documented, and code-reviewed data sets. Because of the high quality of this data and the associated documentation, business users are able to use BI tools to do their own analysis while getting reliable, consistent answers."
- SaaS services: Airbyte*, Matillion*, Fivetran*, Datameer
- open-source: dbt+ (dbt Labs), fal.ai (Features & Labels)
dbt is being leveraged by several other data ingest tools (with an asterisk) to allow these ELT platforms to do ELT. But it is also unlocking new data transformation use cases in some of the next-gen BI mentioned below, like CDP and reverse ETL. You can also use the Features & Labels open-source library to wrap Python around dbt for ML-driven workloads, however, dbt just announced Python support after Snowpark and Spark support opened up the use of the language in data lakehouses. Expect dbt to unlock even more ML/AI use cases from here.
dbt Labs had an investment round earlier this year that was joined by Snowflake, Databricks, Google, and Salesforce. dbt is also embedding deeper with Snowpark.
Beyond ELT tools, another class of transformation tools are data cleaning and enrichment services that occur after in-place after ingest. Snowflake partner Tamr provides a solution that uses ML-driven processes to clean and deduplicate data, and link customer/patient/supplier records across different data sources.
Enterprise Data Ecosystem
There are a number of tools that can run over the data lakehouses and data lakes to assure enterprise-wide data governance and quality. Enterprise-friendly data orchestration tools are moving into these types of capabilities as well (as these tools move into orchestration), so the lines between these areas are blurring.
Data Governance
Governance tools include enterprise platforms for tracking across data sources (data catalogs) and where the data came from (data lineage), and maintaining enterprise-wide privacy and governance policies over it all. These tend to partner with and support all the major data warehouses and data ingest tools (or do orchestration themselves), and help support securing the data for self-service analytics across a large organization. Other specialized use cases include data auditing, risk mgmt, and DLP (data loss prevention).
- SaaS services: Alation, Collibra, Immuta, Privacera, Atlan, Zaloni, Okera, Cyral, Manta, AtScale, AuditBoard, Cinchy, Data.world, ALTR, Semarchy, Protegrity, Ocopai, Concentric.ai
- cloud services: GCP Dataplex, Azure Purview
- open-source: Amundsen, DataHub, Marquez (Datakin), Unity Catalog (Databricks)
Snowflake has invested in Alation, Collibra, and Immuta, and has partnered with Privacera, Atlan, Data.world, Zaloni, Okera, Cryal, AtScale, ALTR, Protegrity, and Concentric.ai. Immuta, Okera, and AtScale are all embedding deeper with Snowpark, while Protegrity and ALTR are building native apps.
Data Observability & Quality
There are specialized enterprise tools to monitor and test data flows to assure their reliability and quality. Data observability provides monitoring over pipelines to assure data is flowing as expected. Data quality, on the other hand, is a deeper service that samples & profiles the data within that pipeline, to assure it is within expected bounds and that the data is reliable.
- SaaS services: Monte Carlo, Bigeye, Astronomer/Datakin, Anomalo, Datafold, DQLabs, Acceldata, Sifflet
- open-source: Great Expectations+, Open Lineage (Datakin), Soda+
Snowflake is partners with Monte Carlo, Bigeye, Anomalo, DQLabs, AccelData, and Soda. Monte Carlo is embedding deeper with Snowpark.
BI Analytics Ecosystem
Now let's explore areas where data and insights can be made actionable. Beyond the traditional BI tools, there are a number of specialized platforms emerging here, like CDP, reverse ETL, and headless BI.
BI Exploration/Dashboarding Tools
BI analytics are performed over modeled data that is structured through the lens of business objectives (dimensions, metrics, time horizons). The outputs are then used in BI tools for ad-hoc data exploration, reporting, dashboarding, metric monitoring, and forecasting. These are typically SQL-driven collaborative environments, plus no-code tools for non-technical business users. Many of these are well-known and long-established (especially Tableau, Power BI, and Looker), plus there are several open-source solutions for DIY analytics, and a number of startups that are focused on specific areas & verticals and adding more ML/AI-driven capabilities over BI analytics.
- SaaS services: Salesforce/Tableau, Sisense, Sigma, LiveRamp, Preset, Mode, Anodot, Locale.ai, Sisu, Qlik Sense, Robling, Tellius
- cloud services: Microsoft Power BI, GCP/Looker, GCP Data Studio, AWS Quicksight, Azure Analysis Services
- open-source: Apache Superset, Databricks/Redash, Metabase+, Lightdash+, Querybook
Snowflake has invested in Sigma and Robling, and partners with Tableau, Sisense, LiveRamp, Mode, Sisu, Qlik, Anodot, Tellius, and Metabase. Sisense, Mode, and Tellius are all embedding deeper with Snowpark, while LiveRamp and Robling are building native apps – with LiveRamp demoing their native ad-tech data apps at a keynote in Summit.
Product Analytics
Tools have emerged that embed within your app stack to measure user actions across your software platform in real-time, to give customer insights way beyond what traditional web analytics (like Google Analytics) provide. They are highly honed for performing behavioral analytics over customer-driven software platforms, and are deeply embedded – requiring instrumenting your application code with agents to track events of interest. Think of Product Analytics as "software that makes your software better" (Pendo's tagline). Ultimately these tools are geared toward driving app engagement and increasing conversions, and may include advanced features like user experience monitoring, session replay, error monitoring, A/B testing, and feature flags. These are features that closely resemble what Observability & APM platforms like Datadog provide, but are more focused on bridging the gap between DevOps (APM), product teams, and sales & marketing. It is highly likely that Datadog will pivot into this area soon, as I recently opined [paid].
- SaaS services: Amplitude, LogRocket, Pendo, Heap, Mixpanel, Statsig, mParticle/Indicative
- open-source: PostHog+
Snowflake is partners with Amplitude, Pendo, MixPanel, and Heap, who won their Marketplace Partner of the Year in 2021. All of these tools have integrations to the Modern Data Stack, but some are deepening how they work. For instance, Amplitude previously had bi-directional integration with Snowflake, but as of May-22, deepened its partnership and data integration capabilities by using data sharing to enable new reverse ETL to enrich data in Amplitude, and allowing customers to directly query their Amplitude data via data sharing.
CDP / Reverse ETL
Taking customer-focused analytics a step beyond the software stack, Customer Data Platforms (CDPs) are emerging that sit as an umbrella over a data warehouse and sales and marketing tools. They provide the data pipelines to ingest data from operational tools, perform BI analytics over that data to isolate customer behaviors, then push derived insights back into the original operational tools. This ultimately becomes a round-robin analytical service to help improve and drive sales while leveraging the analytical capabilities of the underlying data stack. Reserve ETL is the last step of that process, providing data pipelines to move analytical insights back into operational tools. Some of these tools, like Census and Hightouch, are leveraging dbt as a transformation layer.
- SaaS services: Twilio/Segment, mParticle, Hightouch, Census, Hevo Data, HeadsUp, Polytomic, Kanaree, Octolis, Tealium, Calixa, Adverity, Lytics, Affinio
- open-source: Airbyte/Grouparoo, Rudderstack+, Snowplow+, JITSU+
Snowflake partners with Segment, Hevo, Census, Calixa, Adverity, Lytics, and Snowplow.
There are big differences in these tools, and many integrate and partner with each other. CDP platforms tend to be the complete umbrella, providing an analytical service in between ETL and reverse ETL processes. Some embed in app code (via SDKs and APIs) like product analytics platforms above. Others, like Hightouch and Census, focus more on just the reverse ETL, being an integration layer that sits over the data lakehouse, to push insights back into operational tools.
I'm not that crazy about the name given to "reverse ETL", but I haven't seen anything better. I prefer to think of it as "operationalizing insights", where these focused platforms extract operational data, gain insights from that data gathered in the data warehouse, and automate a pipeline of actions to take from there back into the operational tools. See this helpful explainer from Hightouch, which includes this bit on keeping the data warehouse as the center:
"Reverse ETL creates a hub-and-spoke approach, where the warehouse is your central source of truth, completely eliminating the complex web of pipelines and workflows that come with conventional point-to-point solutions."
How a CDP typically works:
- The platform takes input signals from existing SaaS tools and instrumented web/mobile apps into the data warehouse (ETL). Sources might include website tracking, app event data, transactional data, sales tools, ad data, & marketing campaigns.
- A customer profile is built from all these sources, which might link together web app behaviors, marketing efforts, purchase history, customer support incidents, & social activity. It then runs behavioral analytics (within the data warehouse) to hone insights such as customer health scoring, customer enrichment, sales lead scoring, marketing personalization, ad audiences, and product enhancements.
- The platform then outputs those insights back into sales & marketing tools (reverse ETL), such as Salesforce, Hubspot, Marketo, Klaviyo, Gainsight, Iterable, Braze, ad platforms, etc. They might also feed into product feature release tools like Split, Apptimize, and LaunchDarkly, as well as product analytical tools like Amplitude, Pendo, and Indicative.
Segment (acquired by Twilio) has a "CDP Report" that comes out annually. The 2022 edition in Feb-22 had a few nuggets:
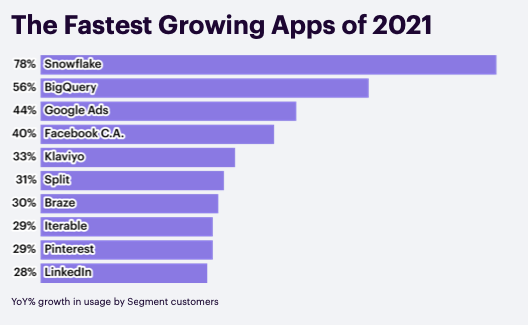
"Unpacking the growth of Snowflake on the Segment platform, much has to do with its ease of implementation and scale. With Segment and Snowflake, you don’t have to build your own ETL pipeline to stream data from your mobile apps and websites into a data warehouse. You can also stream data from other sources like your CRM, help desk, payment systems, or email marketing tools. Segment schematizes and loads all of this data for you with no extra configuration required. Snowflake’s platform scales automatically and supports fast queries with practically no limits on how many analysts can access it at once. Automating this process will save your engineering team a significant amount of time. On average, our customers reported it would take 108 engineering hours upfront and 40 hours of maintenance per month to implement a warehouse pipeline on their own. With Segment, that time shrinks to just a few minutes spent authorizing your Snowflake account."
Snowflake partner NOW/Affinio is a CDP platform that provides a platform of data apps to track customer personas, behavior predictions, and audience groupings. They became a partner in the new Native Apps Accelerated and released a new native CDP app for Snowflake in Jun-22, shifting these enrichment products into fully embedded apps within each customer's database.
Related to CDP platforms are embedded Customer Engagement Platforms such as Supergrain and MessageGears. These are tools that sit over or within the data lakehouse to monitor metrics and customer events in order to generate and send marketing messages. These tools can help eliminate the need for reverse ETL or heavier CDP, and Snowflake partners with both.
Headless BI
"Headless BI" tools are emerging for tracking operational metrics in a uniform way, as an abstraction layer that other BI tools then utilize.
In this context, think of headless services as a proxy over the database that other tools will integrate with, in order to better control and manage how those tools work with the underlying data.
Headless BI tools are a backend service that becomes the primary interface (via APIs) for other BI tools to connect to the data, which allows it to serve as a Metric Store, a centralized repository of the metrics & dimensions an organization uses to analyze itself in those BI tools (which it translates into the SQL needed under the hood). The headless BI might even control how raw data is modeled, and some platforms are again leveraging dbt for transformations. Having metrics tracked in an abstraction layer could replace the transformation stages needed in ETL/ELT – which again reduces the complexity of data flows and improves the speed & nimbleness of BI analysis. Headless BI tools ultimately provide a semantic layer for making BI consistent across an organization, giving an enterprise a "common language" to track and unify the metrics that business analyst teams should use across the data.
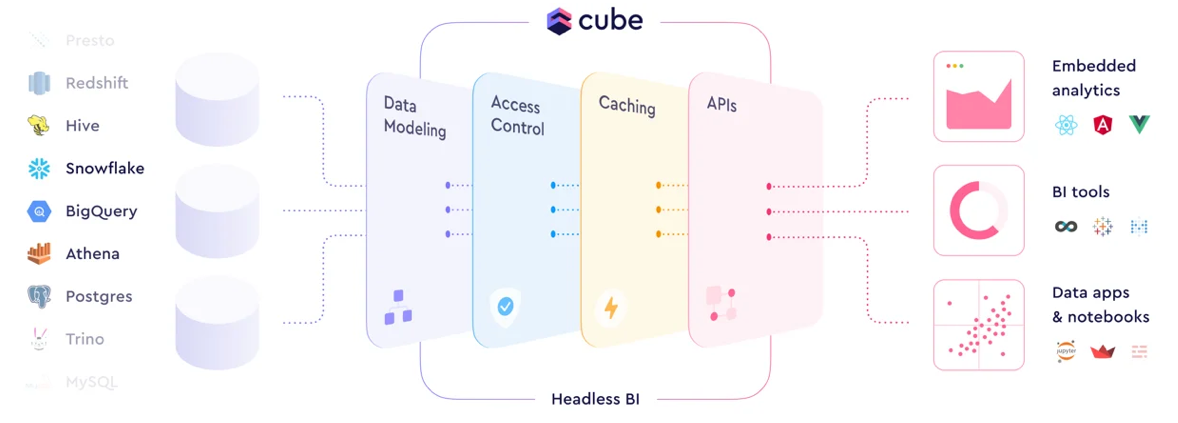
- SaaS services: Rasgo, GoodData, Trace, Maxa.ai, Overlay Analytics, Kyligence
- open-source: Cube+, MetricFlow+ (Transform), MetriQL ("sigma"-QL), MLCraft
Snowflake has invested in Overlay Analytics, their 2021 startup challenge winner, and partners with Rasgo, GoodData, and Maxa.ai. Rasgo is embedding deeper with Snowpark.
ML/AI Analytics
AI, and especially the data-driven subset called machine learning (ML), is typically trained and run over raw data. Data scientists can create and run ML models to generate risk scoring, make predictions, or extract meaning from text or unstructured data. Because of the unpredictability and on-demand nature of these jobs, and the variety of data & formats that are being scanned over, data lakes have become an ideal foundation of ML/AI. All the same ingest processes for data warehouses and BI apply to ML/AI, to move raw data into data lakes – though is generally up to the data scientists to manipulate that raw data into usable formats for analysis from there.
Open-Source Tooling
Data scientists utilize a huge number of open-source programming libraries & tools (typically in Python & R), and notebooks to run code interactively (used for data exploration and ML workflows).
- open-source libraries: Tensorflow, PyTorch, scikit-learn, Keras, Kedro, Numpy, Pandas, XGBoost, SciPy
- ... dev environments: Anaconda+, Spyder, RStudio (R)
- ... notebooks: Jupyter, Apache Zeppelin, Polynote (Scala), MLreef
- ... data visualization: Plotly+, Bokeh, Matplotlib, Seaborn, HoloViews, Altair, Yellowbrick, Folium (geo)
- ... data interactivity: Snowflake/Streamlit, Plotly Dash+, Panel, Voila, R/Shiny
- ... ML community: Hugging Face+, DagsHub+, Kaggle, OpenML, MLOps Community
- ... analytical engines: Spark+ (Core, SQL, Streaming, MLlib, GraphX, PySpark), Hadoop (Core, HDFS, YARN, MapReduce, etc)
- ... Python boosters: Dask+ (MPP Python), Bodo+ (MPP Python/SQL), RAPIDS (GPU), Ray, Vaex, Modin
- ... model deployment: Kubeflow, Nuclio+, Seldon+ Core, KServe
Snowflake acquired Streamlit for data interactivity, and partnered with Anaconda to enable using these open-source libraries in Snowpark for Python – plus will soon have native Python & Java notebooks in its Snowsight UI. Snowflake has invested in Anaconda and Bodo.
ML/AI ecosystem
There are a number of ML/AI services that sit over the Modern Data Stack above as a data source. In fact, the majority of data ingest, orchestration, governance, observability, and quality monitoring tools above for BI can be applied to ML/AI workflows, as well as transformation tools for data scientists to clean, blend, and manipulate raw data sets into usable ML training sets. Complete platforms exist to provide code environments and no-code tools for data wrangling and creating ML models & managing the ML lifecycle.
- SaaS platforms: ThoughtSpot, Dataiku, DataRobot, H2O.ai, Alteryx, Continual, cnvrg.io ("Converge"), whiz.ai, Databricks, Palantir Foundry, C3.ai
- ... collaborative notebooks: Mode, Hex, Deepnote, DataRobot/Zepl
- cloud platforms: AWS SageMaker, Azure ML, GCP Vertex.ai, IBM Watson
- ... no-code: AWS SageMaker Canvas, Azure ML Designer, IBM Watson Studio
- ... collaborative notebooks: AWS SageMaker Studio, Azure ML Studio, GCP Vertex.ai Workbench, GCP Colabratory
- ... managed analytical engines: AWS EMR & EMR Serverless, Azure HDInsight, Azure Databricks, GCP Dataproc & Dataproc Serverless, GCP Databricks, GCP TPU (TensorFlow on custom ASIC chip)
Snowflake has invested in ThoughtSpot, DataRobot, Dataiku, and Hex, and has partnerships with H2O, Mode, Alteryx, Deepnote, and Zepl. Once Snowpark for Python was released, Hex and Deepnote both supported it natively within their collaborative notebook platforms (and hopefully Mode does soon too). DataRobot & Zepl are now leveraging Snowpark to do pushdown feature engineering and embed Java models. Dataiku, H2O.ai, Alteryx, whiz.ai, and C3.ai are also embedding deeper with Snowpark.
Workflow Tools
There are a variety of tools for the ML workflow, many of which can live atop the Modern Data Stack.
Like with Metric Stores in BI, Feature Stores provide a way to collaborate & unify the aspects of structured & semi-structured data that data science teams are looking for, to essentially provide data management services over ML workflows.
- SaaS services: ... many of the MLOps platforms below, like Tecton and Databricks
- cloud services: AWS SageMaker Feature Store, GCP Vertex.ai Feature Store
- open-source: Feast+ (Tecton), Hopworks+, Butterfree
Data lakes also provide a good platform for processing a pool of unstructured data files (PDFs, documents, images, audio, video). Data Labeling services exist to help mark unstructured data in the same way as Features Stores do over structured/semi-structured data, to add informative labels – especially helpful in natural language processing (NLP) for understanding text and computer vision for understanding images.
- SaaS services: Scale, Label Box, Datasaur, Snorkel, Tagtog, SuperAnnotate, Heartex, V7
- open-source: Label Studio+, CVAT, VoTT (...and a whole lot more here for specific use cases)
Model Observability tools can help monitor the quality of the ML model output, in order to measure drift (where the accuracy of the model falls).
- SaaS services: Neptune, Aporia, Galileo, Superwise, Fiddler, Arize, WhyLabs
- open-source: Flyte, Seldon Alibi Detect & Alibi Explain, TensorBoard
MLOps are full-stack tools to run the entire ML workflow. I like to think of this as being like a DevOps CI/CD pipeline, for collaboration, automating the ML workflow as a set of repeatable and trackable steps, and tracking & monitoring the ML models through their lifecycle. These typically include feature store and model observability features.
- SaaS services: Tecton, Weights & Biases, Domino Data Lab, Abacus.ai, Comet, Iterative, Alteryx Promote+Server, DataRobot/Agorithmia, Iguazio, Polyaxon, Valohai
- cloud services: GCP Vertex.ai Pipelines, AWS SageMaker MLOps, AWS SageMaker Pipelines, Azure ML
- open-source: MLflow+ (Databricks), Polyaxon+, ClearML+ (was Allegro), ZenML+, BentoML, Metaflow, MLRun, MLreef, AngelML, Determined.ai
- ... GitOps tools: DVC (git for ML), CML (CI/CD for ML)
Like with Headless BI, Headless MLOps platforms are beginning to appear, to create, manage, and run ML models all within a centralized data lakehouse. That same notion of "semantic layer" applies here, with headless ML tools allowing for centralized Feature Stores stored within the data lakehouse to track and unify the features that data science teams are tracking in the data, plus being able to centrally track and manage complex ML workflows.
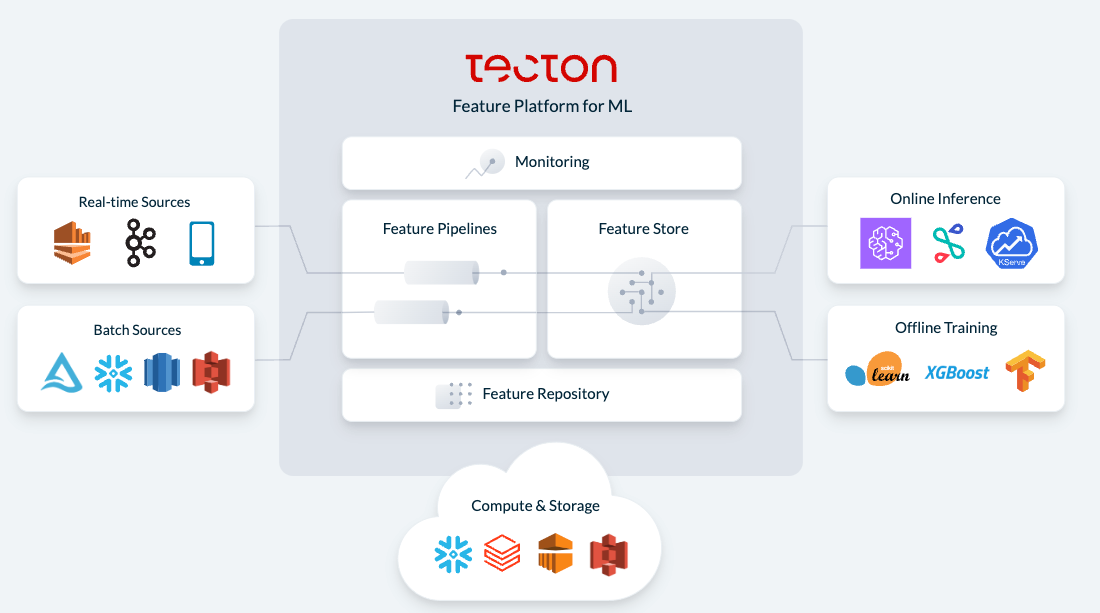
Snowflake has invested in Tecton, Domino Data Lab, and DataRobot. Tecton is now leveraging Snowpark to allow customers to embed the entire ML workflow into their Snowflake database, and Domino is also embedding deeper with Snowpark (as are DataRobot and Alteryx as mentioned before).
AutoML is another shift in the industry, to use ML/AI over the MLOps workflow itself in order to find the best ML model for the analytical task at hand – ultimately making data science more accessible and automated. In a nutshell, it's "ML used to run ML". This, of course, explodes the amount of compute needed, as it trains and tests various ML models for the best fit.
- SaaS services: ... many of the ML platforms above, like H2O.ai, DataRobot, Tecton, Alteryx
- cloud services: AWS SageMaker Autopilot, Azure AutoML, GCP AutoML
New directions in BI & ML
There are a number of new directions that are changing the BI & ML landscape, to provide more interactive analytical capabilities directly over your software app or customer tracking tools.
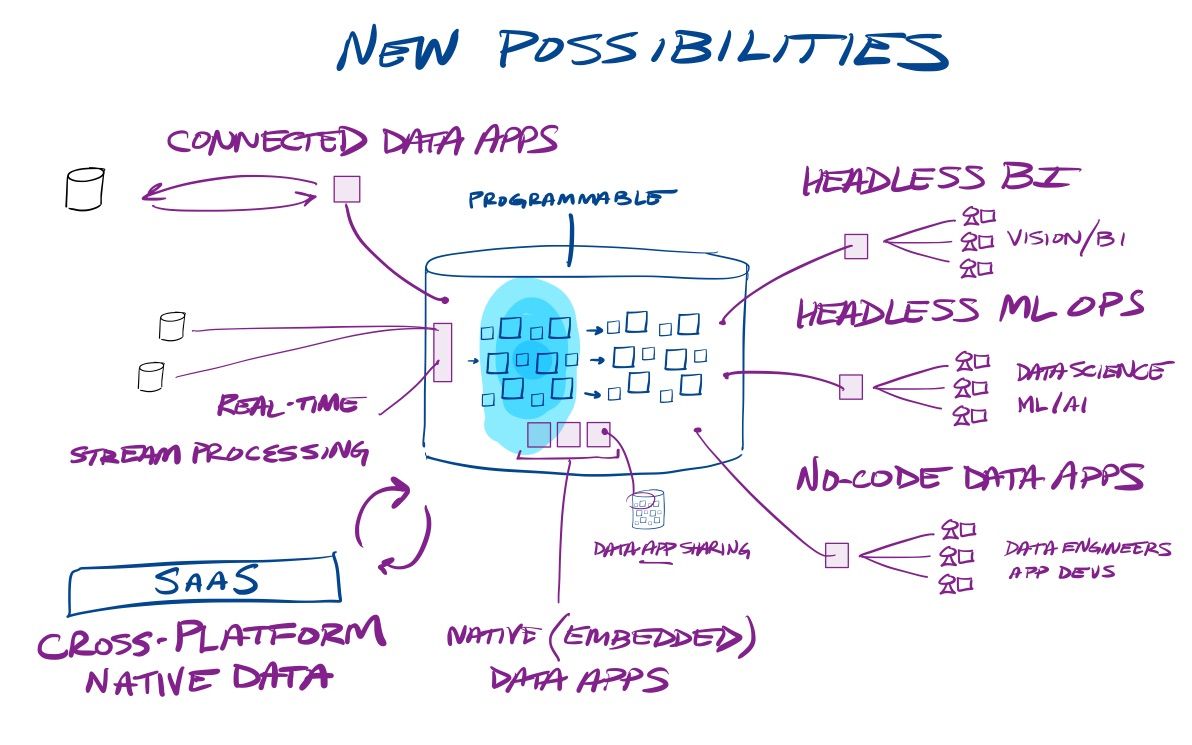
Abstraction Layers
The moves into headless BI (metric stores) and headless MLOps (feature stores and full ML lifecycle mgmt) detailed above are creating abstraction layers over the centralized data lakehouse. BI users and data scientists are pointing their tools to a headless service, which then gives all users a common understanding of the data, plus acts as a controller to centrally manage analytical workflows. These tools greatly enable the "self-service" nature of the data lakehouse. What I like most about these abstraction layers is that they expand the audience of who is using the data lakehouse, without those users being aware of the underlying details. Headless BI can power no-code BI tools used by business users, who don't need to have any knowledge of SQL. Headless MLOps can be running AutoML jobs (lots of compute!) and ML workflows for teams of data scientists, who can use their preferred language and toolset instead of SQL. The more collaboration capabilities and workflow processes that are run upon the database, the more compute. The more the audience expands, the more compute.
Like no-code serverless SaaS platforms for data orchestration (on the ingest side), there are now serverless platforms emerging on the BI side for creating data apps from the insights being unlocked within (the analytical results). No-code data app platforms are emerging, such as TinyBird, Cascade.io, and Houseware, that allow data owners, product teams, and non-technical business users to easily build data apps from analytical data in the data lakehouse — without needing to be a coder. Of course, Snowflake is pushing capabilities with Snowpark and Streamlit, where Python coders (like data engineers and data scientists) can build interactive data apps for ingest or sharing analytical results directly within the database. What I like about these no-code data app platforms is they provide a similar abstraction layer, which again helps expand the audience.
CEO of Vercel: “Tinybird is the most exciting data company since Snowflake. It's revolutionized the way we think about realtime data analytics at Vercel, for billions of data points per day.”
Houseware won Snowflake's 2022 Startup Challenge, and this LinkedIn post by their founder explains their background, and how they are leveraging Snowflake's new Unistore, Snowpark, and Native App features in their platform.
New App Models
With Snowpark, Snowflake is beginning to unlock new capabilities where integrated app stacks can more tightly sit over and/or within the Data Cloud. It can be used to provide a service directly over a customer's database (using that database as its compute layer), or now deploy embedded apps directly into the customer's database. In either case, the service can interact with that customer's data, or create datasets of its own for that customer to use. This is allowing all new models of deployment that are unique to Snowflake, and they are now highlighting 3 different models for partnering services to interoperate with the Data Cloud (as previously discussed [paid]) – and a recent announcement has seemingly added a 4th (see the Salesforce news below).
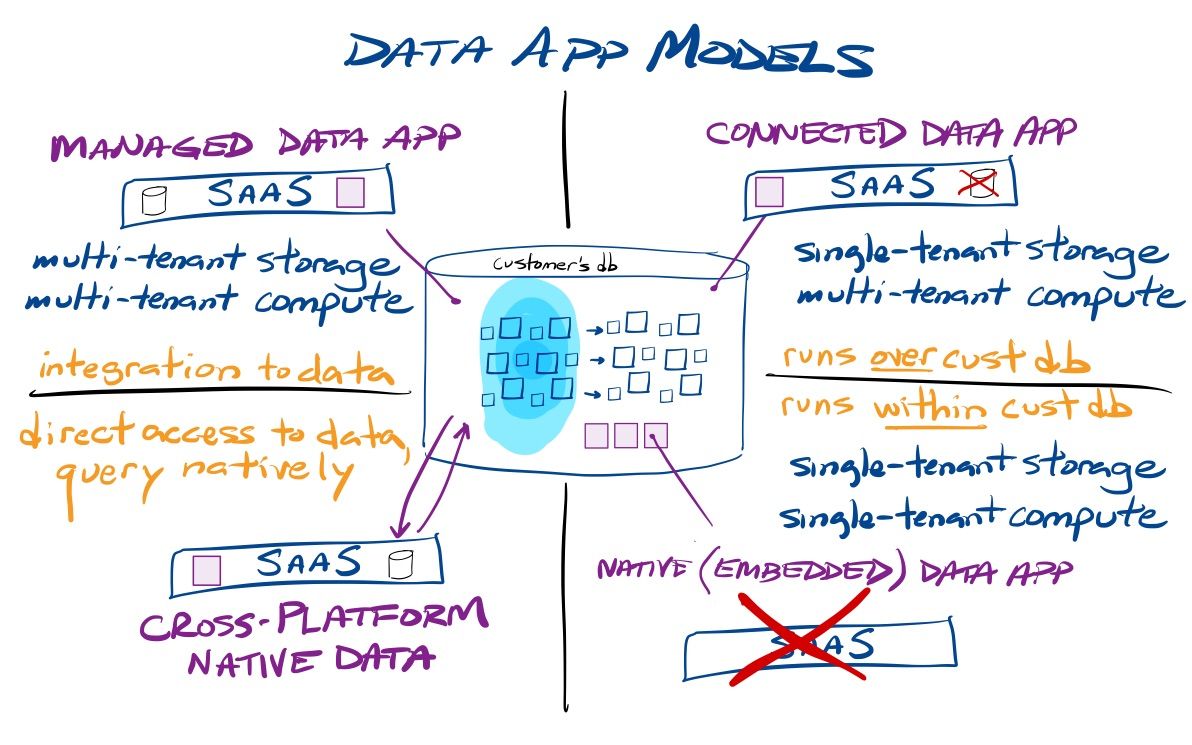
- Managed apps (multi-tenant storage, multi-tenant compute) is the traditional SaaS app deployment model, where a platform can use direct integrations (via database drivers and APIs) to interact with the customer's data, but all compute and storage of the core SaaS service are kept separate and maintained by the provider. The only compute in Snowflake is the initial export of data into the managed app, and the ending import of any results it sends back.
- Connected apps (single-tenant storage, multi-tenant compute) can be used to provide SaaS services directly over a customer's database. This treats a SaaS application as if it was built over Snowflake itself, but on a customer-by-customer basis. A connected app can act as an umbrella over the data lakehouse, and can perform actions such as ingesting external data into the customer's database (compute!), running analytics over that data (compute!), and extracting insights out (compute!). Connected apps can still maintain multi-tenant storage for crowdsourced analytics and cross-customer concerns, but all compute over that customer's data is in Snowflake. The connected app model seems ideal for data orchestration & ingest, CDP, Reverse ETL, Headless BI & MLOps, No-code Data Apps, and Cybersecurity Workload platforms.
- Native apps (single-tenant storage, single-tenant compute) can be used to provide services directly within a customer's database, as an embedded app service. Any self-contained application or ML model can be embedded, and can both interact with existing data in the data lakehouse (including external data lakes), as well as create tables for itself. This is not for any applications that have external compute needs or cross-customer concerns (like crowdsourced analytics), given that every customer is their own island, apart from all the rest. But flip that around, and you can see it as a huge benefit in heavily regulated industries, as native apps can assure the privacy and security of the customer's data, as it never leaves their control. The initial use case they gave was providing interactive data apps (dashboards and visualizations) with Streamlit as a native app. Another use case was for running MLOps actions around the ML model lifecycle – where models can be deployed, run, managed, and monitored as a native app. I think we'll see self-contained data enrichment and unstructured data processing, enterprise tools for data governance and observability/quality, and self-contained observability and security data lake solutions emerge as native apps.
Hyperscalers have long had an advantage in their ability to create larger data ecosystems that span both operational data as well as analytical data (across data warehouses, data lakes, operational relational or NoSQL databases, container/VM services for app stacks, and serverless functions). It feels like Snowflake is creating something new here with native/embedded applications, where the cloud providers cannot compete.
SaaS services can adopt more than one of these models within their platform, and could be making a choice on which to use based on whether the customer is a Snowflake customer or not. I think we will see a lot of hybrid scenarios, where managed & connected apps "go native" for select features – where a piece of functionality is decoupled from the main SaaS platform and deployed natively (embedded) into a customer's database, and generate output data that the managed or connected app could access. Given that Snowpark for Python is of high value to data engineers and data scientists, I think we'll soon see data orchestration and ML/AI platforms leveraging this hybrid model to deploy data and ML pipelines into the database. ML models could be trained over crowdsourced (cross-customer) data in a managed app, then deployed as native apps directly into a customer's database in order to provide data enrichment, health/risk scoring, or predictions over private data that the service cannot see.
Monetization of native apps via the Marketplace is a key feature of their roll-out of Native App Framework, in order to spur adoption. But I think that is just the start of the possibilities. Where I think native apps get even more interesting is when you mix in all the other capabilities in Snowflake. You can share data apps, just as you can share data – so you can use native data apps in collaborative ways. This opens up a lot of possible scenarios.
- Industry Clouds and data clean rooms can leverage data apps for shared capabilities across partners and/or customers. This can help provide secure and privacy-protecting industry-specific capabilities in these highly regulated industries.
- Data apps can provide compute capabilities directly inside the data clean rooms, or leverage shared data apps to open up new possibilities beyond those clean rooms across partners.
- With data sharing, deployment doesn't have to be into a customer's database. A provider could have a shared data app that it controls and runs in its own database (cost center) that can be interacted with by customers via sharing.
- Or, to flip that, a provider could deploy native apps into multiple customers' databases that can be shared back to the provider, so the provider can call and interact with it directly.
- Native apps could be running in multiple customers' databases, and interacting with each other via data sharing. Native apps don't have to be stand-alone and self-contained!
From there, add in other features.
- Streamlit can give a native app an interactive UI.
- Native apps could leverage the new Unistore hybrid tables to track transactional data or allow data entry.
- Native apps could build upon the new streaming pipeline capabilities for stream processing of incoming events in near real-time.
- Native apps could interact with external data lakes, and be doing data processing or extracting meaning from unstructured data.
- Native apps could be reading in files from an external data lake that were being provided by a connected or managed app.
- Native apps could store data into Native Iceberg Tables, and from a connected or managed app then use other data lake tools to interact with it.
A number of partners are already building over Snowflake in the connected model in their new Cybersecurity Workload, including Panther, Hunters, and Securonix (all of which Snowflake has invested in). Other platforms built atop Snowflake, like Observable and Lacework, might soon follow this model. Elysium Analytics, another platform for security data lake analytics, is embedding deeper with a native app.
Cross-Platform Querying
One interesting tidbit from last week was how Salesforce & Snowflake deepened their integration to allow bidirectional cross-platform data access natively within each others' platforms. This is erasing the boundaries between a major SaaS platform and the Data Cloud, and I find it an exciting move. Just this week, at their annual Dreamforce event, Salesforce announced Genie, a new real-time CRM platform that can combine real-time data streams, data from operational tools, and historical data in data lakes – and which ties to Snowflake and AWS SageMaker. This seems a big move to counter the rise of CDP platforms. [And I look forward to hearing more about the underlying architecture here.]


Add'l Reading
- Friend of the blog Francis @ Contrary Research (aka @InvestiAnalyst) published an extensive breakdown of Snowflake vs Databricks. Also check out Contrary's repository of research over private companies, which includes writeups on several companies mentioned in this piece (Panther, Lacework, and Hugging Face), as well as several other companies of interest across data, security, enterprise tools, and DevOps (Snyk, CockroachDB, Grafana, Repl.it, and Ramp). [And thanks to them for heavily linking my past Snowflake & Databricks pieces!]
- Peter Offringa of Software Stack Investing has also covered Snowflake announcements and earnings extensively. I had discussion with him on the Premium podcast to walk through the product news out of last year's Snowflake Summit.
- I also wrote a multi-part series on AI/ML [paid] in April & May that covers the rise of Generative AIs + LLMs, and what Microsoft and Google are building in AI platforms.
- I just wrote a four-part series over the past week on the various competitive moves between Snowflake and Databricks, as well as all the recent announcements at Snowflake Summit and Databricks Data+AI Summit. Join Premium to read more!
- muji