
I last discussed how application development has evolved, as workloads migrate to the cloud (ranging from VMs to containers to serverless functions), which has also triggered moving from monolithic app stacks to distributed ones. As a follow-up to that piece, it's important to understand the reasoning behind some of the major app stack architecture & tooling.
Just the Beginning
I was recently asked how far along the migration to the cloud is. My answer was that cloud usage still feels closer to infancy than maturity. Technologist Ben Evans last released his annual look at the state of technology in Dec-21, entitled "Three steps to the future". Beyond looking at future trends in crypto & metaverse, he talks about the ongoing migration to the cloud in the present, using Gartner estimates that only 10-15% of IT spend has migrated thus far.
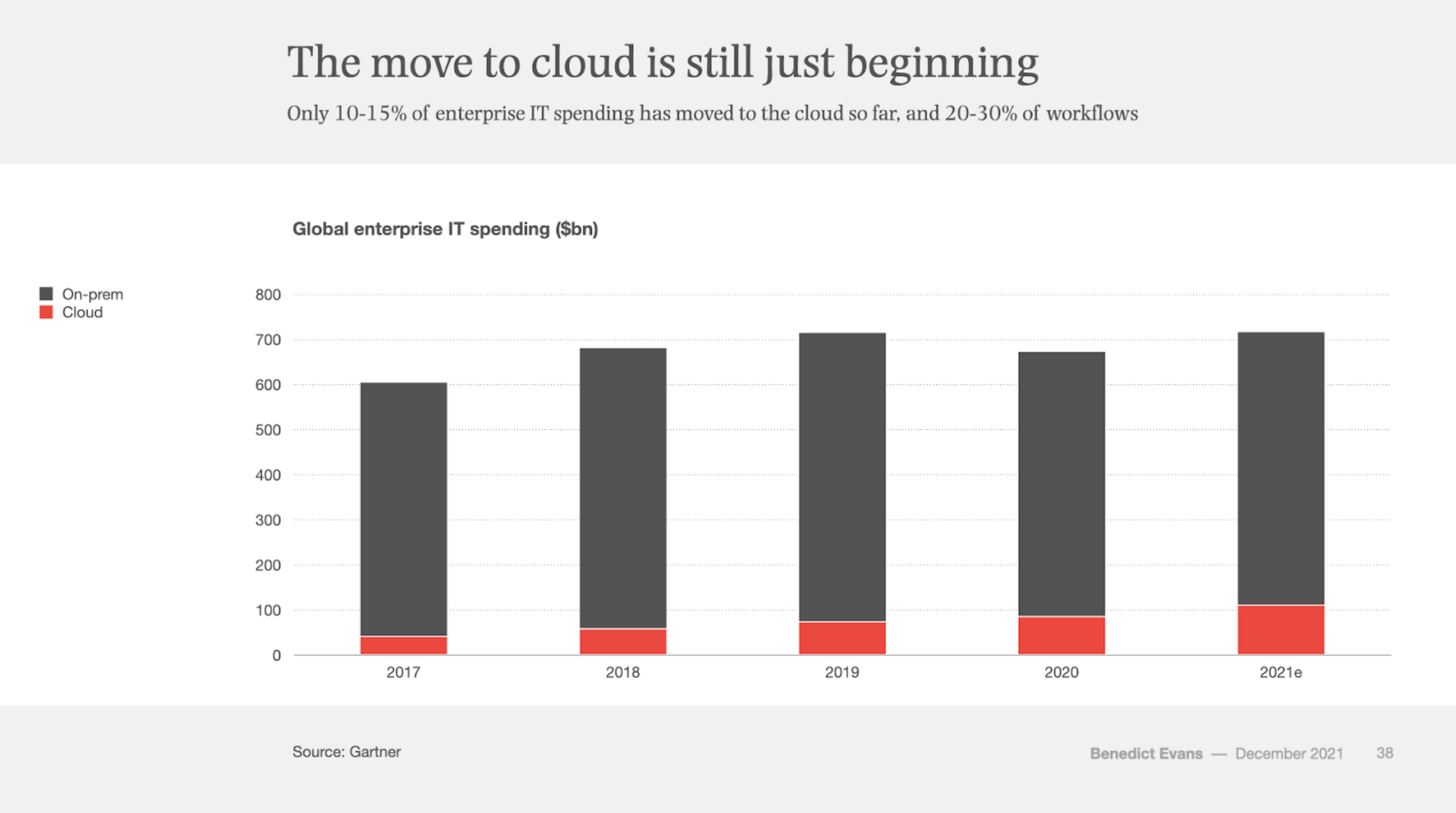
While Gartner estimates that 70% of businesses have started to explore the cloud, it seems that only 20-30% of workflows have been migrated to date. Beyond that, Gartner has seen some trends in moving to the cloud, that I think have consequences for organizations:
- Cost optimization will drive cloud adoption: This was not directly Gartner's meaning, but in my opinion, this striving for lower TCO will affect how workloads will be migrated. Instead of migrating legacy app stacks, they should be refactored to better take advantage of cloud-native infrastructure.
- Insufficient cloud IaaS skills will delay migrations: Not surprising that it is hard to hire DevOps staff that know and understand cloud infrastructure & app stacks!
- Distributed cloud will support expanded service availability: Cloud-savvy companies are beginning to improve their app stacks by refactoring into cloud-native (and even edge-native) services, to leverage their scalability, global reach, and high availability. Once again, migrating existing on-prem workloads is just the beginning – as companies migrate to the cloud, they should start expanding how they leverage it to start increasing their application's uptime and responsiveness.
So companies need to get better and better about utilizing more of the capabilities exposed by cloud-native infrastructure while dealing with the lack of talent in how to use the underlying IaaS architectures. A difficult needle to thread! Luckily, DevOps now have a variety of tools and services in their arsenal to help on both those fronts. As I concluded before, these directions, in turn, lead cloud usage to have more dynamic and ephemeral workloads than have been done on legacy on-prem stacks. This is being driven by the programmability of infrastructure, and by the ongoing move into distributed app architectures.
Infrastructure as Code (IaC)
DevOps teams now have the ability to provision and manage raw infrastructure via code – not only systems like bare metal or VMs, but software-driven networks as well. IaC tools allow for storing infrastructural changes as configuration files – meaning that, like software code, it can be tracked, secured, tested, and deployed. Codifying infrastructure gives you all the benefits that developers get with application code – you can now track changes and utilize a wide variety of developer tooling to test and deploy those changes.
The "code" in IaC tools can be imperative (procedural) or declarative (functional) in order to have any piece of infrastructure reach the desired state. Let's define these terms right quickly, as I use them throughout.
- Imperative tools allow for programming infrastructural changes line by line in a configuration file, to control the provisioning via a set of sequential commands to run.
- Declarative tools have the configuration file declare the desired end state. In this case, the tool must track the current state of the system, and derive & run the steps needed to bring the system up to the desired state.
IaC tools allow for programmatic infrastructure, to utilize one of these two methods to propagate provisioning and modification commands to the underlying infrastructure it controls. Popular open-source tools include Ansible, Chef, Puppet, SaltStack, HashiCorp Terraform, and CloudFoundry. Every cloud provider has its own specific one as well, including AWS CloudFormation and Azure Resource Manager (ARM).
IaC gives Ops teams:
- Consistency: Ops can provision or upgrade systems in a standardized, repeatable fashion. They no longer need to make updates/patches/changes directly to systems – they instead can use IaC to do it in a controlled manner that is consistent and trackable.
- Trackability: Ops can now use version control systems (VCS, aka source code repositories like GitHub and Gitlab) to track versions and revisions of infrastructural needs, in a secure, governed, and audited manner across their team. They can then use this to create a repository of standards for how certain classes of infrastructure or apps stacks are to be deployed. (For instance, every VM created must have certain security policies applied.)
- Automation: Ops can automate all infrastructure provisioning or changes to simplify their processes, in order to do more with less staff. Developers no longer need to know or understand how the underlying networks and systems are set up, and so can keep their focus on the app stack.
- Testability: Can tie into CI/CD tools in order to test their code, to reduce the risk of introducing issues when provisioning or changing infrastructure. They can utilize code reviews to validate infrastructural changes before deploy, and use automation to test changes in a sandbox environment.
- Composability: IaC scripts can be used as building blocks across cross-functional Ops teams (say, across different teams that are each responsible for separate parts of networking, bare metal systems, VMs, cloud infra, and security), as well as creating separate matching environments for testing, staging and production environments for app stacks.
Cloud environments require a different mindset than on-premise infrastructure, as apps and workloads can be more dynamic and ephemeral – you aren't destroying and rebuilding on-prem infrastructure on demand! IaC tools help unify all of these concerns into a common environment where you can automate and simplify your infrastructure regardless of the environment. These tools pay for themselves, as it allows an Ops team to automate in order to do more with less staff, while greatly reducing risk (with changes audited and tested).
Containers
Containers are stripped down & minified VMs that strip away a lot of the concerns about the underlying operating system and base application stack being installed. If you recall from my prior piece, containers are programmable blocks of infrastructure built upon multi-layer templates called images. Containers are a separate form of IaC – it is codified infrastructure, but structured more around app stacks. Each DevOps team can maintain and deploy their own app stack, without caring about the underlying infrastructure hosting the containers. Containers can be rebuilt as needed, with the assurance that it will create the same final image in each build.
What containers allow for are more composable app stacks, by breaking it into its base layers (web servers, app frameworks, middleware, data stores, load balancers, firewalls). Each component can be served by its own container, which can be separately deployed and scaled as needed, apart from the others. Need to handle more concurrent requests from your web app? You can scale up the components that handle that, by creating a pool of containers and putting a load balancer in front of it. No longer need to have that large a capacity? You simply scale it back down, and reduce your infrastructure usage. And once you are using container orchestration, the platform itself can scale those for you, automatically.
Popular container formats are Docker and Rocket, which use imperative configuration files to procedurally build a container from images, configuration changes, and runtime commands. Once you break your app stack into components (each having its own container), you can use container orchestration platforms like Kubernetes (K8s) or HashiCorp Nomad to create workflows around interdependent containers. Orchestration platforms are controllable, both through a UI as well as programmatically through APIs, which allow you to control how containers scale and how to handle errors, plus have secure intercommunication and load balancing capabilities built in. A common IaC method in Kubernetes is using the Helm tool to deploy containers via declarative configuration files known as "Helm charts", which greatly simplifies deploying interdependent containers into a cohesive app, and allows Kubernetes to dynamically control the desired scale of the individual containers deployed.
Containers greatly expand on the consistency aspect above in IaC, as it now allows the concept of immutable infrastructure – meaning you no longer have to maintain or patch the underlying operating system or app framework. You don't update software in place in a container – you simply update the build requirements (to update the version of the underlying OS or software installed) and rebuild the containerized application from scratch. You then test the final result, and can use a variety of techniques to launch the newly updated container and deprecate/destroy the prior one.
Containers give DevOps teams:
- Consistency: Anyone can build and deploy the container and be assured to get the exact same copy everyone else has. This leads to easier-to-manage DevOps processes, as developers, designers, and Ops are assured to have the same exact copy of the app, regardless of location – whether on developer & designer laptops, or test, staging, and production stacks. This helps eliminate any differences between environments, including on-prem vs cloud, operating system differences, underlying software versions, or changing app dependency versions.
- Composability: While you can build a monolithic application in one large container, it is best to break your application up into the separate layers of your app stack, and create a container for each. Each is then specific to purpose, and can be better controlled, managed, deployed, and scaled independently.
- Statelessness: Most portions of the app stack are encouraged to become stateless (aka does not store data locally), which allows for greater scale and flexibility in deploying. In essence, being both consistent & stateless makes containers fungible – replaceable with another exact copy. Only persistent data storage, like databases, should remain stateful, as it then requires separate methods for maintaining its data across re-deployments of that container (such as keeping any shared data on a persistent file store).
- Flexibility & Scalability: Having your app stack broken down into stateless composable blocks means that each is deployable and scalable on demand. Any particular part of your app stack can be scaled up or down based on real-time usage & need. Containers can be created and destroyed as needed, which also makes them ideal for running infrequent batch processes, plus allows for a high degree of flexibility in deployment. [I covered several deployment strategies before in my Datadog deep dive, including blue-green and canary.]
- Immutability: You no longer need to maintain the underlying operating systems and app stacks for ongoing maintenance and patching. Each layer of a container is pulled in through an image (template), which is itself composable and replaceable at any time. To upgrade, you simply rebuild the container from a new image having the updated underlying operating system or software, and, once tested, use those (just mentioned) deployment techniques to replace the old container(s) with the new.
- Portability: Containers can now be easily hosted in a wide variety of locations. Open-source container orchestration platforms include Kubernetes and HashiCorp Nomad, which can be installed onto any self-managed on-prem or cloud infrastructure. Or enterprises can use managed services to run long-running containers (like AWS EKS, AWS ECS, Azure AKS, and Google Anthos), or PaaS serverless platforms that run containers on demand (like AWS Fargate, Azure Container Apps, and GCP Cloud Run).
All in all, containers turn infrastructure into programmable blocks owned by DevOps instead of just Ops. The separate parts of an app stack are broken into composable parts that are stateless and immutable, which can be separately deployed, scaled, and destroyed as needed.
Microservices
Microservices are a distributed application architecture that breaks an application's features up into separate pieces. For example, an application can be broken up into separate components based on the part of the operational workflow it deals with (such as customer, inventory, sale, and payment processing portions of an e-commerce app).
Breaking up a large singular "monolithic" application also breaks up developer responsibilities, into focused teams owning just their portion of the application. Each microservice is then developed, deployed, and scaled independently. With distributed architectures, you are distributing the responsibilities. Each team can write in whatever programming language they desire, and be hosting their services on different infrastructure – both within the limits set by the organization. Containers provide an ideal mechanism for creating and hosting separate microservices, especially in polyglot environments (where multiple programming languages and app frameworks are being used). Each container is set up independently, focused solely on the needs of its individual service. (Again, containers allow for the developer to be in charge of the infrastructure.)
Adopting microservices also comes with challenges. Microservices are splitting applications up into 10s or 100s of pieces, which magnifies the complexity of every step of the DevOps workflow (how to develop, build, test, deploy, monitor, and secure these individual services), and are no longer closely tied together with the other parts of the app (loosely coupled). An enterprise typically needs to set some rules up as guard rails around how the microservices need to interoperate, to force every team to maintain a "contract" with the rest of the organization about the behavior of their service and how to interface with it. Every developer team is then focused on their part of the greater whole, with their microservice(s) acting as an API into the feature set they own. In total, microservices are essentially the API Economy across a single organization, allowing a part of the business to interact with the other parts.
Using this architecture requires some type of system for service discovery, security, intercommunication, and monitoring. A service mesh provides a platform to manage and secure the intercommunications between an enterprise's various services. Open-source tools include Istio, Open Service Mesh (OSM), Linkerd, and HashiCorp Consul. Some deployable app stack platforms, like the Google Anthos and Azure Arc platforms [discussed in premium], have directly embedded their own service mesh capabilities. There are also several cloud-specific managed solutions (like AWS App Mesh and GCP Anthos Service Mesh), and enterprise SaaS solutions (like Kong).
Microservices give developers:
- Responsibility: Separate teams are responsible for only their own microservices. Each team is a master of their separate domain, yet must have an enterprise-wide contract with all the other teams, on what they need to receive from upstream services they call, or deliver to downstream services that call them.
- Autonomy & Control: Each team is responsible for creating and maintaining its own microservices. Since each microservice is its own self-contained app, each team can utilize whatever programming language and app stack best suit their needs (as allowed by the overall enterprise).
- Testability: Because an application is being broken up into separate components that are loosely coupled, testing becomes critical. Luckily, breaking out each component into individual services makes them more easily tested in isolation, and each team can then set up a series of unit tests that the service must pass before any change is accepted and deployed. (This is what is meant by shifting left, as it gives the dev teams more autonomy in testing their specific part of the overall application.) That said, an organization must also focus on integration testing (testing over the entire app workflow across multiple services), not just each individual service separately. Both unit tests and integration tests across all DevOps teams are typically handled by a common Continuous Integration (CI) tool adopted by the enterprise, which builds and tests apps straight from the version control system.
- Flexibility & Scalability: Each team separately deploys and manages their microservices, and can deploy as frequently as needed, entirely separate from other services – as long as they maintain compatibility with the inputs/outputs expected. Like with testing, deployments are typically handled by a common Continuous Delivery (CD) tool adopted by the enterprise, straight from the version control system. And because each service is separately controlled and deployed, each team can scale up or down their microservice based on usage and demand.
Again, microservices tend to magnify all the DevOps workflow's critical needs. Since you are splitting a single application into 100s of pieces, critical tools are emerging to help manage the large number of services being deployed at a much higher frequency than ever before. All the building, testing, and deployment stages can be combined in a single CI/CD tool. Common open-source ones include Jenkins, Travis, and Gitlab, SaaS managed services from CircleCI, Gitlab, and JFrog, and cloud-specific services like AWS CodePipeline. And with this comes the need to monitor these distributed microservices, so services like Datadog and Dynatrace are used for observability over individual microservices, the usage & dependencies between them, and those CI/CD workflows that build, test, and deploy them.
Serverless Functions
Microservices can be further broken down into an even smaller form, by instead creating individual functions per needed action within an application (say, one function to handle the separate create, edit, and delete actions over a customer's address record stored in an underlying database). Think of these as very simplified mini-apps that do one thing (and do it well). But in turn, that turns an application architecture of 100s of microservices into 1000s of functions – further making the architecture more and more complex to deploy, manage, control, and observe.
But what if you no longer have to rely on having an underlying infrastructure to host these functions? AWS created AWS Lambda in late 2014 to provide serverless functions-as-a-service (FaaS). This allows developers to develop these mini-apps in the language of their choice, which are instantiated, run, and destroyed on each request. Because of that, functions must be stateless – they must store any data outside of the FaaS platform (in other persistence services, like AWS S3, Confluent Kafka, or MongoDB Atlas). In addition, cold start time becomes a factor, which is the time it takes these functions to spin up (instantiate on a new request) before they serve a request.
This has all the flexibility of microservices (including choice of programming language), but further simplifies things for developers, since they no longer need to worry about the underlying infrastructure needed to host their code. All major clouds have FaaS capabilities, in AWS Lambda, Azure Functions, and GCP Functions. Enterprises can also use open-source platforms (like Knative, OpenFaaS, Kubeless, or OpenWhisk) to run and manage serverless functions as lightweight containers on their own Kubernetes clusters. But those self-managed solutions become one more piece of infrastructure to be maintained – while it is serverless for the developers using it, it is not serverless for the Ops team setting it up (who are likely using IaC and containers to set up their "serverless" environment).
Conclusion
There have always been many ways to build an application, across different languages, frameworks, app stacks, and environments – either open-source or proprietary, and managed or self-managed. Using cloud infrastructure greatly opens the door to more and more complex architectures, and tool sets have evolved that keep making it easier and easier to manage, secure, and observe your infrastructure, and the app stacks that run upon it.
HashiCorp touched on a lot of these trends in their Tao of HashiCorp, which explains the ethos behind their line of products (and also discussed in this short video from HashiCorp's founders from Jan-19). While this is about HashiCorp's mindset, I feel it overlaps heavily with the development architectures above – which makes me translate their points into being the best practices in modern application development. HashiCorp focuses on:
- Workflows, not technologies (expect the tools to evolve)
- Simple, modular, composable (composable containers and distributed app architectures)
- Communicating sequential processes (distributed app architectures and messaging)
- Immutability (stateless containers and functions)
- Versioning through codification (programmable infra via IaC and containers)
- Automation through codification (modern DevOps workflows enabling automation over it all)
- Resilient systems (achieved via composability & testing)
- Pragmatism (must always adapt with the development trends)
This focus on pragmatism and workflows over technologies is critical. These technologies are constantly changing as SaaS & PaaS services across the cloud evolve, and as new DevOps tools appear. If you decompose and codify your infrastructure & app stack within a repeatable and testable process (a modern DevOps workflow), not only are you more able to deploy and scale those individual layers as needed, but it also becomes easier to experiment with new technologies & advancements, in order to continuously evolve your own tech stack. You can prevent being stuck with a lot of technical debt if you enable yourself to continuously evolve your DevOps workflows – it just requires taking the time upfront to set the best practices now. Adopt programmable infrastructure & apps stacks (IaC and containers) and distributed app architectures (microservices and serverless functions), and then utilize a modern DevOps workflow over it all to automate and test as much as possible.
Add'l Reading
I released a HashiCorp deep dive earlier this year that explains their product line (Consul, Vault, Terraform, et al). Peter Offringa of Software Stack Investing did a GitLab deep dive in July. For a better understanding of DevOps workflows, Technically has helpful pieces explaining DevOps workflows, continuous integration (CI) tools (premium), and what HashiCorp does (premium).
I explore hypergrowth companies within the DevOps, edge network, data & analytics, and cybersecurity. This was originally a post from my premium service from last December. Sign up for Premium if you want weekly insights into hypergrowth tech companies and where they are going in their platforms and market pivots. I currently have in-depth research into observability, DevOps tools, data & analytics, edge networks, and cybersecurity (Zero Trust, SASE, XDR, CNAPP) industries, including heavy coverage of CrowdStrike, SentinelOne, Zscaler, Cloudflare, Snowflake, and Datadog currently.
- muji