
One phrase that shows up in my investment thesis is "picks and shovels". I love investing in building block services used within application development, which can help provide the underlying features within an app. I find these services can be extremely sticky, where the success grows with the success of each of the applications built upon them. But let's dive deeper into modern application development -- specifically, the app stack and infrastructure architectures that underpin today's modern web applications. Don't worry, I don't get overly technical - this is to make you more aware of the expansive ecosystem underpinning both the App Economy (the proliferation of web and mobile apps for B2C and B2B), as well as the API Economy (B2B data inter-exchange). This post is not to dive into specific companies, but is instead laying a technical foundation for several upcoming pieces around the related industries within this ecosystem, including DevOps tooling (such as Observability, Communication, and Data services), Cybersecurity (such as Endpoint Protection, Identity Management, and Zero Trust), and Edge Networks (such as distributed applications using serverless edge compute). All of these industries swirl around application development, so I want to be clear about why these needs exist, and where they fit into the scope of app stack development.
So let's go through it all in a very abbreviated history (I'm not even going to get into languages or frameworks!), just to cover the various ways applications are typically architected, and what infrastructure they require ...
Software architecture evolution
Application development has been around as long as computers have existed. Early computers filled a room, and used punch cards to program in compute logic. Luckily, by the time I was growing up, those days were long gone, and you could program in BASIC on an Apple IIe or Tandy PC at home.
Software tiers
In the age of PCs, applications were installed on-premise or in a company's data center, connected to the corporate network via a WAN. Single-tier apps are entirely self-contained, and don't need to talk to an external server (such as Microsoft Excel or Word, which open & save files locally). Most on-prem business applications used a two-tier (or client-server) architecture, where the server centrally stored and processed the data through an application programmable interface (API), and a separate, locally installed client app contained the user interface (UI). Business logic could be at either layer (client or server app), and was typically intermixed across both – which tended to cause logic sprawl, making it more and more difficult to test & maintain. Today, most business logic is housed in the server-side application code, keeping the client application as lean (and, subsequently, as small and performant) as possible.
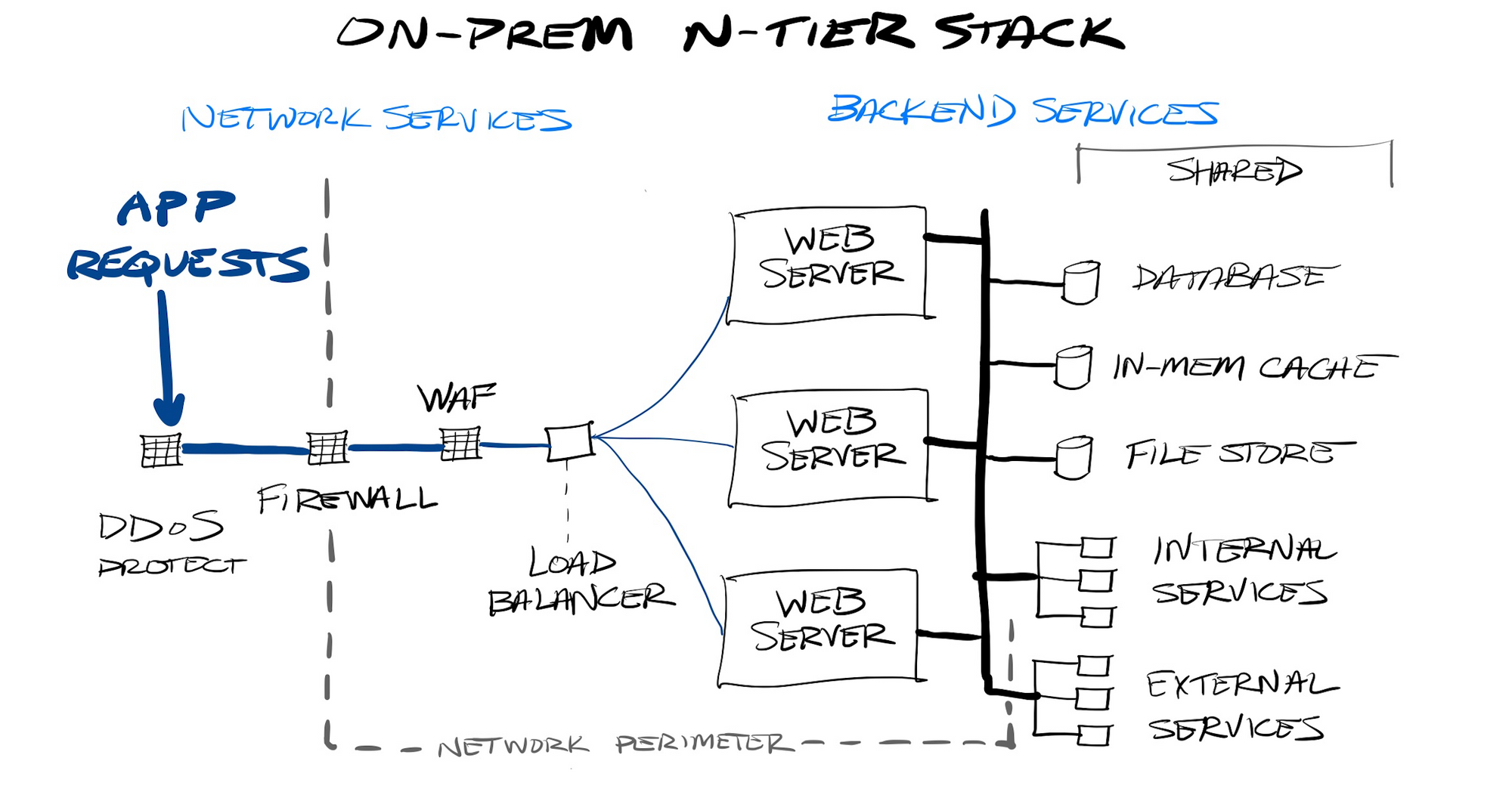
Extending the app stack out further, in a 3-tier (or N-tier) architecture, the back-end would then talk to other internal or 3rd party services, such as a centralized data store. Further exacerbating the division of logic, these databases could house application logic internally as well, such as embedding business logic into stored procedures for handling data-centric logic, such as enforcing business rules, or doing data cleanup or manipulation tasks. As logic sprawls across multiple back-end tiers, again, the more difficult it gets to test and maintain.
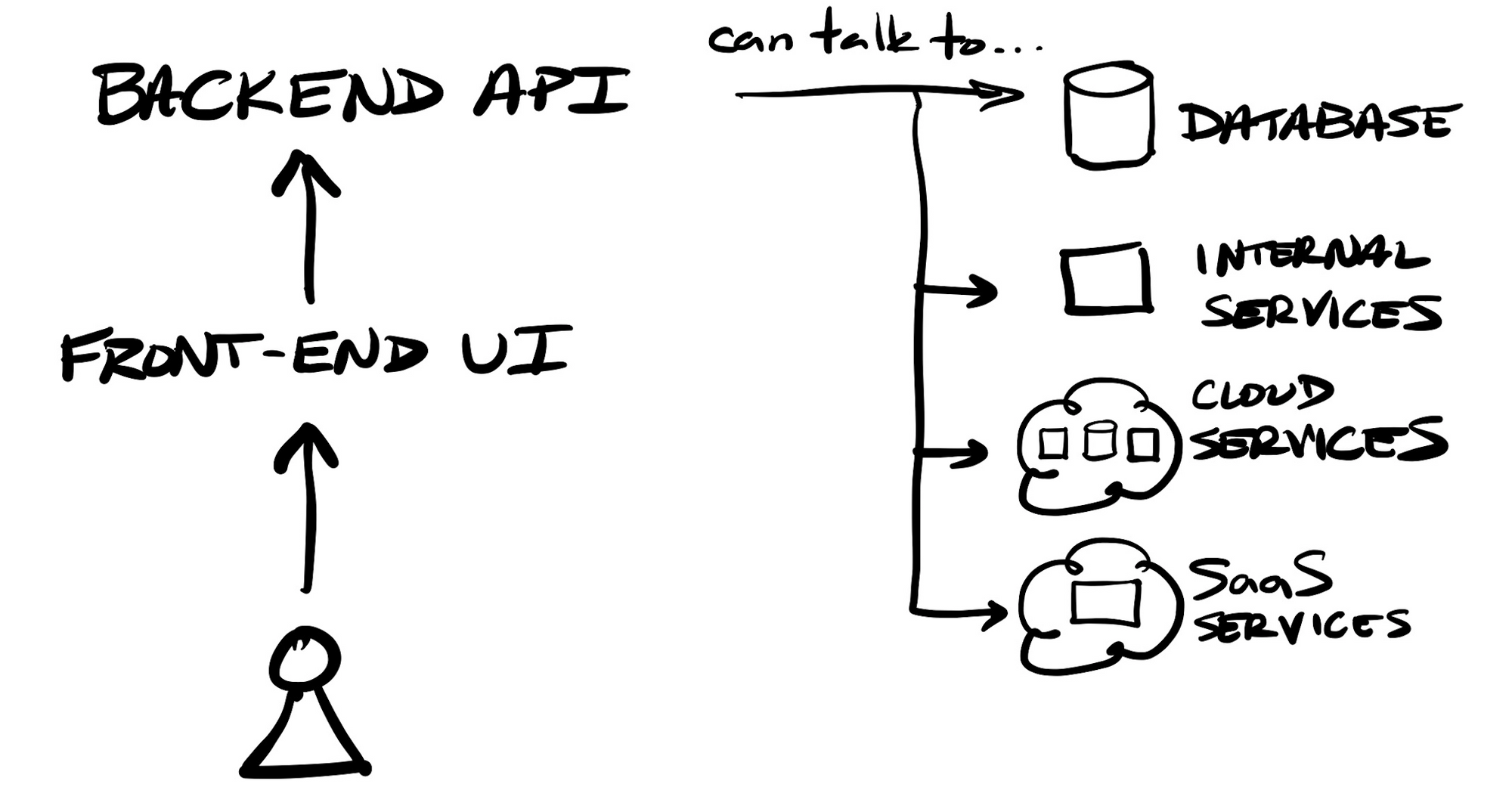
In order to make N-tier applications more modular and scalable, and have the logic contained into services that were more individually testable, the style of service-oriented architecture (SOA) arose. Under an overarching app interface, developers could house a variety of tightly-coupled modules to handle groups of tasks within their application, each of which could be separately tested and deployed. For instance, in an e-commerce app, one service might be one that handles all adding, editing, or removing of items from an order. In order to have services intercommunicate, typically a dedicated messaging system (a service mesh or bus) was utilized.
Moving to the Internet
With the advent of the modern Internet, a server could now be anywhere (globally) as well as the client. I will generally refer to Internet-based apps as web applications, which not only include browser-based web apps, but also locally installed desktop and mobile apps that intercommunicate with a centralized back-end service. Web apps continued to expand upon the N-tier model, but instead of being housed within a protected network (with a secure perimeter, where access can be tightly controlled), either end can be situated anywhere upon the globe.
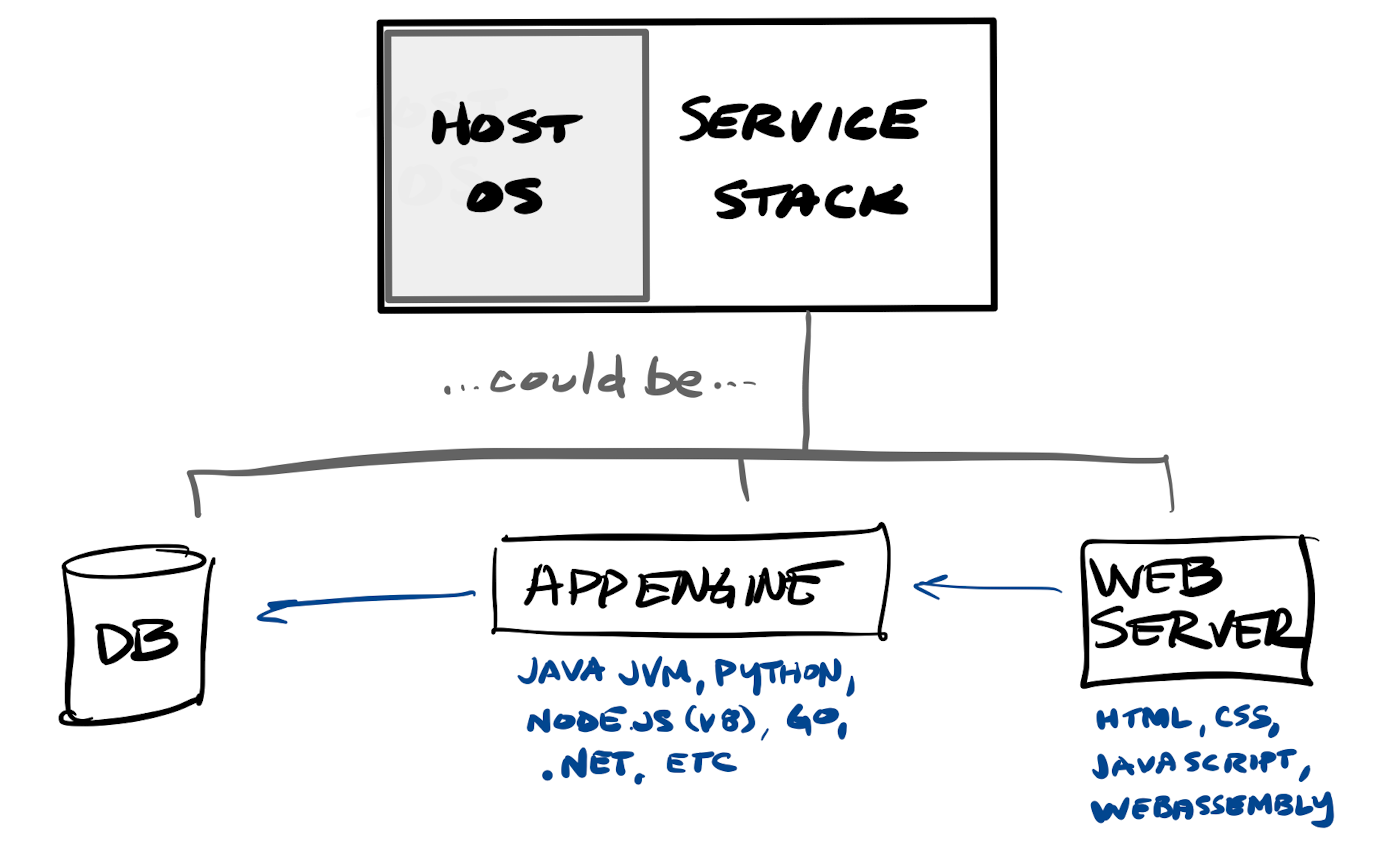
Mimicking the on-premise architectures, when applications migrated to the web, full-stack apps were initially the norm, where the entire application was designed to handle both back-end activities (housing business logic and hooking to other data stores & services utilized) as well as front-end activities (rendering and controlling the UI to display screens and handle user interactions). Like in locally installed apps, these tended to be monolithic apps, where the entire application consisted of one large code base to handle every type of user request and back-end action needed. You typically needed powerful servers to house the various parts of a web application stack, including separate systems to house other internally-hosted services, such as database servers. It was difficult to right-size the underlying hardware needed to run the components of a web application stack, as each server had to be sized large enough to handle some pre-determined peak load.
Full-stack web applications housed both the front-end and back-end. In this scenario, web pages were typically server-side rendered, meaning the entire HTML was generated and sent to the client app. As front-end Javascript frameworks improved, developers eventually found it easier to split up a full-stack application into separate modules, to separate the different concerns & needs between the front- and back-end portions of the app.
The front-end of an application could now be:
- A locally installed app, such as native os app or mobile app (in whatever language & framework), which could either be a standalone app, or a N-tier app that calls an external back-end service (API).
- Full-stack web apps, which are typically multi-page apps, delivering a screen based on the user's request or action, with web pages that are server-side rendered (in whatever language & framework - Python, Java, Go, .NET, Node.js, etc - is installed on the server) and then delivered to the client's browser as fully-rendered HTML. Full-stack apps may act as their own API, or can call a back-end service (database or other API).
- Lean web apps, which are typically now are done as single-page apps, with a framework or library that is downloaded to the client browser to provide features to render each requested screen on demand, as well as to call back-end services in order to retrieve & display pieces of data. This means they are client-side rendered within the browser, via HTML (display templates), CSS (layout, style, & fonts) & Javascript (app & display logic) -- which in turn is used to call some type of back-end service (API).
Today, having a lean web application is the the generally preferred style, as it remains light-weight (small and performant), keeps business logic more centralized (solely handled on back-end), and can take better advantage of modern file distribution through CDN services.
Stateless modularity for scale
A back-end API will typically consist of multiple endpoints, each triggering a separate action. Initially an API might have been stateful, remembering actions across requests. Think of an e-commerce app - you would have separate endpoints for each action a shopper would do, such as adding or removing an item from their cart. These actions would typically be persisted between requests (being a stateful app), such as internally tracking the actions a user took across multiple requests. It has to handle security - authenticating the front-end client or user, and instantiate a user session that would be remembered across requests, and could be timed out if the user stops responding.
Statefulness can ultimately cause multiple issues for developers, particularly impacting an application's ability to scale. The application had to have a lot of memory for internally caching stateful content – so the API might not be able to properly scale as the number of requests climb. And application developers preferred to develop multi-tenant apps, for handling many different customers on one app stack, while keeping each one's information separate from the others. But that must be extremely careful using stateful systems, requiring additional security precautions to assure one user's information is not bleeding through to another user. Making an API stateless greatly helped solve these issues; it helps improve the portability of the code, allows it to better scale with more usage, and makes it more secure in multi-tenant architectures.
REST (REpresentational State Transfer) APIs provided a standard mechanism for web applications to communicate to server-side services. REST APIs are stateless, which allow for each request from a user to be tracked as its own discrete action -- meaning the API is not internally tracking data across requests. Security mechanisms arose to help support this, by maintaining a user's session in the client app after authentication, and passing in that session's credentials on each subsequent request. Other back-end data services (data stores or caches) could be utilized to persist information that needed to be maintained during a session (like a user's shopping cart) or across sessions (like a user's settings), which each call to the stateless API would need to look up as needed. To prune stale information and maintain security, user sessions (along with any related persisted data for that session) could be made to expire after some amount of inactivity.
REST APIs still had the potential to be monolithic applications, where one codebase might house 100s or 1000s of endpoints that an application's users or admins might call. Instead of having all the code in one code base, having a more modular code base, consisting of individual components, can be much easier to code and individually test – but at the cost of being more involved to maintain & build (having to deploy different modular services instead of one monolithic app) and requiring a system for managing the intercommunication between them all. The microservices design pattern arose to help solve this, so that instead of one monolithic API (in one large code base), each discrete action or logic block of that API could be maintained as a completely separate service. So instead of 1 API with 100 endpoints, you might have 100 separate microservices that each handle only the logic of each individual endpoint. This architecture is similar to a service-oriented one, but with a complete de-coupling of individual services, and a completely different underlying intercommunication mechanism. Instead of focusing on direct calls between intertwined services (that are designed to handle groups of related tasks within an application), microservices allowed developers to design an application around an event-driven architecture, where every handler is triggered by the occurrence of an individual event that occurs within the app. In that e-commerce example above, instead of one service in a SOA architecture handling all cart actions, each UI and back-end interaction could instead be broken into specific events, with an individual microservice to handle the workflow needed for each. A user adjusting an e-commerce order in a UI might include events like "cart:add-item", "cart:remove-item", or "cart:adj-item". The app would trigger these events based on a user's actions in the front-end, and pass in the user session and other needed parameters for the stateless service to process the underlying data as necessary.
Like SOA, microservices require intercommunication between themselves in order to control how the workflow moves between them, such as a messaging backbone (known as an event mesh or bus, like what Apache Kafka can provide). They are generally asynchronous (non-blocking, meaning they don't wait for an answer from other microservices) – they are designed to perform all the actions needed to handle a specific event, and are able to trigger other downstream events that might be needed. For example, a checkout action, triggered by a user submitting an order page, might then trigger an event service for payment processing, and upon success of that, trigger another event for generating a final email to the user, and a final event to export the order to the fulfillment system. The smallest form of microservice would be boiling an application down into its individual functions, each controlling a specific user action or interface into outside services.
Regardless of the software architecture utilized across the app stack, some additional services are needed by DevOps team to maintain this growing complexity of code:
- Source-code Repository = on-prem or cloud service to store the source code and track changes in a collaborative environment, such as Github or GitLab.
- Unit/Integration testing = a system for testing each component of an app separately (unit), as well as together, testing each entire workflow across the app (integration). Unit tests are typically performed by the developer, or can be automated.
- Continuous Integration (CI) = on-prem or cloud service for continuously performing integration testing across the entire application, as code is committed.
- Continuous Deployment (CD) = on-prem or cloud service, that integrates with CI tools to assure that after committed code is tested, it performs an autonomous building & deployment of the code to a production environment. Typically combined with CI as a CI/CD tool, like Jenkins, Travis, AWS CodePipeline, and GitLab CI/CD.
Infrastructure evolution
To step back a bit, let's look at the infrastructure needed for application stacks to run upon.
Application stacks typically required purchasing beefy hardware servers to be hosted upon. Beyond that hardware, there were a wide variety of ancillary network services you needed to host web servers or APIs on-premise, such as:
- firewalls, to control access to your network
- web-application firewalls, to control access to your web application
- API protection, to control access to APIs
- load balancers, for spreading requests across multiple instances of a stateless service
- DDoS protection, for absorbing a heavy rate of illegitimate requests
- rate limiting, for throttling a heavy rate of legitimate requests
Initially, these required running dedicated servers for web applications and back-end services, and hardware appliances for all those network protection features. The problem with purchasing dedicated servers was the initial cost to buy and provision it, the difficulty to maintain it (updating them with continual security patches), and the fact you had to buy hardware to handle the peak load – which ultimately meant that the hardware had a lot of idle (unused) capacity.
Virtualization
With hypervisors, you could instead replicate physical servers into virtual servers. Hypervisors allow for sharing physical compute, memory, disk and networking of a single physical server between "virtual machines" (VMs) running on that server. VMs allow for a degree of portability - you can transfer a VM between VM hosts in a cluster, or across dev or hosting environments. It greatly helped with right-sizing hardware, as you could now run multiple loads, with different compute, memory, storage, and network usage, on the same shared hardware.
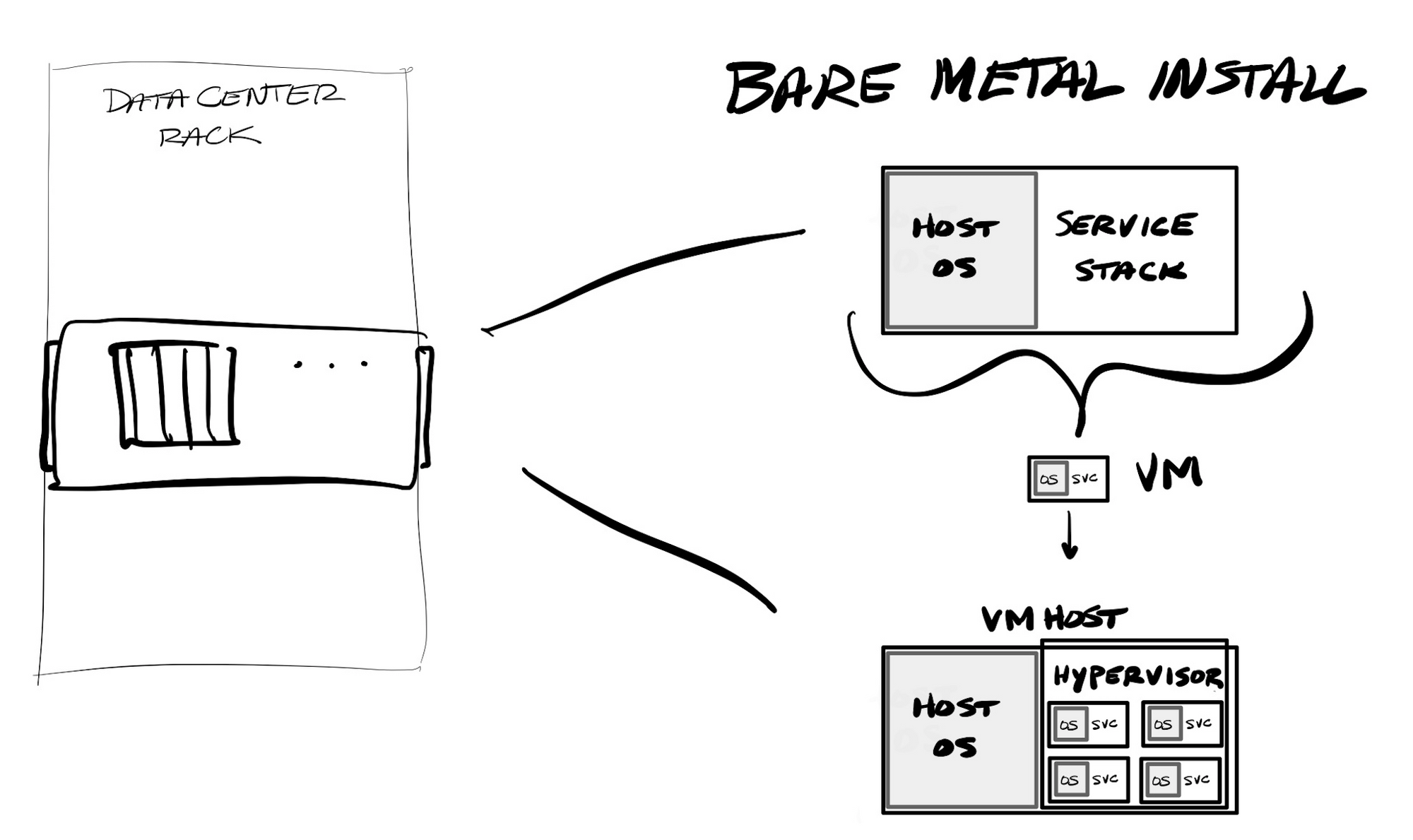
One issue with VMs is that you have to stand up the entire server stack every time, including the underlying operating system (OS). So if you have a VM host running 4 VMs, you are maintaining 5 different operating systems on the same machine (the host systems OS, and the OS within each VM). VM templates could be used to standardize the base setup used when provisioning a new VM, but other systems, like Ansible, Puppet, and Chef, emerged to automate provisioning. These "configuration management systems" allowed for running command line instructions within the base OS, in order to install new packages, update existing ones, change configuration files, and start or stop services. These can be saved and played as a "playbook" or "cookbook", which allow for using procedural code to stand up new bare metal or VM systems, or to maintain and patch existing ones.
However, as your application stack expands into 10s or 100s of VMs (across dev, test, staging and production environments), it remains a complete nightmare for DevOps personnel to maintain & patch the underlying OSes used across each host and VM, and for any of the underlying service stacks installed. Much of the initial setup of an OS can be done once and templated, but ongoing maintenance from there is not possible to template. Installing a new VM requires cloning a template and then typically running an automated playbook that can further configure the underlying OS and then provision the services upon it. Maintaining it from there must again use something like an Ansible playbook, in order to automate the patching or upgrade process as best as possible across a pool of VMs.
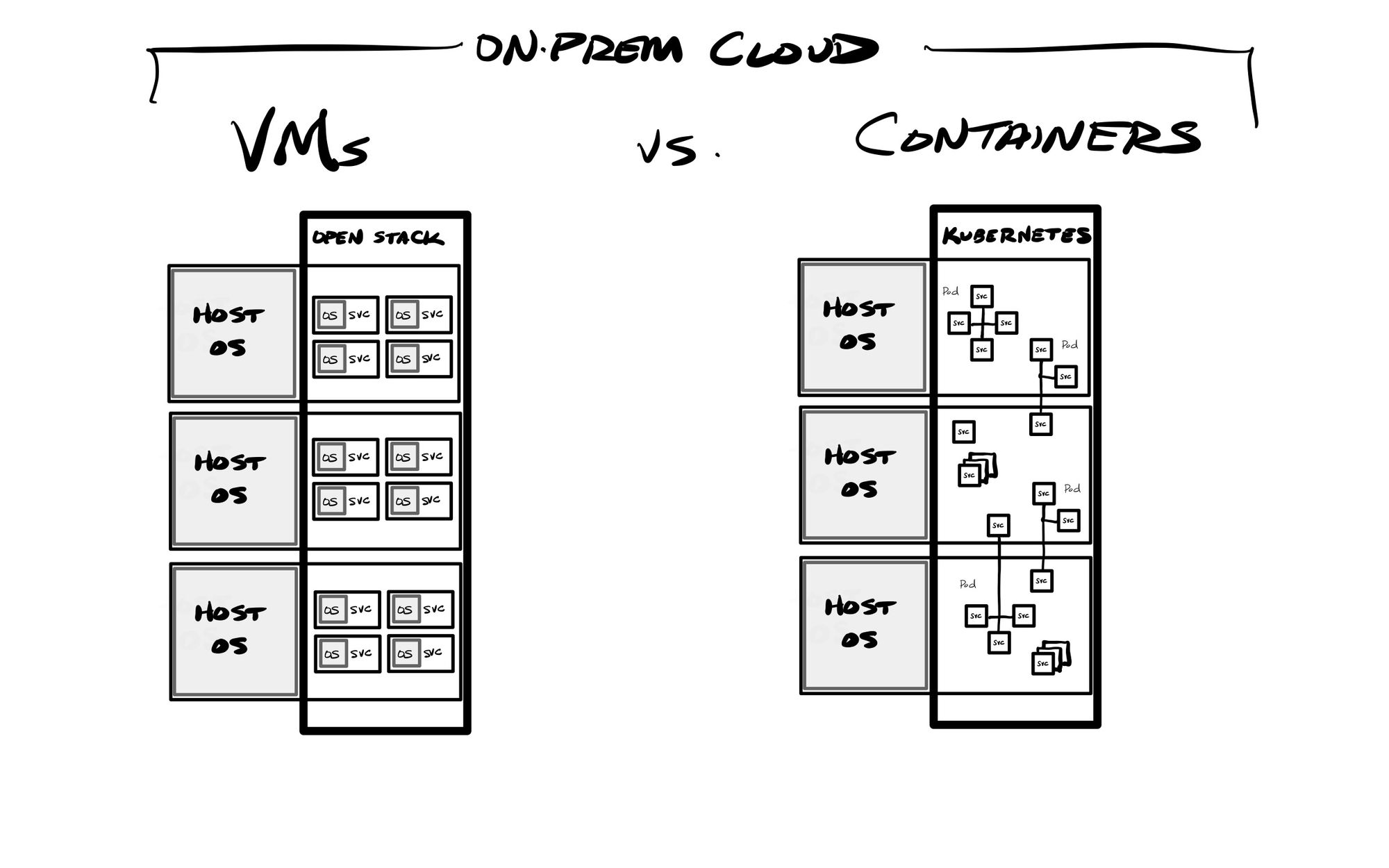
An infrastructure-focused solution that emerged was to utilize a pool of self-managed hardware as an internal cloud, which could host a wide variety of VMs with different storage, network, memory, and compute needs. Redhat OpenStack is one popular platform, which allowed for decoupling the application stack from the underlying infrastructure. But while this greatly helped manage the variety of application environments needed for development (dev, test, staging, and production), unfortunately this architecture does not have enough portability for a developer to easily replicate a VM-based application stack on their laptop, as VMs are typically quite large (in the tens to hundreds of gigabytes).
The Rise of Containerization
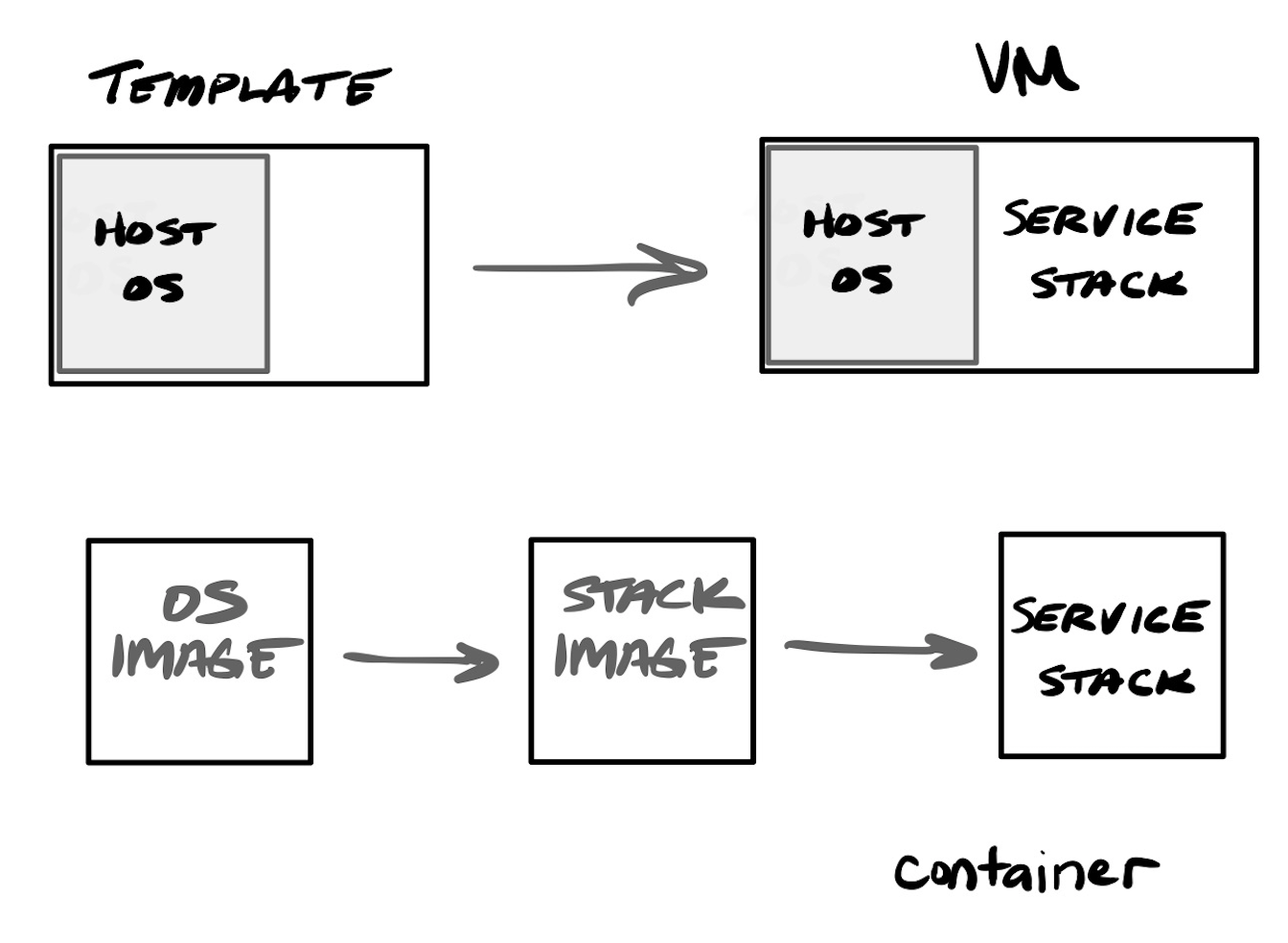
Containerization arose as a better way to solve these issues, and provide better programmability into the process of maintaining infrastructure, and result in more compact virtual systems. When you stand up a new VM, it is like standing up a new bare metal server, requiring installing the base OS, and then all services upon it. Standing up a container is much more programmatic and developer-friendly, with the underlying OS mostly abstracted out of the process via container images (a better, more reusable and expandable form of templating).
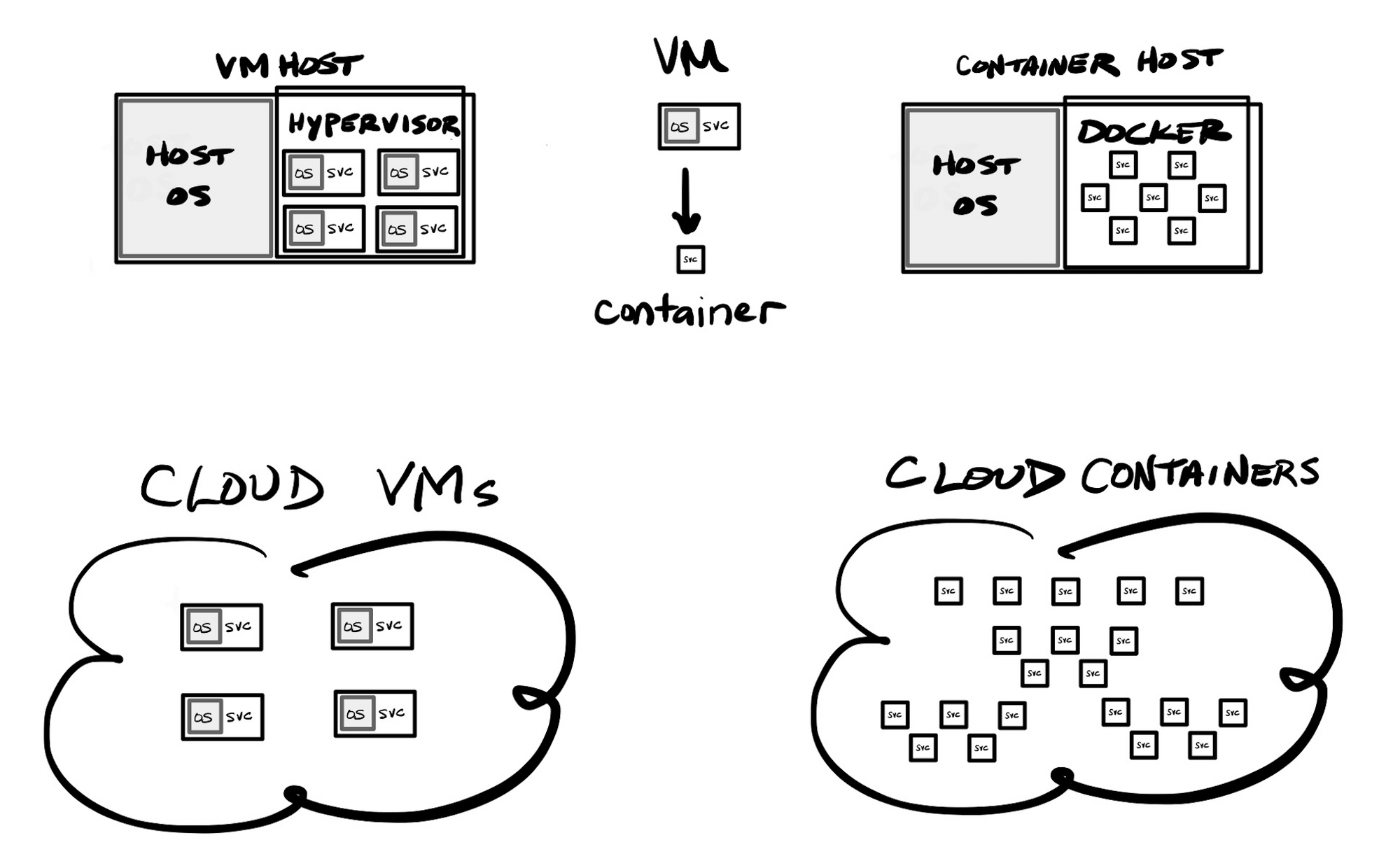
There are many benefits to using containers, from a developer's standpoint. Installing a new container involves cloning an existing image that already has the OS and the underlying service you desire installed upon it, so you typically then only need to configure it. Container systems like Docker still have a "compose" feature that, like Ansible, allow for performing operations on the core OS and installed app stack. Containers are more compact than VMs, typically being much, much smaller (in the hundreds of megabytes to single-digit gigabytes), and are subsequently much more portable. But the real key with containers is that they provide a very repeatable process that every DevOps team member could easily run. Instead of fumbling about with large VMs, plus having to use external systems to then configure the VM, containerized application stacks could be deployed onto a developer's laptop in a matter of minutes – entirely from scratch, pulling in core OS and services in through the utilized image, and then directly installing & building application code directly from a source code repository. Containers help abstract away concerns about the underlying OS, greatly reducing the amount of time needed for provisioning & maintaining the OS and the underlying frameworks needed in your app stack. You no longer need to continuously maintain and patch the underlying OS and services, as new builds of a container would use updated images containing more recently patched OS and services. You will, of course, need to continuously test new containers based on updated images, to assure no breaking changes in your application.
One issue with app infrastructure is again about separation of concerns – it is much easier to maintain and test an application stack if you separate each app and back-end service to its own isolated process, but then need a way for those services to intercommunicate. If you happened to use microservices, and wanted an isolated container for each, you are suddenly having to manage 10s or 100s of separate containers -- one for each microservice, then any other back-end services used like databases, web servers, caches, or a centralized service bus. Instead of maintaining separate containers manually, what was needed was orchestration – a management service to help run and control various containers that need to interoperate.
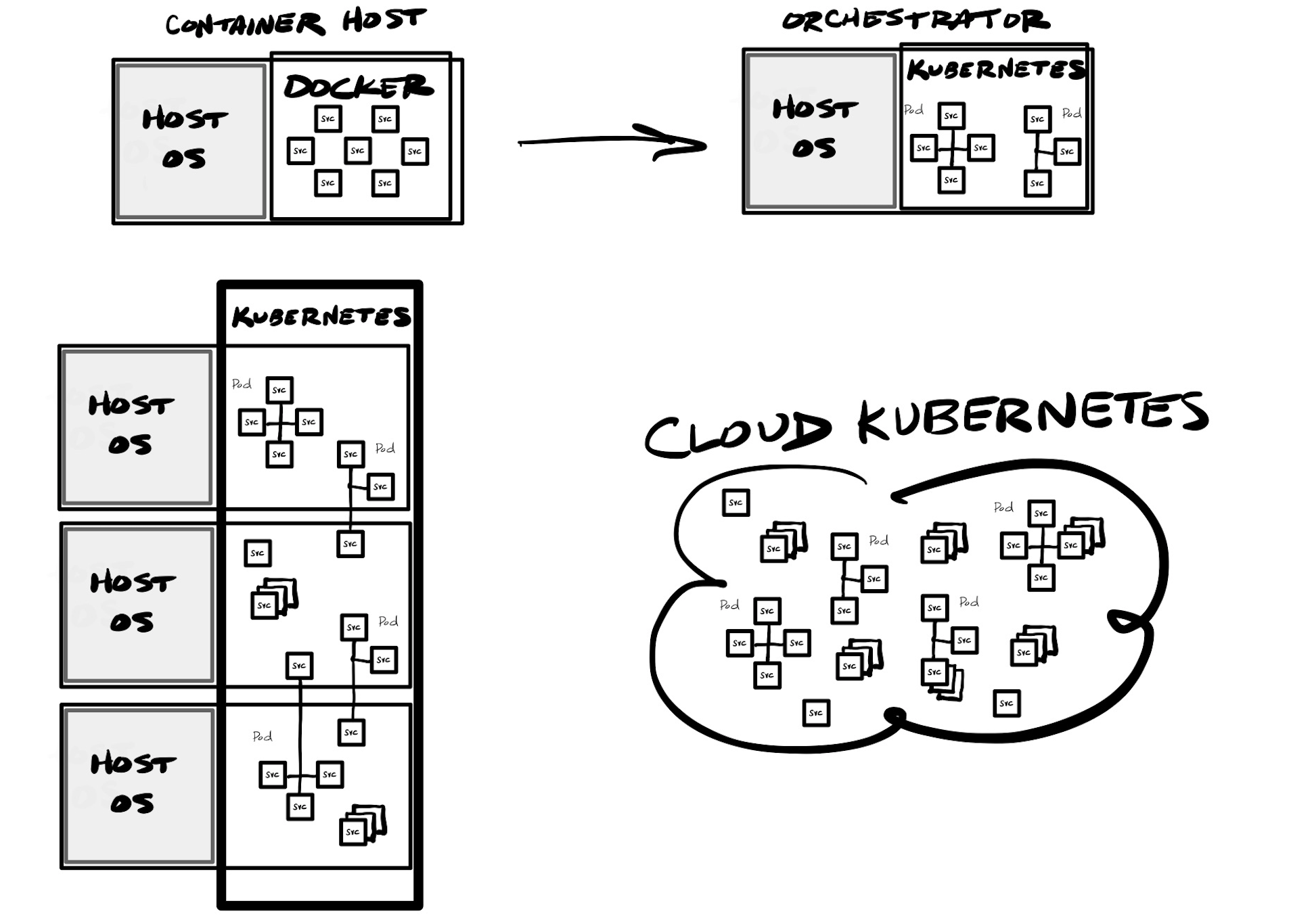
Kubernetes emerged as one of the top container orchestration platforms, as well as Docker Swarm and Redhat OpenShift. These platforms allow for running groups of containers (a pod) together in a secure way, utilizing a private network between inter-connected containers. This allows the orchestration platform to better control access from the outside world via an ingress – the network into the orchestration cluster. In addition, orchestrators can react on-demand to the needs of the app stack and its current usage, so can start up & run containers on demand (ephemeral), as well as modify the app stack dynamically in order to scale it up or down as current usage demands (elasticity). Unlike the traditional N-tier stack, with these capabilities provide dynamic load balancing capabilities can instantly react to the needs of each container or the underlying usage. A container goes down? Another can spin up in its place. A container is suddenly using all its allocated compute or memory? Another can spin up and all new requests be routed to it. Need to update a production container while it is in use? The newly updated one can spin up, will enter the mix through the load balancer, then older containers can be spun down – over and over until the entire production stack is on the new version.
The Cloud Provides All
With the rise of cloud Infrastructure-as-a-Service (IaaS) solutions, you can now utilize VMs on the cloud. At their simplest, cloud vendors are providing the basic primitives of infrastructure, handling all the compute, memory, storage, and networking needs of their customers in centralized locations of their core cloud service. Cloud compute is essentially provided as a VM capability, eliminating the need for bare metal. At a bare minimum, IaaS allows for "lift and shift" – taking on-premise workloads and moving them to the cloud.
Beyond providing the core building blocks for infrastructure, entire platforms are now being built out by cloud vendors or other SaaS providers, called Platform-as-a-Service (PaaS), to provide a completely infrastructure-less app development engine. These provide a serverless method for application development, where DevOps teams no longer need to manage or care about the underlying infrastructure that applications run upon. And in extending out microservices further in PaaS, cloud vendors are providing Function-as-a-Service (FaaS) capabilities, which are serverless microservices that allow developers to boil an API down into single functions that can be called on-demand.
Regardless of the chosen software architecture style, and modularity of an application's stack, an application can utilize a wide variety of other 3rd party & cloud Software-as-a-Service (SaaS) services for embedding other features, such as customer communications (Twilio), payment processing (Stripe), user management & authentication (Okta), or managed data-focused infrastructure (MongoDB, Elastic, Confluent) – including ones from the cloud providers themselves.
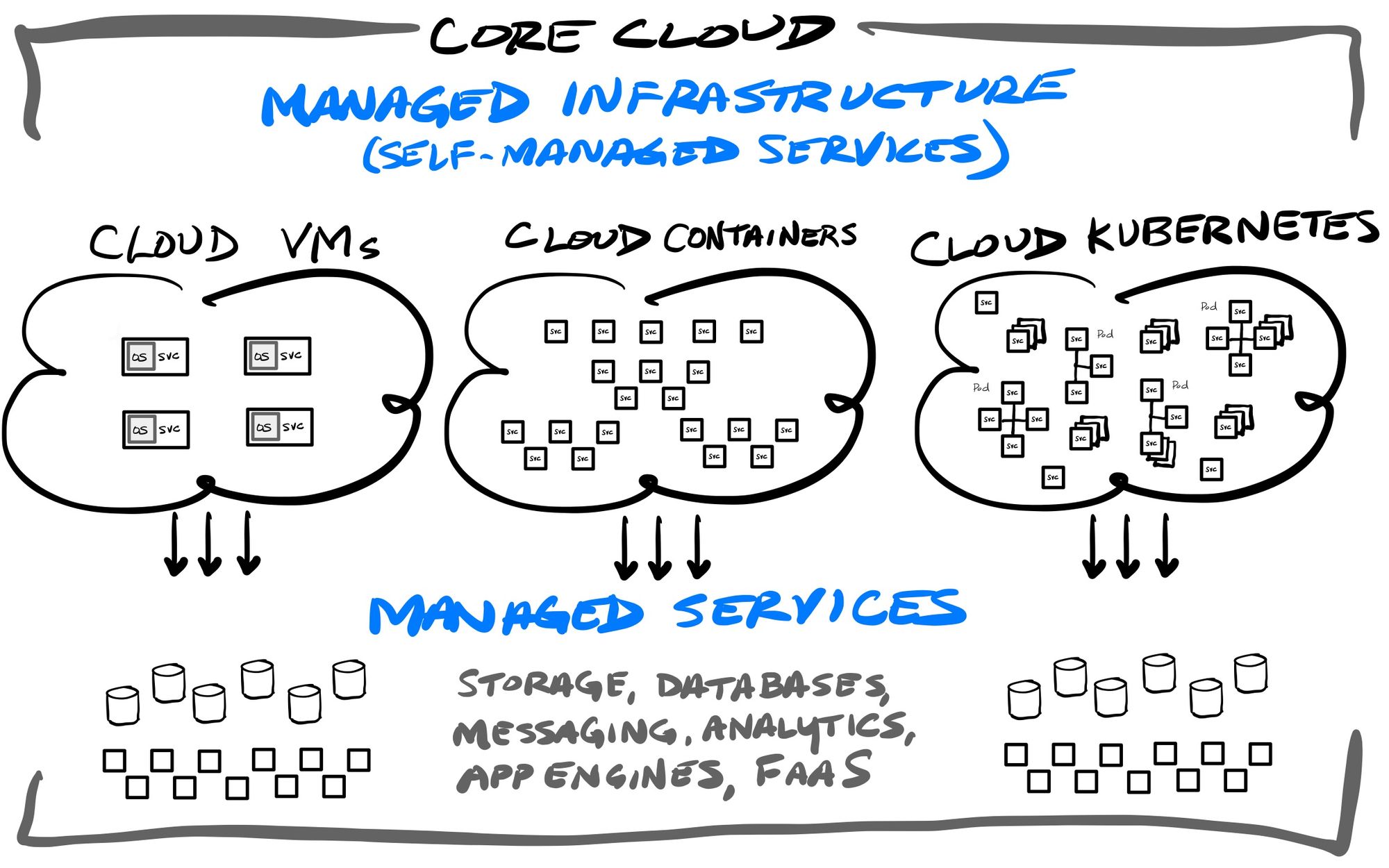
The IaaS services from top 3 cloud vendors cover all of the modern application architectures, by self-managing the underlying cloud infrastructure powering any back-end application:
- VMs: AWS Elastic Compute Cloud (EC2), Azure Virtual Machines, GCP Compute Engine
- Storage: AWS S3, AWS Elastic Block Storage (EBS), Azure Blobs, Azure Data Lake Storage Gen2, GCP Storage
- Managed Containers: AWS Elastic Container Service (ECS), Azure Container Instances, GCP Cloud Run
- Managed Kubernetes: AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), Google Kubernetes Engine (GKE)
- Hybrid & Cross-Cloud Kubernetes: AWS ECS/EKS Anywhere, Azure Arc, Google Anthos
They also have a full range of FaaS/PaaS engines that are providing serverless architectures, which can be used for deploying back-end API and microservices without worrying about the underlying infrastructure:
- Serverless Functions (FaaS) = AWS Lambda, Azure Functions, Google Functions
- Serverless Containers = AWS Fargate, Azure Container Apps, GCP Cloud Run
- Serverless Apps (PaaS) = AWS Elastic Beanstalk, Azure Cloud Services, GCP App Engine, GCP Firebase
They also have a variety of hosted (IaaS) and fully-managed (SaaS) database & streaming services for every occasion:
- Relational = AWS RDS, AWS Aurora, Azure SQL Database, GCP Cloud SQL, GCP Cloudspanner, GCP AlloyDB (new in May-22)
- NoSQL = AWS DynamoDB, AWS DocumentDB, Azure Cosmos, GCP Firestore, GCP Datastore, GCP BigTable
- Caching = AWS ElastiCache, Azure Cache, GCP Memorystore
- Data/event streaming = AWS Kinesis, Azure Event Hubs, GCP Datastream
- Queues/pub-sub = AWS SNS, AWS SQS, Azure Web Pub-sub, GCP Pub-sub
[And a lot more data & streaming directions outside the scope of this post, including BI analytical databases, data lakes, AI/ML engines, and real-time stream processing.]
Putting it all together
Containers can now be ephemerally controlled through orchestration platforms, and can be created and run on demand. While they can run a batch job, or do simple tasks like moving data around or triggering an action, it also enables applications to be reduced to small microservices that can be called upon request, by waiting for an event to trigger it. These services can then process its parameters into some kind of data output in response, trigger an action through an outside API, look up or write or enrich data from a data store or API, and/or trigger yet another service via an event message. For instance, the service could wait for an event to get triggered in an application workflow (say, an event like “order:send_final_confirmation”, with a parameter of the order ID), look up the order info and user metadata, format it into a email based on a configured template over that data, and sent that email to the user via an outside API service, such as Twilio's SendGrid. The app stack could then spin down that service's container, until it again sees that event.
Serverless FaaS services exist for exactly this, where functions can be run as containers and be ephemerally launched as needed, with each function sandboxed apart from each other across a multi-tenant dev environment. Developers are now creating individual functions that can be run as needed, in a stateless, asynchronous, and ephemeral way. Serverless functions provide a method for breaking your formerly monolithic app into finely granular components… each a tiny brick building up into a complete solution (the entire app). Now one monolithic app can be broken into 20… 200… 2000… or even 20,000 functions, based on the app’s complexity.
This ephemeral & dynamic nature of cloud workloads is an important difference over earlier application infrastructure methods like bare metal servers or VMs. Bare metal servers had to be provisioned by planning for peak usage, which meant they typically had a lot of wasted compute, memory and disk space. VMs helped this by allowing for multiple workloads to be able to be run on a single server, allowing one to maximize the compute and memory usage of that hardware. However, the orchestration of containers further improves upon this, by allowing containers to be dynamically controlled, and spun up or down on demand. VMs do not have this flexibility (at least not easily). These factors all combine now with the move towards serverless platforms, and being able to run the entire app stack within managed services on cloud-based infrastructure. Cloud vendors all now provide ways to run these various infrastructure needs in a serverless way, where you are not responsible for the underlying infrastructure it runs upon. While VMs are still heavily used, containers provide the most portability between clouds and on-prem. Beyond providing managed compute and storage (the basics of IaaS), they all are providing managed container and Kubernetes services to run containers without the user needing to worry about the underlying infrastructure in any way, as well as other managed back-end services like storage services, databases, messaging services, and app engines (PaaS). So today, there are many, many ways to deploy your application into the main cloud providers. It all depends on what level of management the DevOps team wants over the underlying infrastructure – you could run containers or orchestration systems like Kubernetes yourself if you want to stand them up on self-managed VM instances.
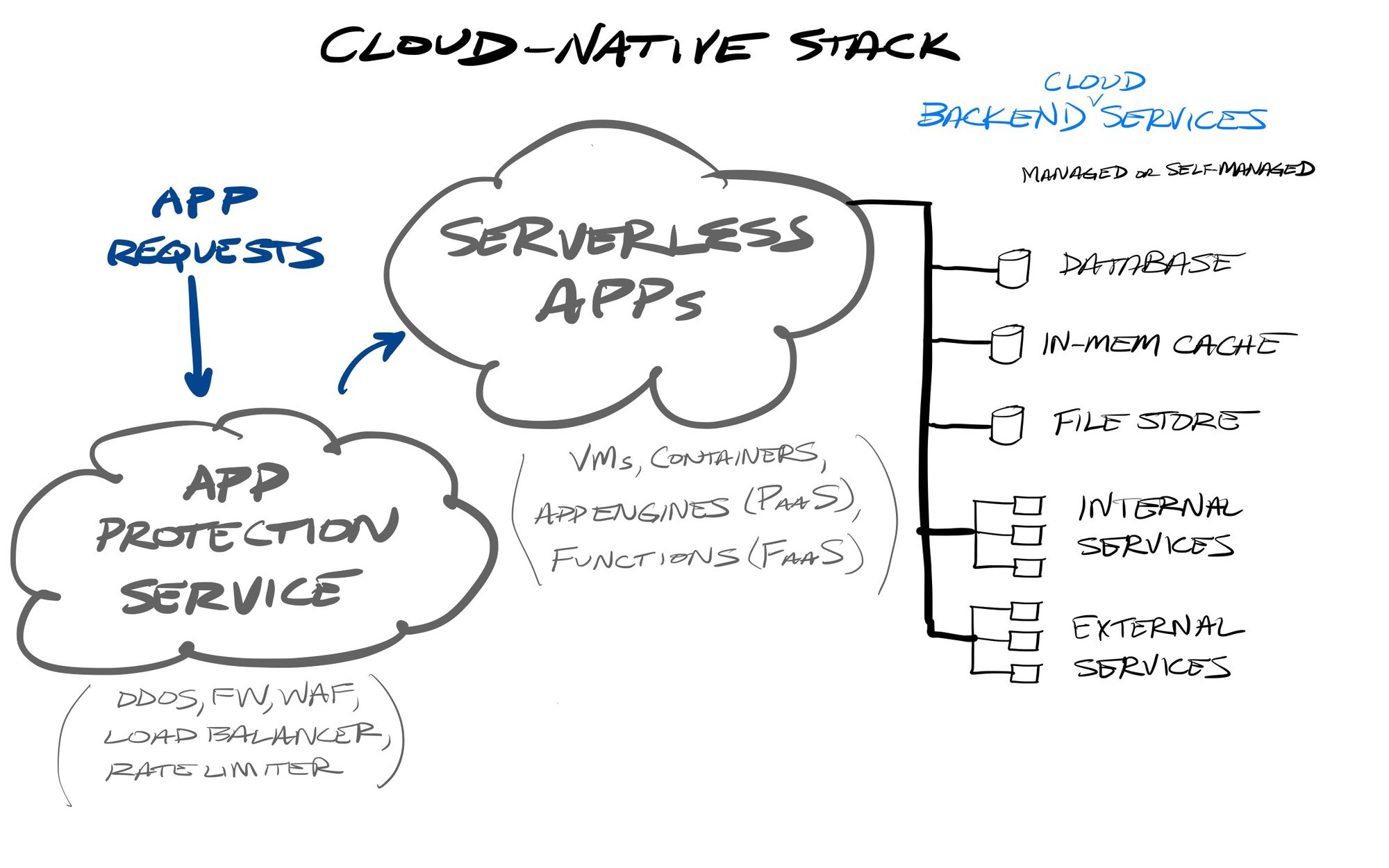
The Next Phase
The following areas of application architecture have my attention from here. [Lots more on these themes in my premium service.]
Programmable app stacks
Containers help abstract away concerns about the OS and core app stacks. Developers can do away with a lot of the existing infrastructure concerns, either on-prem or cloud – especially given the developer-friendly nature of lighter-weight containers, and the dynamic & ephemeral nature of container orchestration. Serverless PaaS and FaaS further abstract away concerns about the underlying infrastructure.
While CI/CD tools were initially built around automation of the application build & deployment process, with containers, you can now build an entire application's stack in a repeatable way, and those same CI/CD tools can now help automate managed infrastructure. Using Infrastructure-as-code platforms (like the open-source Terraform project from HashiCorp), both application AND infrastructure pipelines can now be completely programmable. Combined with container orchestration, you can now completely automate scaling up applications, dynamically expanding or contracting the app stack & the underlying infrastructure as needed.
However, microservices and FaaS are highly complex as the app stack gets more and more distributed. Just like Zero Trust’s level of granularity in user access security (vs castle-and-moat's centralized network access), today's architectures are breaking monolithic apps up into potentially 100s or 1000s of individual components, each coded, deployed, tested, managed, run, and secured apart from the others. The more modular and dispersed an application, the more these features, the more that DevOps teams need to be able to watch and secure the distributed app stacks and the underlying infrastructure that they run upon. This means cloud services are needed in observability (viewing infrastructure and application metrics) and cybersecurity (endpoint protection, user identity management, Zero Trust access).
Cloud-native Application Protection Platforms (CNAPP) are an emerging capability to not only protect app stacks across cloud infrastructure and PaaS in real-time (production environments), but also move security deeper into DevOps workflows. Security teams typically only focus on securing the production environment (the final app stack used by customers), but security can move earlier in the process now, and be embedded into the CI/CD pipelines acting as the backbone for automating DevOps workflows (to build, test, and deploy apps & app stacks across dev environments like test, staging, and production). CI/CDs allow for a programmable workflow, and become a place to integrate CNAPP tools that allow for running VM and container security checks while building programmable app stacks. This is all know as "shift left" – shifting security concerns left into earlier DevOps stages in the flow.
These earlier checks can also include security over the code base itself, to check it with code-scanners. This allows for tracking and monitoring the external resources pulled into app code (like open source and 3rd-party libraries) in order to scan them too, and see if those libraries have any known vulnerabilities. This nested tree of libraries used within your application is known as the "software supply chain", and security platforms are emerging to have visibility and security over all the ingredients in your app. There are some stricter environments that require software to have a "Software Bill of Materials" – akin to it showing that ingredient list on the back.
Edge-native capabilities
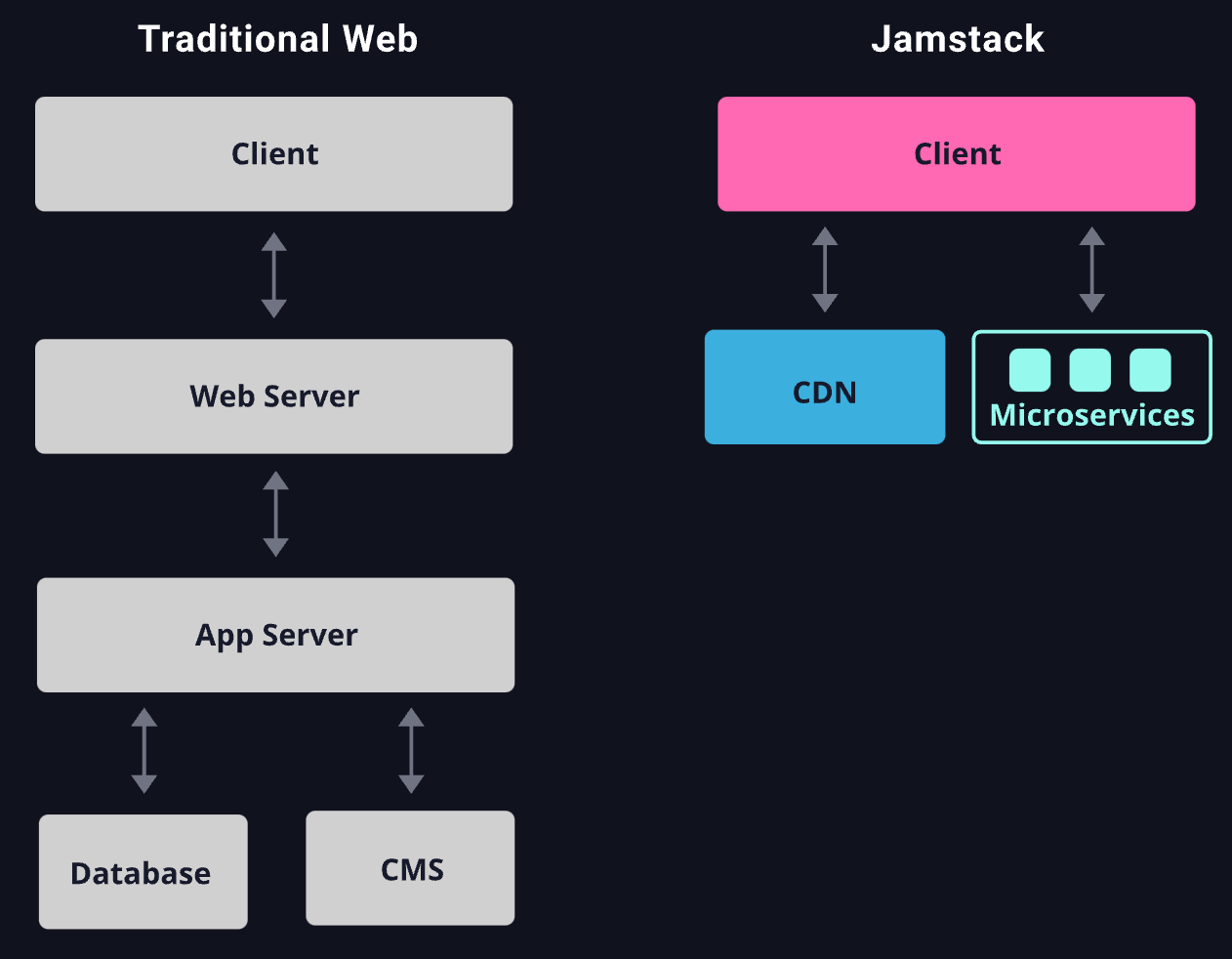
Add to all that how edge networks are changing how applications can be accessed and dispersed globally. Edge networks are adding serverless function capabilities, allowing for microservices and serverless app architectures to migrate to the edge, spreading an app's components around around the globe. Apps can now be placed extremely close to the globally dispersed users and devices accessing them. This greatly lowers the latency of the app, but only exacerbates the complexity of running a distributed app architecture further. Observability and security must be directly factored into the edge network to help mitigate this. Web apps can be extended by offloading compute to the edge – which allows for making dumb devices smart. Plus, all new paradigms for front-end app architectures are emerging at the edge, like JAMstack, which distributes lean web apps that talk to those distributed edge apps.
Add'l Reading
This was originally a post from my premium service written over a year ago. Sign up for Premium if you want weekly insights into hypergrowth tech companies and where they are going in their platforms and market pivots. I currently have in-depth research into observability, DevOps tools, data & analytics, edge networks, and cybersecurity (Zero Trust, SASE, XDR, CNAPP) industries, including heavy coverage of CrowdStrike, SentinelOne, Zscaler, Cloudflare, Snowflake, and Datadog currently. Recently I have been discussing XDR platforms, the Federal moves into Zero Trust, where the cloud providers (AWS, Azure, GCP) are moving in security and data capabilities, and thoughts on new product announcements out of Snowflake Summit.
If you want to catch up on other free content from this past year, here is a sample:
- A HashiCorp deep dive
- What is XDR?
- A Bill.com deep dive
- The trends in network security
- A Zscaler platform dive
- A Kafka deep dive
- muji